Claude 4.5 vs Gemini 3 Pro: A Comprehensive Coding Showdown

Claude 4.5 leads in practical coding while Gemini 3 Pro excels in knowledge reasoning—a technical draw.
Based on five major benchmarks—ARC-AGI-V2, SWE-Bench, Terminal Bench 2.0, GPQA, and MMLU—Claude 4.5 leads Gemini 3 Pro by approximately 5 percentage points across three practical coding tests, demonstrating stronger abstract reasoning, bug fixing, and system interaction capabilities. Meanwhile, Gemini 3 Pro surpasses Claude in GPQA professional reasoning and MMLU general knowledge tests. The final verdict is a technical draw, and developers should flexibly choose tools based on task scenarios.
Introduction: The Ultimate Showdown in AI Programming
As competition among AI large language models intensifies, coding ability has become the core battleground for measuring model capabilities. Recently, Claude Opus 4.5 and Gemini 3 Pro went head-to-head across multiple authoritative benchmarks, and the results are quite intriguing—this isn't a one-sided blowout, but rather a technical chess match where each side has its strengths.
This article provides an in-depth analysis of both models' real-world performance across two dimensions—practical coding and knowledge reasoning—based on data from five major benchmarks: ARC-AGI-V2, SWE-Bench, Terminal Bench 2.0, GPQA, and MMLU.
Evaluation Framework: Five Benchmarks for Comprehensive Assessment
This showdown employs five highly representative benchmarks covering the full capability spectrum from abstract reasoning to real-world debugging. Understanding the design logic behind these tests is essential for interpreting the results.
- ARC-AGI-V2: Tests "fluid intelligence" when facing entirely novel problems—like asking a programmer to design an API they've never seen before from scratch
- SWE-Bench: The ability to locate and fix bugs in real open-source projects—essentially a "Bug Hunting Challenge"
- Terminal Bench 2.0: The ultimate test of system interaction and script writing
- GPQA: The ability to answer graduate-level professional questions
- MMLU: A general knowledge breadth test spanning 57 subjects
The design philosophy behind this evaluation framework deserves recognition: it doesn't just focus on whether a model "can write code," but also examines its comprehensive performance in real development scenarios.
Claude 4.5 in Practical Coding: Leading Across Three Tests
ARC-AGI-V2: The Battle of Abstract Reasoning
ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) was proposed by AI safety researcher François Chollet in 2019. Its original purpose was to measure a machine's "fluid intelligence"—the ability to reason and generalize when facing entirely novel problems without prior knowledge. Unlike traditional benchmarks, ARC-AGI deliberately avoids patterns that can be solved by memorizing training data; each problem requires the model to induce abstract rules from a few examples and apply them. The V2 version further increases combinatorial complexity and visual-spatial reasoning difficulty, making it one of the hardest benchmarks to "game." Notably, humans score approximately 85% on average on this test, while top AI models have long hovered in the 30%-60% range—a gap that reveals significant bottlenecks in current large models' true ability to "learn from one example and apply to many."
In this fluid intelligence test, Claude 4.5 took the first round with a lead of over 6 percentage points. This gap is quite significant in AI benchmarks, meaning that when facing completely unfamiliar programming challenges, Claude demonstrated stronger creative problem-solving abilities.

The practical significance of this capability is clear: when developers need to design entirely new system architectures or solve unprecedented technical problems, Claude may provide more innovative solutions. For technical teams that frequently need to build "from 0 to 1," this advantage is particularly crucial.
SWE-Bench Practical Evaluation: Real-World Bug Fix Efficiency
SWE-Bench (Software Engineering Benchmark) was released by a Princeton University research team in 2023. Its core innovation lies in upgrading the evaluation scenario from "write a piece of code" to "solve a GitHub Issue in a real open-source project." The test set draws thousands of real bug reports from mainstream Python open-source projects like Django, Flask, NumPy, and Scikit-learn, requiring models to locate the root cause within the full codebase context and generate patches that pass unit tests. This design means models cannot rely on isolated code snippet generation abilities—they must possess comprehensive engineering skills including codebase navigation, cross-file dependency understanding, and regression testing awareness. The industry widely regards SWE-Bench Verified (the human-verified subset) as a key indicator of whether AI "can truly replace junior engineers."
In this real-project bug-fixing test, Claude once again led by approximately 4.7 percentage points. On the surface, a 5% gap might seem small, but in actual development scenarios, this means that for every 20 bugs fixed, Claude successfully resolves one more than its competitor.
Over time, this directly translates into improved development efficiency—less overtime debugging, faster project delivery. For developers who work with code every day, this is a very tangible productivity difference.
Terminal Bench 2.0: Hard Skills in System Interaction and Operations
Terminal Bench 2.0 focuses on evaluating AI models' ability to complete system-level tasks in real terminal environments, covering scenarios such as Shell scripting, process management, file system operations, network configuration, package management, and multi-step automation workflows. Unlike pure code generation tests, this benchmark requires models to execute multiple commands consecutively in an interactive environment with state persistence and dynamically adjust subsequent strategies based on intermediate outputs. This "perceive-decide-execute" closed-loop capability is critical for DevOps, CI/CD pipeline construction, and cloud infrastructure management. With the rise of AI Agents and automated operations tools, Terminal Bench 2.0's evaluation dimension is evolving from "can it write the correct command" to "can it complete end-to-end tasks in complex system environments."
In command-line task handling, Claude's success rate was 5.1% higher. This means that in operations scenarios like application deployment and server management, scripts generated by Claude have a lower error probability.
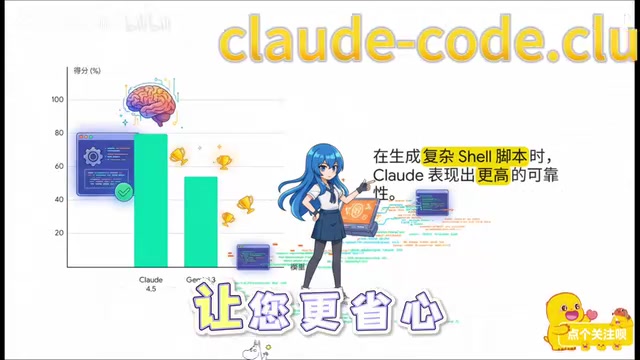
Looking at the three practical coding tests combined, Claude 4.5 has established a stable lead in core software engineering tasks, averaging approximately 5 percentage points ahead. This isn't random fluctuation—it's a systematic capability difference.
Gemini 3 Pro's Knowledge Reasoning Counterattack: Dual Advantages in Academics and Breadth
GPQA Evaluation: Academic Reasoning with Professional Depth
GPQA (Graduate-Level Google-Proof Q&A) was designed by a New York University research team. The "Google-Proof" in its name reveals the test's core ambition: the questions are so difficult that even with access to search engines, non-experts achieve only about 34% accuracy, while domain experts average around 65%. The test covers cutting-edge professional questions in natural sciences including biology, chemistry, and physics, with each question undergoing multiple rounds of review and verification by PhD-level experts. GPQA's design philosophy lies in distinguishing "retrieval-based knowledge" from "reasoning-based understanding"—the former can be acquired through large-scale pretraining, while the latter requires models to truly internalize the underlying logic of a discipline and perform multi-step inference.
However, the match is far from over. Entering the knowledge integration domain, Gemini 3 Pro launched a powerful counterattack. In the GPQA graduate-level professional question test, Gemini scored nearly 5 percentage points higher. Gemini's lead in this test reflects, to some extent, its training optimization focus on scientific reasoning chain construction—when tasks involve deep academic research and professional reasoning, Gemini acts like an experienced scholar, handling complex professional knowledge problems more accurately.
MMLU Test: Comprehensive Knowledge Breadth Coverage

MMLU (Massive Multitask Language Understanding) was released by UC Berkeley in 2020 and contains approximately 15,000 multiple-choice questions from 57 subjects, covering nearly all major knowledge domains including mathematics, law, medicine, history, and computer science. It was once the "gold standard" for measuring the comprehensive knowledge level of large language models, driving the entire industry's systematic attention to model knowledge breadth. It's worth noting that as top models' scores have generally exceeded 90%, MMLU's discriminative power is declining. Some researchers point out that its multiple-choice format has "option bias" issues, and high scores may partially result from training data contamination. Nevertheless, MMLU still holds reference value in horizontal comparisons, especially in evaluating the balance of model knowledge coverage.
In this general knowledge test spanning 57 subjects, Gemini maintained its lead. While the gap isn't large, it once again proves that in terms of knowledge breadth and depth, Gemini remains a formidable "knowledge base." Gemini's sustained lead in this test is closely related to its broad coverage strategy in multimodal training data.
These two tests reveal an important fact: Gemini's advantages in knowledge-intensive tasks cannot be ignored. When you need a model to serve as an "encyclopedia" or "academic advisor," Gemini delivers more reliably.
Final Verdict: Selection Strategy Behind a Technical Draw

Based on the combined results of all five tests, the final verdict for this showdown is a technical draw—neither side was completely knocked out, and both established advantages in their respective areas of strength.
Claude 4.5 vs Gemini 3 Pro: Practical Selection Guide
Based on the test data, a clear selection strategy emerges:
Choose Claude 4.5 for:
- Daily coding and debugging work
- New projects requiring innovative solutions
- System deployment and operations scripting
- Bug location and fixing in large codebases
Choose Gemini 3 Pro for:
- Deep academic research and professional analysis
- Summarizing and synthesizing massive documentation
- Cross-disciplinary knowledge queries and reasoning
- Tasks requiring extensive background knowledge support
Deeper Reflections: Building the Ultimate AI Programming Toolkit
The biggest takeaway from this showdown is that choosing AI tools has shifted from "finding the single best one" to "building the strongest toolkit."
For core software development work—coding, debugging, and abstract reasoning—Claude 4.5 has indeed taken a temporary lead. But in knowledge integration and professional reasoning, Gemini 3 Pro still holds the advantage. The real winners are developers who know how to flexibly switch tools based on different task scenarios.
Of course, in the rapidly changing competitive landscape of AI, today's lead could quickly be matched or even surpassed. Both models are iterating rapidly, and the next "championship bout" may not be far off. Staying informed and continuously learning is the best strategy for navigating this era.
Key Takeaways
- Claude 4.5 leads Gemini by approximately 5 percentage points across all three practical coding tests (ARC-AGI-V2, SWE-Bench, Terminal Bench 2.0), showing a clear advantage in core software engineering tasks
- Gemini 3 Pro counterattacks in knowledge integration, leading by nearly 5 percentage points in the GPQA professional reasoning test and maintaining its lead in the MMLU general knowledge test
- The final verdict is a technical draw: Claude excels at coding, debugging, and creative problem-solving, while Gemini excels at deep academic research and cross-disciplinary knowledge reasoning
- Practical selection strategy: Choose Claude for coding tasks, Gemini for knowledge research—the key is flexibly matching tools to task scenarios
- The competitive landscape of AI programming tools is still rapidly evolving; developers should focus on building a diversified AI toolkit rather than betting on a single model
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.