Claude Code Hooks:用确定性控制替代提示词的终极方案
Claude Code Hooks用确定性机制替代概率性提示词,保障关键规则必定执行。
Claude Code的Hooks机制解决了提示词概率性执行的痛点,通过在LLM推理循环之外运行的程序化逻辑,确保关键操作每次都会触发。它提供五种生命周期事件(提交提示词、工具调用前后、通知、停止),支持自动格式化代码、拦截危险命令、合规审计等场景。项目级配置可提交代码仓库实现团队共享,核心原则是:必须执行的硬性规则用Hook,偏好性建议用提示词。
为什么你需要 Hooks 而不是提示词
Claude Code 的 Hooks 机制解决了一个核心痛点:确定性。你可以在 Claude.md 文件中告诉 Claude 每次编辑文件后运行 prettier 格式化,大多数时候它会照做,但偶尔会遗漏。这就是 AI 的本质——它是概率性的,不是百分百可靠的。
而 Hooks 不同,它是确定性的(deterministic),每次都会执行,没有例外。如果某件事需要每次都发生且不能失败,不要把它写在提示词里,把它放在 Hook 中。
在软件工程中,确定性意味着给定相同的输入,系统每次都会产生完全相同的输出。这是传统编程的基本特征——if-else 语句、循环、函数调用都是确定性的。而大语言模型(LLM)本质上是基于概率分布的下一个 token 预测器,即使 temperature 设为 0,在不同的上下文窗口状态下,模型的行为仍可能出现微妙差异。这就是为什么在 Claude.md 中写的指令有时会被「遗忘」——不是 AI 故意违抗,而是在复杂的推理链中,某些指令的权重可能被其他上下文信息稀释。Hooks 机制绕过了这个问题,它运行在 LLM 推理循环之外,是传统的程序化逻辑,因此具备绝对的可靠性。
常见的使用场景包括:
- 文件编辑后自动格式化代码
- 记录所有执行的命令用于合规审计
- 阻止危险操作(如修改生产环境文件)
- 任务完成时发送通知
Hooks 的五种生命周期事件详解
Hooks 在 Claude Code 生命周期的不同节点触发,配置在 settings.json 文件中。你需要选择一个事件类型,可选地设置匹配器(matcher)来指定适用的工具,然后提供要执行的命令。
Claude Code 采用了 Agent 架构中的工具使用(Tool Use)模式,也称为函数调用(Function Calling)。在这种架构中,LLM 不直接执行操作,而是生成结构化的工具调用请求(如编辑文件、运行命令、读取目录等),由外层的 Agent 运行时(Runtime)负责实际执行。这种设计创造了天然的拦截点——在工具调用的请求阶段和完成阶段都可以插入自定义逻辑。Hooks 正是利用了这些拦截点,类似于 Web 框架中的中间件(Middleware)或数据库的触发器(Trigger)概念,在不修改核心逻辑的前提下注入额外行为。
五种事件类型:
| 事件 | 触发时机 |
|---|---|
| User Prompt Submit | 提交提示词时,Claude 处理之前 |
| Pre-tool Use | 工具调用执行之前 |
| Post-tool Use | 工具调用完成之后 |
| Notification | Claude 发送通知时 |
| Stop | Claude 完成响应时 |
实战:用 Post-tool-use Hook 自动格式化代码
这是最常见的 Hook 用法。设置一个 post-tool-use Hook,matcher 匹配 edit 或 multi-edit 工具,这样每当 Claude 修改文件时就会触发。

命令脚本会检查文件扩展名,然后运行对应的格式化工具:
- TypeScript/JavaScript → Prettier
- Go → go fmt
- Python → Ruff
- 其他语言 → 对应的格式化器
这确保了无论 Claude 怎么编辑代码,输出都会符合你项目的代码风格规范,不需要事后手动修复。值得注意的是,这些格式化工具本身也是确定性的——Prettier 对同一段代码永远输出相同的格式化结果,go fmt 是 Go 语言官方唯一认可的格式化标准。将确定性的 Hook 触发机制与确定性的格式化工具结合,形成了端到端的一致性保障。
实战:用 Pre-tool-use Hook 拦截危险命令
pre-tool-use Hook 可以在工具调用执行前将其阻止。Hook 脚本通过 STDIN 接收工具名称和输入参数(JSON 格式),然后通过退出码来决定是否放行:
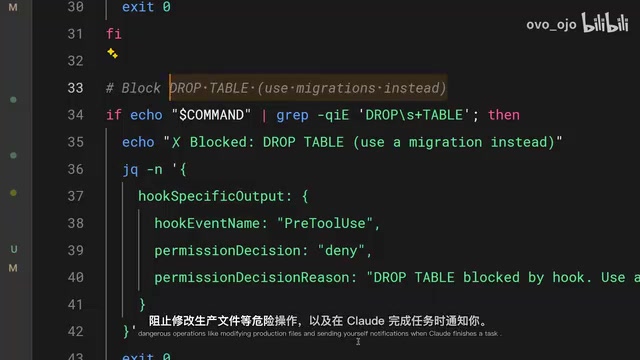
- Exit code 0:允许执行
- Exit code 2:阻止执行
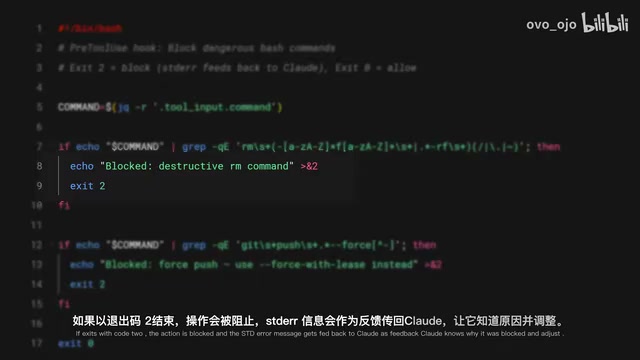
Unix/Linux 系统中,进程退出码(Exit Code)是父子进程间最基本的通信方式。按照 POSIX 标准,exit code 0 表示成功,非零值表示各种错误状态。Claude Code 的 Hooks 扩展了这一约定:exit code 0 表示放行,exit code 2 专门表示「主动阻止」。同时利用标准错误流(stderr)传递阻止原因,这是一种优雅的设计——它复用了操作系统已有的进程通信机制,不需要引入额外的 IPC(进程间通信)协议,任何能写 shell 脚本的开发者都能立即上手编写 Hook 逻辑。
关键细节:当 Hook 以 code 2 退出时,标准错误输出(stderr)的内容会作为反馈传递给 Claude,让它知道为什么被阻止,从而调整策略。这不是简单的「拒绝」,而是带有上下文的智能拦截。
典型的拦截规则:
- 阻止写入生产配置目录
- 阻止包含
rm -rf的 bash 命令 - 阻止直接提交到 main 分支
这些是硬性规则(guaranteed),不是建议(suggested)。区别在于:提示词里的规则 Claude 可能会忽略,但 Hook 中的规则绝对不会被绕过。
团队共享:项目级 Hooks 配置管理
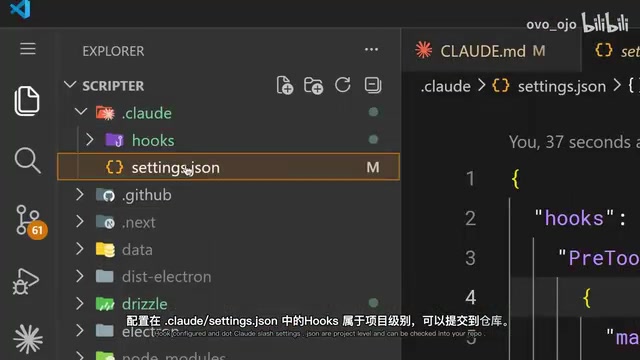
将 Hooks 配置在 .claude/settings.json 中,它就是项目级别的,可以直接提交到代码仓库。这意味着整个团队自动获得相同的 Hook 规则,无需每个人单独配置。
这种做法体现了 Infrastructure as Code(基础设施即代码)的理念。就像团队通过 .eslintrc 共享代码检查规则、通过 .editorconfig 统一编辑器设置一样,.claude/settings.json 让 AI 辅助编程的行为约束也变成了可版本控制、可代码审查、可追溯的团队资产。这解决了 AI 工具在团队中推广时的一个关键挑战:如何确保每个成员使用 AI 时都遵循相同的安全和质量标准,而不依赖于个人的自觉配置。
一个实用技巧:在命令中使用 $CLAUDE_PROJECT_DIR 环境变量来引用项目中存储的脚本,这样无论 Claude 当前的工作目录在哪里,脚本路径都能正确解析。
Hook vs 提示词:最佳实践选择指南
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 代码格式化 | Hook (post-tool-use) | 必须每次执行 |
| 安全规则 | Hook (pre-tool-use) | 不能有例外 |
| 编码风格偏好 | 提示词/Claude.md | 灵活性更重要 |
| 合规日志 | Hook (post-tool-use) | 不能遗漏 |
核心原则很简单:如果失败一次就可能造成问题(安全、合规、一致性),用 Hook;如果只是偏好或建议,用提示词就够了。
这种分层策略也反映了安全工程中的「纵深防御」(Defense in Depth)思想:提示词作为第一层软性引导,覆盖大多数正常场景;Hooks 作为第二层硬性保障,兜底那些绝对不能出错的关键路径。两者配合使用,既保持了 AI 交互的灵活性,又确保了工程实践的严谨性。
Hooks 机制让 Claude Code 从一个「大部分时候听话」的助手,变成了一个可以被严格管控的工程工具。对于团队协作和生产环境使用来说,这是不可或缺的能力。
核心要点
- Hooks 是确定性机制,与提示词的概率性执行不同,保证每次都会触发
- 五种生命周期事件:User Prompt Submit、Pre-tool Use、Post-tool Use、Notification、Stop
- Pre-tool-use Hook 通过退出码控制是否阻止操作,exit code 2 阻止并将 stderr 反馈给 Claude
- 项目级配置可提交到代码仓库,团队自动共享相同的 Hook 规则
- 核心原则:必须每次执行的规则用 Hook,偏好性建议用提示词
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。