Claude Code Sub-Agent:多智能体协作提升开发效率实战指南

Claude Code Sub-Agent通过任务分解和专精化提升多智能体协作效率
Sub-Agent是Claude Code中将复杂任务分配给多个专用智能体执行的机制,每个子智能体拥有独立的提示词、工具权限和任务指令。它通过任务拆分解决了单Agent的指令丢失、上下文膨胀和成本飙升问题。当前仍为线性执行模式且上下文不共享,但未来并行多智能体模式将带来质的飞跃。
什么是 Sub-Agent?
Claude Code 的 Sub-Agent(子智能体)机制,是指在一个主智能体(Master Agent)的调度下,将复杂任务分配给多个预定义的专用智能体来执行。每个 Sub-Agent 拥有独立的系统提示词、工具权限和任务指令,相当于为特定领域配备了一位"专家"。
这与软件工程中常说的"单一职责原则"不谋而合——与其让一个通用 Agent 处理所有事情,不如让多个专精 Agent 各司其职。这一设计理念在软件架构领域有深厚的历史渊源:从1980年代的分布式人工智能(Distributed AI)研究,到2010年代兴起的微服务架构(Microservices),工程师们始终在探索"分而治之"的最优解。Sub-Agent 机制将这一思想引入 LLM 时代,每个智能体相当于一个"认知微服务"——拥有独立的职责边界、独立的运行上下文,以及标准化的输入输出接口。
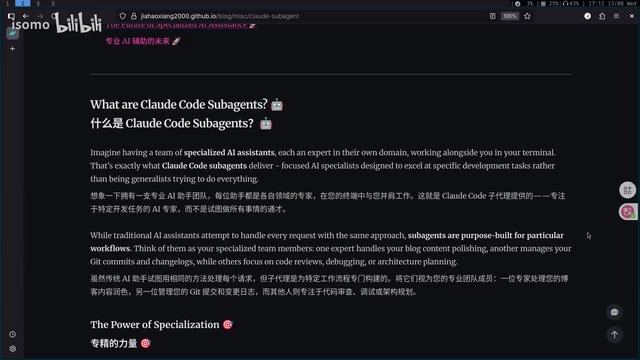
实战案例:博客写作 + Git 提交
两个 Agent 的分工
下面是一个简洁但典型的案例:定义两个 Sub-Agent——Blog Writing 和 Commit Push。用户只需一句简短指令:"用 Blog Writing 修复博客,然后 Commit",整个流程就自动串联起来。
具体执行过程如下:
- Blog Writing Agent 被触发,按照预定义的写作风格和规范对博客内容进行润色重写,包括使用粗体、斜体高亮关键内容,用 emoji 增强表达等
- 博客修复完成后,Commit Push Agent 接管,自动扫描修改内容,生成带 emoji 前缀的 commit message,更新 changelog,最后 push 到远程仓库
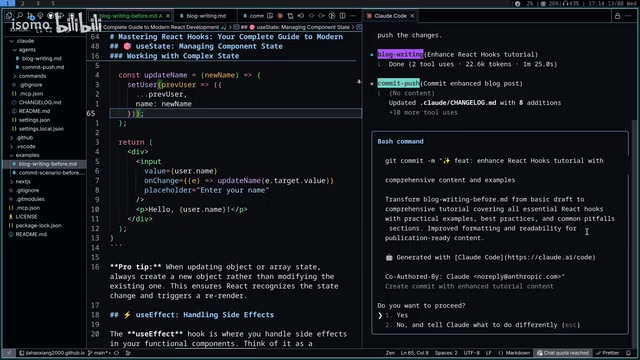
Agent 的定义结构
每个 Sub-Agent 的定义包含几个核心要素:
- 名称:Agent 的唯一标识
- 描述/简介:类似 MCP Server 的功能描述,告诉 Master Agent 这个子智能体能做什么、接受什么输入、产出什么输出
- 系统提示词:定义 Agent 的角色、职责和具体执行步骤
- 工具权限:允许该 Agent 使用哪些工具
这种结构与 MCP 中 Tool 的描述机制非常相似——Master Agent 通过阅读描述来判断应该调用哪个 Sub-Agent,就像 LLM 通过 Tool Description 来决定调用哪个工具一样。值得注意的是,这里的"描述"质量至关重要:Master Agent 本质上是在做一个语义匹配和意图路由的决策,描述越精准,调度准确率越高,这与搜索引擎中文档标注质量影响检索效果的原理如出一辙。
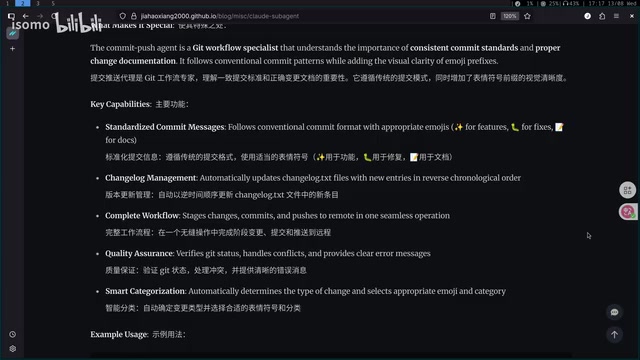
为什么需要 Sub-Agent?
解决指令丢失问题
当使用单个 Agent 处理复杂任务时,随着 prompt 中指令越来越多,Agent 容易"遗忘"部分指令。这一现象有其深刻的架构根源:Transformer 的注意力机制(Attention Mechanism)在处理超长上下文时存在"注意力稀释"效应——当输入序列过长时,模型对关键信息的关注度会被大量无关内容稀释。斯坦福大学2023年的研究将这一现象命名为"Lost in the Middle"问题,实验表明模型对位于上下文中间位置的信息遗忘率显著高于首尾位置的内容。
Sub-Agent 通过将任务拆分到独立上下文中执行,每个子任务的指令集更小更聚焦,从而显著降低指令丢失的概率。这本质上是一种**专精化(Specialization)**策略——不是试图修复模型的注意力缺陷,而是通过架构设计绕开它。
缓解上下文窗口压力
单个 Agent 处理多步骤任务时,上下文会不断膨胀。Claude Code 目前最大支持 1MB 的上下文窗口,但上下文越大会带来两个问题:
- 质量下降:上下文过长时,模型对某些任务的处理能力会明显下滑
- 成本飙升:API 按上下文分级计费,256K 以下是基础价格,超过 256K 后价格翻倍甚至三倍。1MB 上下文的 token 单价从 3 美元涨到 6 美元
这里的计费机制值得深入理解:主流 LLM API 采用的是**分层定价(Tiered Pricing)**模型,本质上反映了长上下文推理对 GPU 显存(VRAM)的非线性消耗——Transformer 的 KV Cache 随序列长度呈二次方增长,导致基础设施成本急剧上升,这一成本最终被转嫁到 API 定价中。Sub-Agent 让每次请求的上下文更小、更精准,既省钱又提质。
工作流标准化与复用
将常用的工作模式固化为 Sub-Agent 后,相当于建立了可复用的自动化流水线。下次遇到相同类型的任务,直接调用即可,无需重复描述流程细节。这与 DevOps 领域的"基础设施即代码"(Infrastructure as Code)理念相通——将人类的操作经验和最佳实践编码化、版本化,使其可以被稳定复现和持续迭代。
当前局限与未来展望
线性执行的瓶颈
目前 Claude Code 的 Sub-Agent 仍然是线性(Linear)执行模式:Master Agent 调用一个 Sub-Agent 后会阻塞等待其完成,然后才能调度下一个。多个子任务只能串行处理,无法并行。
从计算机科学的视角来看,这相当于单线程同步执行模型——简单可靠,但吞吐量受限于最慢的那个环节。对于 I/O 密集型任务(如网络请求、文件读写),串行等待会造成大量资源空转,这正是异步编程和并发模型在软件工程中大放异彩的原因。
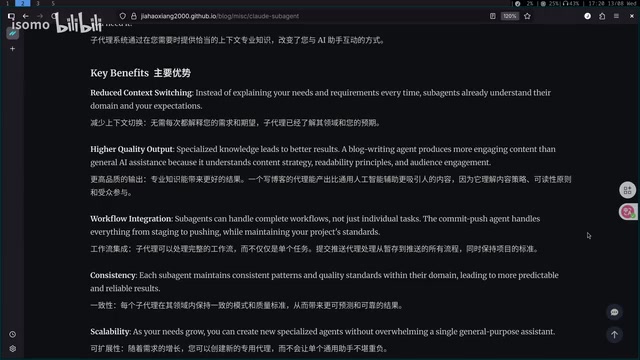
并行多智能体的想象空间
真正令人期待的是**并行多智能体(Parallel Multi-Agent)**模式:多个 Agent 同时运行,彼此之间还能进行 Agent-to-Agent 的通信与协调。这一领域目前正处于协议标准化的关键阶段——Anthropic 推出的 MCP(Model Context Protocol)和 Google 的 A2A(Agent-to-Agent)协议,都在尝试定义智能体间信息交换的标准格式,解决消息路由、状态同步、冲突仲裁等分布式系统经典难题,同时还要应对 LLM 输出非确定性带来的额外复杂度。
并行多智能体将带来质的飞跃:
- 效率提升:从几倍提升到几十倍甚至上百倍
- 能力突破:多领域同时精通,跨 Agent 协调,处理单个人甚至团队都难以应对的复杂问题
- 无限分解:任务可以层层拆解,每层再细分为多个子 Agent,形成树状执行结构
比如你想制作一个技术视频,可以让一组 Agent 同时负责:资料收集、代码编写、文档生成、演示视频制作。每个环节还能继续细分,最终只需给定一个 topic,就能产出完整的代码、文档和视频。
上下文不共享的成本问题
当前 Sub-Agent 的一个现实问题是上下文不共享。Master Agent 和 Sub-Agent 各自维护独立的上下文,相同的信息可能被重复加载,导致 token 消耗翻倍。这在分布式系统领域对应一个经典问题:共享状态管理。传统解决方案包括共享内存、消息队列、分布式缓存等,但在 LLM 场景中,"状态"本身是非结构化的自然语言,如何高效压缩、索引和检索上下文信息,是当前 AI 工程领域亟待突破的核心挑战之一。这对成本控制不太友好,也是未来需要优化的方向。
如何创建 Sub-Agent
创建过程相当简单:在 Claude Code 中使用 /agent 命令,然后 new 一个新的 Agent,按照引导步骤逐步定义即可。Claude Code 甚至可以帮你自动生成 Sub-Agent 的提示词和配置。
关键是要为每个 Sub-Agent 设计好以下几点:
- 清晰的角色定位(Role):这个 Agent 是做什么的
- 精准的任务指令(Instructions):具体要完成什么工作
- 合理的执行步骤:先做什么、再做什么,流程要明确
- 必要的约束条件:输出格式、质量标准等边界要求
在提示词工程(Prompt Engineering)实践中,为 Sub-Agent 编写系统提示词时有一个重要原则:越具体越好。模糊的角色定义会导致 Agent 在边界情况下行为不可预测,而精确的步骤描述则能显著提升输出的一致性和可靠性。可以参考"Chain-of-Thought"(思维链)提示技术,将复杂任务分解为明确的推理步骤写入系统提示词,引导 Agent 按照预期路径执行。
总结
Sub-Agent 机制的核心价值在于:通过任务分解和专精化,提升每个子任务的执行质量和整体工作流的可靠性。其背后是对 Transformer 注意力机制固有局限的架构级应对,也是软件工程"分而治之"思想在 AI 时代的自然延伸。虽然目前仍是线性执行模式,且存在上下文不共享导致的成本问题,但它已经展示了多智能体协作的巨大潜力。
在并行多智能体真正到来之前,先学会用十几个 Sub-Agent 以线性方式高效协作,就是当下最值得投入的实践方向。
核心要点
- Sub-Agent 通过将复杂任务分配给多个专用智能体执行,解决了单 Agent 指令丢失和上下文膨胀的问题
- 每个 Sub-Agent 拥有独立的系统提示词、工具权限和任务指令,实现了任务的专精化处理
- 当前 Claude Code 的 Sub-Agent 仍为线性执行模式,未来并行多智能体将带来数十倍效率提升
- 上下文分级计费机制下,Sub-Agent 通过缩小单次请求上下文来降低 API 成本
- Sub-Agent 的上下文不共享是当前的主要局限,相同信息可能被重复消耗 token
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。