Claude 4实测:Opus 4与Sonnet 4深度评测对比
Claude 4系列模型实测:编程、文档分析、推理等多维度表现评估
Anthropic发布Claude Opus 4和Sonnet 4两款模型,均为支持快速响应与深度推理切换的混合模型,具备百万token上下文窗口、扩展思考和Web搜索等核心升级。实测显示,Opus 4在180页文档精准信息提取方面表现优异,但在复杂自定义规则的编程任务(如修改版国际象棋)中仍存在逻辑缺陷,反映出当前大模型在边界情况处理上的普遍局限。
Anthropic终于发布了Claude 4系列模型——距离Claude 3发布已经过去了一年多。此次更新带来了两款重磅产品:定位旗舰的Claude Opus 4和主打性价比的Claude Sonnet 4。本文将通过编程、文档分析、数据可视化、推理和AI Agent等多个维度的实测,带你全面了解这两款模型的真实表现,并与GPT-4o、Gemini 2.5 Pro等主流竞品进行横向对比。
Claude 4系列:产品定位与核心升级
Claude大语言模型家族一直分为三个级别:Haiku(轻量)、Sonnet(均衡)和Opus(旗舰)。此前,Claude 3.5和3.7 Sonnet几乎是开发者构建应用的标准选择。而这次发布的Opus 4是自Opus 3以来的首次重大更新,Anthropic官方宣称它是"世界上最好的编程模型",尤其擅长长时间运行的任务和Agent工作流。
Sonnet 4则是对3.7版本的显著升级,在编程和推理能力上均有提升,同时能更精确地响应用户指令。两款模型都被定义为**"混合模型"(Hybrid Models)**——这一概念的核心在于将"快速响应模式"与"深度推理模式"整合在同一模型架构中,用户可以根据任务复杂度动态切换。这类似于诺贝尔经济学奖得主丹尼尔·卡尼曼提出的"系统1/系统2"思维框架:系统1负责快速直觉反应,系统2负责慢速深度分析。在AI领域,OpenAI的o系列模型(如o1、o3)率先将"思维链推理"(Chain-of-Thought Reasoning)产品化,Anthropic的Extended Thinking本质上是同类技术路线——让模型在给出最终答案前,先在内部生成一段可见的"草稿推理过程",能显著提升复杂数学、逻辑和编程任务的准确率。
值得关注的几个核心更新:
- 扩展思考(Extended Thinking):两款模型都支持结合Web搜索的深度思考
- 百万级上下文窗口:支持100万token的超长上下文输入
- Claude Code正式发布:面向开发者的编程工具全面可用
- Web搜索默认开启:此前Claude长期缺失的联网搜索功能终于补齐
关于百万token上下文窗口,有必要直观理解这个数字的量级:1个英文单词约等于1.3个token,100万token大约相当于75万个英文单词,即约1500页标准文档。这一能力的技术难点在于"注意力机制"(Attention Mechanism)的计算复杂度——传统Transformer架构的注意力计算量随上下文长度呈平方级增长,处理超长文本的计算成本极高。Google通过其Gemini系列率先将百万级上下文商业化,Anthropic此次跟进。值得注意的是,超长上下文并不意味着模型能均匀关注所有内容——研究表明,大多数模型存在"迷失在中间"(Lost in the Middle)的现象,即对文档开头和结尾的信息提取准确率远高于中间部分。
在基准测试方面,Opus 4在软件工程领域击败了包括Gemini 2.5 Pro在内的所有模型。在研究生级推理和Agent工具使用等类别中也基本处于领先地位,不过Gemini 2.5 Pro在部分项目上与之非常接近。
编程实测:国际象棋游戏的挑战
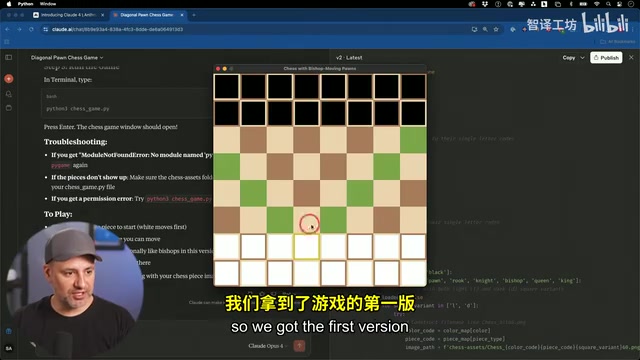
测试者选择了一个此前没有任何模型能完全通过的编程挑战:用Python创建一个修改版国际象棋游戏,其中棋子(pawn)不仅能直走,还能像主教(bishop)一样斜走。测试者同时提供了本地的棋子图片素材文件夹。
Opus 4迅速生成了完整的游戏代码,速度与之前版本相当。当测试者补充提供棋子文件名的截图后,模型展现了一个令人印象深刻的特性:它不会从头重写代码,而是精准地删除和修改需要变更的部分,这在实际开发中能节省大量时间。
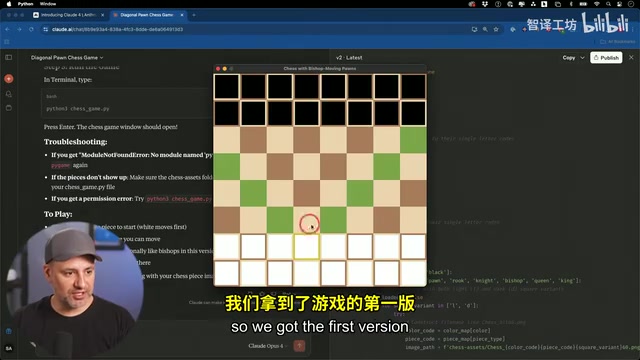
然而,游戏运行后出现了问题。虽然棋子图片最终成功加载,部分棋子也能按照修改后的规则移动,但在几步操作后,棋子的移动逻辑出现了故障——某些棋子无法移动,最终整个游戏的移动系统崩溃。测试者坦言,这与之前其他模型遇到的问题如出一辙:模型能创建标准象棋游戏,能渲染棋子,但在处理自定义规则的逻辑时仍然存在缺陷。
这个结果说明,尽管Opus 4在编程基准测试中表现亮眼,但面对需要深层逻辑推理的复杂编程任务,仍有提升空间。这也揭示了当前大模型编程能力的一个普遍局限:模型擅长生成符合常见模式的代码,但对于需要从零构建全新逻辑体系的任务(如自定义游戏规则),其"统计预测"的本质会导致边界情况处理失误。
文档分析:180页年报中的"大海捞针"
接下来的测试充分发挥了Opus 4的百万token上下文窗口优势。测试者上传了NVIDIA 2025年年度报告(180页PDF,压缩后30MB以内),然后要求模型在这份海量文档中找到特定董事的薪酬信息——这个数据位于第53页。
Opus 4准确找到了Robert的薪酬数据:现金85美元,总计343,828美元。经过与原文核对,数字完全正确。测试者指出,很多他测试过的模型在这类"大海捞针"任务中表现不佳,要么找不到信息,要么产生幻觉给出错误数字。
关于幻觉(Hallucination)风险,这是理解大语言模型局限性的关键概念。幻觉指模型生成看似合理但实际上不准确或完全虚构的内容,其根源在于LLM的工作机制:模型本质上是基于统计概率预测下一个token,而非从知识库中"检索"事实。在文档分析场景中,幻觉尤为危险——模型可能"记忆"训练数据中的相似数字,而非真正从上传文档中提取。Anthropic在训练Claude时特别强调"诚实性
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。