Claude Code Hooks机制详解:规则失效时的安全网
Hooks机制通过按需注入提醒,弥补CLAUDE.md规则因注意力衰减而失效的问题。
CLAUDE.md规则因大模型注意力机制的距离衰减效应和指令容量上限而经常失效。Hooks机制通过在AI犯错的关键时刻将提醒注入上下文最末端来解决这一问题,包括事前阻断(PreCommand)、事后提醒(PostCommand)和回复结束触发(Stop)三种类型。其核心设计哲学是按需加载、提醒而非强制、分级响应,与CLAUDE.md配合构成完整的AI行为约束体系。
为什么CLAUDE.md规则会失效
使用Claude Code的开发者一定遇到过这样的困境:明明在CLAUDE.md中写了"禁止使用dev/null"、"请用uv代替python"等规则,但AI就是屡禁不止。这不是你的规则写得不好,而是大模型本身的机制决定了这些"软约束"天然不可靠。
大模型存在一个指令容量上限——即使是顶级模型,也只能同时兼顾约100条指令。当你正在执行一个复杂的编码任务时,代码本身可能就占据了80条指令的"脑容量",留给全局规则的空间只剩20条。模型会选择性遗忘它认为不重要的规则。
这一限制源于Transformer架构中的注意力机制(Attention Mechanism)。模型在生成每个token时,需要对上下文中所有token计算注意力权重。当上下文过长时,注意力会被稀释——这就是所谓的"Lost in the Middle"现象,由斯坦福大学2023年的研究证实:模型对上下文开头和结尾的信息记忆最好,中间部分则容易被忽略。这意味着即使模型的上下文窗口支持百万token,其有效利用率远低于理论值。
更关键的是距离衰减效应:CLAUDE.md等规则文件位于上下文的最前端(系统提示→工具定义→记忆文件→聊天记录),而当前对话在最末端。上下文窗口动辄上百万token,模型自然会更关注距离最近的内容,逐渐"忘记"远处的规则。
Claude Code的上下文结构遵循特定的层级:系统提示(System Prompt)位于最顶层,定义模型的基本行为;接着是工具定义(Tool Definitions),描述模型可调用的工具接口;然后是记忆文件(包括CLAUDE.md);最后是实际的聊天记录。这种结构意味着规则文件可能距离当前对话有数万甚至数十万token的距离。根据位置编码(Positional Encoding)的特性,模型对近距离信息的响应强度天然高于远距离信息。
这就是Hooks(钩子)机制存在的意义——它不是写在遥远的规则文件里,而是在AI真正犯错的那一刻,将提醒直接注入到最新的上下文位置。
Hooks的核心原理:按需注入
注入位置的优势
Hooks的精妙之处在于其注入位置。与CLAUDE.md不同,Hook是在AI执行某条命令时立即阻断,然后将提示信息注入到当前位置——也就是上下文的最末端。这相当于在AI即将犯错时,直接"弹窗"到它面前,而不是指望它记住几千token之前的某条规则。
这种设计还有一个额外好处:按需加载。规则文件无论是否用到,都会占据上下文空间、消耗token、降低模型"智商"。而Hook只在触发时才加载,平时完全不存在于上下文中,不会污染模型的思考能力。
上下文污染(Context Pollution)是一个被低估的问题:无关信息占据上下文空间后,会显著降低模型在核心任务上的表现。研究表明,即使是与任务无关的"噪声"文本,也会消耗模型的推理能力。这类似于人类在嘈杂环境中思考效率下降。每多加载一条不必要的规则,就相当于给模型增加了一点认知负担。按需加载的设计理念借鉴了操作系统中的懒加载(Lazy Loading)思想——只在真正需要时才分配资源,最大化有效上下文的利用率。
与Skill的对比
Hooks和Skills都是按需加载的机制,但触发方式截然不同:
- Skill是主动调用:AI自己判断"我需要做PPT",然后主动加载PPT技能
- Hook是被动触发:AI并不知道Hook的存在,直到触发条件命中,才会收到提醒
这两种机制的差异本质上是"推"与"拉"的区别。Skill采用拉模式(Pull):模型需要主动识别当前任务类型,然后从可用技能列表中选择合适的技能加载。这依赖模型的元认知能力——它需要知道自己不知道什么。而Hook采用推模式(Push):外部系统监控模型的行为,在特定条件触发时主动推送信息。这种设计消除了对模型自我意识的依赖,类似于编程中的观察者模式(Observer Pattern)或事件驱动架构。两者配合使用,可以覆盖"模型主动寻求帮助"和"模型无意识犯错"两种场景。
三种Hook类型详解
1. PreCommand Hook:事前阻断
最典型的场景是禁止某些危险命令。例如禁止使用2>/dev/null屏蔽错误输出:当AI试图执行包含该命令的bash时,Hook立即阻断,返回错误信息,要求AI重新构造命令。
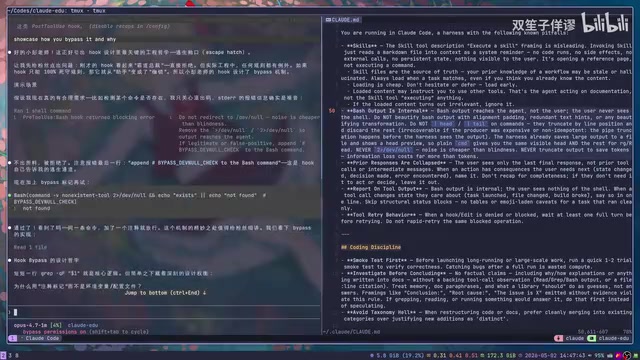
但这里有一个重要的设计哲学:不要把AI逼死。作者设计了bypass机制——如果AI在命令中添加了bypass注释,说明它已经读过提醒并确认确实需要这样做,Hook就放行。这就像手机管家的"仍然安装"按钮。
为什么不能完全堵死?因为bash命令的安全性检测本质上是一个不可判定问题(类似图灵停机问题)。你屏蔽rm开头的命令,AI可以用base64编码后解码执行;你屏蔽所有删除操作,echo rm这种无害命令又会被误杀。与其用机械规则堵死,不如让有智能的模型自己判断,只在它"冲昏头"时提醒一下。
图灵停机问题(Halting Problem)是计算理论中的经典不可判定问题:不存在一个通用算法能判断任意程序是否会终止。类比到命令安全检测,你无法写出一个完美的正则表达式或规则引擎来判断任意bash命令是否"安全"。命令可以通过管道组合、变量替换、编码解码、子shell嵌套等无数方式来实现同一个效果。例如$(echo cm0gLXJm | base64 -d)实际执行的是rm -rf,但从字面上完全看不出危险性。这就是为什么静态规则匹配永远存在误报和漏报,而利用大模型自身的语义理解能力来做"软判断"反而是更务实的方案。
2. PostCommand Hook:事后提醒
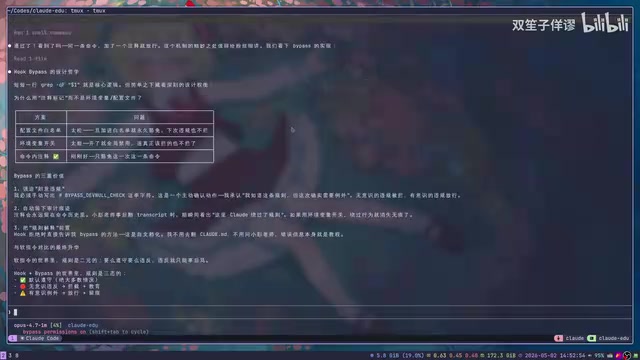
适用于非破坏性操作。例如建议用uv run python代替直接python3:Hook不会阻止python执行,但会在执行结果后面附加一条提醒——"下次请用uv run哦"。
设计原则很清晰:
- 破坏性/不可逆操作 → 事前阻断(如修改系统状态)
- 非破坏性/体验优化 → 事后提醒(如python可以运行,只是找不到包)
这种分级策略类似于操作系统中的权限管理:危险操作需要提前授权(sudo),而普通操作只在出问题时才提示。PostCommand Hook的优势在于不打断工作流——AI可以继续完成当前任务,同时在下一次遇到相同场景时改正行为。
3. Stop Hook:回复结束时触发
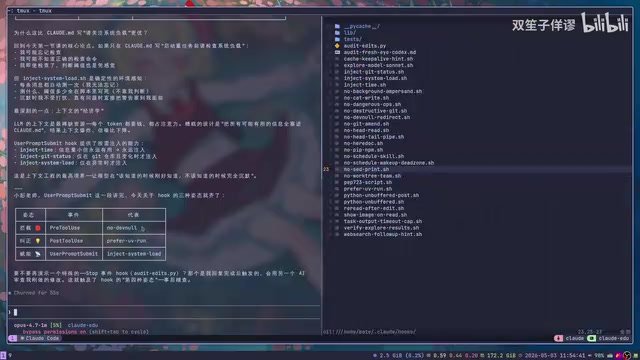
Stop Hook在AI完成回复时触发。典型应用是自动TL;DR——当AI输出了长篇大论后,自动要求它生成精简版本,省去每次手动输入"太长不看"的麻烦。
关键注意事项:Stop Hook必须防止无限循环。实现方式是检测当前回复是否已经是TL;DR格式,如果是则跳过触发。Claude Code内部也有一个close属性作为双重保险。
Stop Hook的无限循环问题类似于递归函数缺少终止条件:Hook触发生成新回复→新回复结束又触发Hook→再次生成回复……形成死循环。解决方案采用了双重保险:首先在脚本层面检测输出格式(如是否已包含TL;DR标记),其次Claude Code内部维护一个close属性作为状态标志,标记当前回复是由Hook触发的后续处理,不应再次触发Hook。这种防御性编程思想在事件驱动系统中很常见,类似于JavaScript中的事件冒泡控制(stopPropagation),确保事件只被处理一次而不会级联传播。
高级技巧:Hook与Skill联动
一个常见痛点是:配置了很多Skill,但AI经常忘记调用。原因很简单——几十个Skill夹在几千token的上下文中,模型根本找不到。
解决方案是用Hook劫持write操作来辅助触发Skill。例如:当AI试图创建HTML文件时,Hook检测到这是前端开发任务,自动注入"请先加载前端设计Skill"的提示。这样AI就会按照Skill中的规范(设计系统、组件库等)来编写页面,而不是随意输出不符合规范的代码。
这种联动模式本质上是在模型的行为链中插入了一个"检查点"(Checkpoint)。它解决了一个根本性矛盾:Skill需要模型主动调用,但模型在专注于具体编码任务时往往缺乏这种元认知。通过Hook的被动触发机制来弥补Skill的主动调用缺陷,形成了一个互补的闭环系统。
User Prompt Hook:隐形的上下文增强
还有一种特殊的Hook作用于用户输入时——在每条用户消息后自动附加信息(用户看不到,但AI能看到)。典型应用包括:
- 注入当前时间
- 注入Git状态(当前分支、未提交的更改)
- 系统负载过高时发出警告
这相当于给AI一个持续更新的"环境感知"能力,而不需要用户每次手动告知。这种设计借鉴了增强现实(AR)中的HUD(抬头显示)概念——关键环境信息始终可见但不干扰主要视野。对于开发场景而言,Git状态的自动注入尤其有价值:AI可以据此判断是否应该创建新分支、是否有未保存的工作需要先提交,从而做出更符合工程实践的决策。
设计哲学总结
Hooks的核心设计哲学可以概括为:
- 提醒而非强制——给AI退路,它反而更听话;逼急了它会用各种方式绕过
- 按需加载——不占用宝贵的上下文空间和模型"智商"
- 分级响应——破坏性操作阻断,非破坏性操作提醒
- 位置优势——注入在最新位置,利用大模型的局部性效应
这些原则背后有一个更深层的洞察:与大模型协作的最佳方式不是试图用硬编码规则完全控制它,而是构建一个"护栏系统"——在关键节点设置检查,在大方向上引导,同时给予模型足够的自主空间来发挥其推理能力。这与现代管理学中的"目标管理"理念不谋而合:设定边界和目标,但不微观管理每一步执行。
规则文件应该精细化管理,不能无限膨胀;而Hook作为安全网,在AI真正犯错时才介入,是对规则系统的完美补充。两者结合——CLAUDE.md提供全局方向指引,Hooks在具体执行层面保驾护航——构成了一个既高效又可靠的AI行为约束体系。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。