CLAUDE.md 加载机制详解:层级叠加规则与编写方法

CLAUDE.md是Claude Code的持久化系统提示词,支持多层级叠加加载。
CLAUDE.md是给Claude Code看的"使用说明书",本质是持久化系统提示词机制。它采用向上遍历策略加载:从当前目录向父目录逐级查找并叠加规则,子目录规则不会覆盖父目录而是叠加生效。编写建议包括文件名必须大写、控制在500字以内、善用层级叠加、可用/init指令自动生成。
很多人刚接触 Claude Code 时,以为 CLAUDE.md 就是随便写几句规则的配置文件。但实际上,它会根据你在哪个目录启动 Claude Code,加载不同层级的规则。本文通过一个简单的实验,彻底讲清楚 CLAUDE.md 的本质、路径加载逻辑以及新手该如何编写它。
CLAUDE.md 到底是什么?
简单来说,CLAUDE.md 是一份「使用说明书」——但不是给人看的,而是给 Claude Code 看的。
如果把 Claude Code 比作一个新来的同事,那 CLAUDE.md 就像一份员工守则。你写进去的内容,Claude Code 每次打开项目时会先读一遍,然后尽量按照里面的规则来干活。

比如你可以写「回复一律用简体中文」,那它之后在这个项目中的所有回复都会遵循这条规则。
从技术本质来看,CLAUDE.md 是一种持久化系统提示词(Persistent System Prompt)机制。在大语言模型的工作原理中,系统提示词是在正式对话开始前注入给模型的背景指令,用于设定模型的角色、行为边界和输出格式。通常这类指令需要每次对话手动输入,而 CLAUDE.md 将这一过程自动化——Claude Code 在启动时会自动将文件内容注入到上下文的最前端,相当于每次都帮你「预填」了一段系统指令。这也解释了为什么它能持续影响整个项目会话的行为,而不需要用户反复声明规则。
有一个需要特别注意的细节:文件名中的 CLAUDE 必须全部大写,否则可能出现读取不到的情况。这是很多新手容易踩的坑。
CLAUDE.md 不同路径下的加载规则:层级叠加实验
这是本文的核心部分。为了搞清楚 CLAUDE.md 在不同路径下的加载逻辑,我们来做一个简单的实验。
实验设计
使用 DeepSeek 模型,新建一个空文件夹,里面包含一个子文件夹 src,分别在两个文件夹中各创建一份 CLAUDE.md,写入不同的规则:
- 根目录规则:在每次回复的开头加上「根目录飞云喵」
- 子目录规则:在每次回复的结尾加上「子目录飞云旺」
然后分别在两个位置启动 Claude Code,观察回复中带了什么标签。
实验结果
- 在根目录启动:回复开头只带了「根目录飞云喵」的标签
- 在 src 子目录启动:开头有「根目录飞云喵」,句尾也附上了「子目录飞云旺」
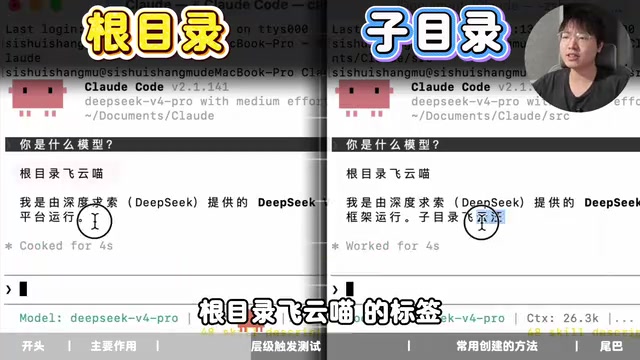
这说明了一个关键结论:CLAUDE.md 的层级是叠加的,不是覆盖的。子目录会在根目录的规则基础上,再多叠加一层自己的规则。
层级叠加的技术背景:向上遍历策略
Claude Code 的 CLAUDE.md 层级加载逻辑,与许多主流开发工具的配置文件发现机制高度相似。例如 ESLint 的 .eslintrc、Git 的 .gitignore、EditorConfig 的 .editorconfig 都采用类似的「向上遍历」(Upward Traversal)策略:从当前工作目录出发,逐级向父目录查找配置文件,并将所有找到的配置按优先级合并。Claude Code 的实现中,子目录的规则优先级高于父目录(在冲突时子目录规则生效),但两者并不互斥,而是叠加生效。这种设计的优势在于支持「单仓库多项目」(Monorepo)架构——根目录放全局编码规范,各子模块目录放各自的业务规则,互不干扰又能共享基础约定。
多层嵌套的加载情况
那如果子目录再创建子目录,是否能实现不断「套娃」的效果呢?答案是肯定的,但有一个重要前提——这跟你进入的文件夹层级有关。
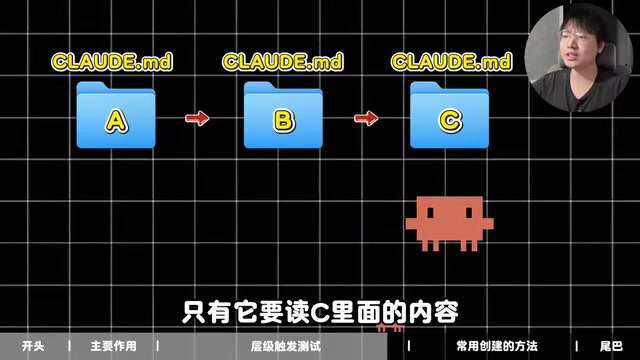
假设有这样的结构:文件夹 A → 子文件夹 B → 子文件夹 C,三个文件夹分别都有 CLAUDE.md。
- 如果 Claude Code 进入的是文件夹 B,那么 A 和 B 的 CLAUDE.md 都会被读取,主打一个「向上兼容」
- 而 C 的 CLAUDE.md 不会被加载——只有当 Claude Code 需要读取 C 里面的内容时,才会去查看 C 的 CLAUDE.md
这里还有一个实用建议:不要把 CLAUDE.md 的内容写得太长,因为它会占用上下文窗口(Context Window)。
上下文窗口是大语言模型在单次推理中能够处理的最大 Token 数量。Token 是模型处理文本的基本单位,大致上中文每个字约等于 1-2 个 Token,英文每个单词约等于 1 个 Token。以 Claude 系列模型为例,其上下文窗口通常在 10 万至 20 万 Token 之间。CLAUDE.md 的内容会在每次对话时被完整载入上下文,如果规则文件写了几千字,就会持续「占座」,压缩可用于代码分析、文件读取和实际对话的空间。因此,精炼的规则不仅是好习惯,更是对模型性能的实际优化——建议将 CLAUDE.md 控制在 500 字以内,只保留真正影响行为的核心规则。
新手如何编写 CLAUDE.md:三种实用方法
方法一:手动创建
最直接的方式。用记事本、VS Code 或任何顺手的编辑器,打开后想写什么就写什么,保存到项目文件夹里即可。这种方式适合对项目规范已经有清晰想法的开发者。
方法二:让 AI 帮你写
如果完全不知道该往里面写什么,可以按 Shift + Tab 切换到 Plan 模式,让 Claude Code 通过提问来了解你的需求,确认后让它直接创建。
当然,不仅限于 Claude Code,你也可以用其他 AI 工具生成内容,然后手动创建文件粘贴进去。
方法三:用 /init 指令自动生成
这是 Claude Code 自带的指令。进入 Claude Code 后直接输入 /init,它会扫描当前项目的文件结构,自动生成一份适合该项目的 CLAUDE.md。
/init 指令的核心能力是对项目进行静态分析(Static Analysis),即在不运行代码的前提下,通过扫描文件结构、读取关键配置文件(如 package.json、requirements.txt、Makefile 等)来推断项目的技术栈、依赖关系和代码组织方式。Claude Code 会据此自动生成包含项目语言、框架、目录结构说明、常用命令等内容的 CLAUDE.md 草稿。这一过程类似于 IDE 的项目索引功能,但输出的是自然语言描述而非代码索引。
实测用一个新闻摘要项目试了一下,它扫描文件结构后生成的内容基本覆盖了项目的实际情况,相当实用。对于已有一定规模的项目,/init 生成的内容可以作为很好的起点,开发者只需在此基础上补充团队特有的规范(如提交信息格式、代码审查要点等)即可投入使用。
不过有一个前提:最好在已经有内容的项目中使用,不要用空项目。空项目没有东西可以参考,生成的内容意义不大。
CLAUDE.md 实践建议总结
根据以上分析,总结几条 CLAUDE.md 的使用建议:
- 文件名严格大写:使用
CLAUDE.md而非claude.md,避免加载失败 - 善用层级叠加:根目录放通用规则(如语言、代码风格),子目录放模块特定规则
- 控制内容长度:规则精炼为主,建议控制在 500 字以内,避免占用过多上下文窗口
- 新项目用 /init:对已有项目快速生成基础规则,再手动调整
- 持续迭代:随着项目发展,不断更新和优化 CLAUDE.md 中的规则
CLAUDE.md 看似简单,但理解了
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。