Claude Code Ultra Review实测:多Agent代码审查深度解析
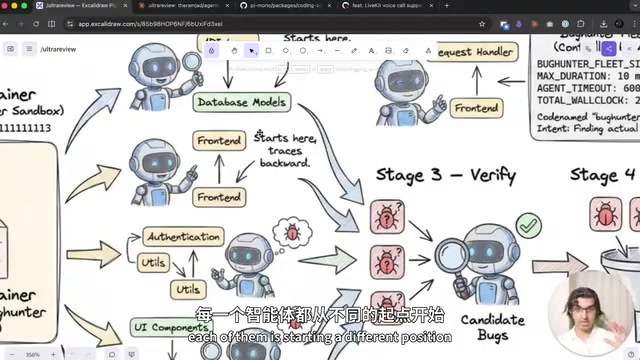
Claude Code推出多Agent并行深度代码审查功能Ultra Review
Claude Code即将推出Ultra Review功能,通过四阶段流程(Setup→Find→Verify→Dedupe)在云端启动多个子Agent并行审查代码。其核心创新在于独立验证阶段,有效过滤误报。相比普通/review,Ultra Review能发现竞态条件等深层Bug,但耗时更长。该功能目前隐藏在Feature Flag后,$200/月计划仅提供3次免费使用,其"发现+验证"设计模式可通过自定义工作流复制。
什么是Ultra Review?
Claude Code即将推出一项名为Ultra Review的全新功能,它是现有/review命令的重大升级。与普通的代码审查不同,Ultra Review会在云端启动多个独立的子Agent,花费10-20分钟对代码进行深度审查,不仅能发现Bug,还能验证这些Bug是否真实存在。
目前该功能隐藏在Feature Flag之后,尚未对所有用户开放。Feature Flag(功能开关)是现代软件工程中的标准发布实践,允许团队在不修改代码的情况下动态控制功能的可见性。通过Feature Flag,Anthropic可以对Ultra Review进行精细化的灰度发布:先向内部员工开放,再扩展到特定付费层级用户,最终全量发布。这种机制还天然支持A/B测试——向不同用户群展示不同的Agent配置,通过数据驱动决策最优参数组合。
通过对Claude Code二进制文件的逆向工程,可以发现这个功能内部代号为"Bug Hunter",默认启动5个子Agent组成的"舰队",最大可扩展到20个(可能面向企业用户)。
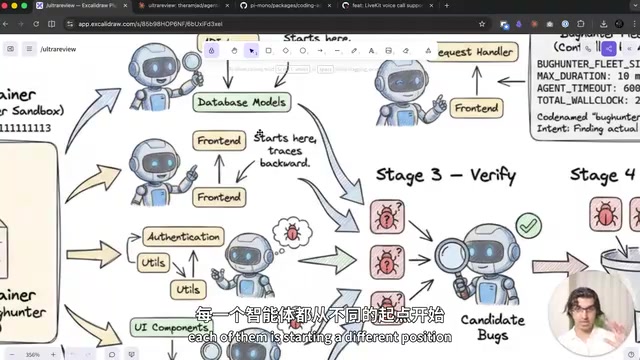
Ultra Review的四阶段工作流程
Setup阶段:初始化审查会话
当用户执行/ultra review命令并指定一个PR时,系统会在Claude Code的云端版本上启动一个审查会话。在$200/月的计划中,目前可以免费使用3次Ultra Review。
Find阶段:多Agent并行搜索
这是Ultra Review最核心的创新之一。系统会启动5个独立的子Agent,每个Agent从代码库的不同位置开始,沿着不同的路径分析最近的代码变更。
多Agent并行架构源于分布式AI系统设计理念。 在大型语言模型应用中,单一Agent受限于上下文窗口大小(通常为100K-200K tokens),面对超大代码库时往往力不从心。多Agent架构通过将任务分解并行处理,不仅突破了单一上下文的限制,还利用了"集成学习"的思想——类似于机器学习中的Ensemble方法,多个独立判断的综合结果往往优于单一判断。
这种设计背后有深刻的技术考量:上下文窗口中代码加载的顺序会影响Bug的可见性——某种顺序下显而易见的Bug,换一种顺序可能就会被模型忽略。这一现象在学术界被称为"位置偏差"(Positional Bias)。 研究表明,LLM倾向于更关注输入序列的开头和结尾,中间部分的信息容易被"遗忘"。在代码审查场景中,同样的Bug放在上下文的不同位置,模型发现它的概率可能相差数倍。多个Agent从不同角度切入,正是系统性地对抗这种位置偏差,大大提高了Bug的发现率。
此外,这些子Agent很可能拥有不同的"人设"(Persona)——一个专注于计费逻辑,另一个专注于安全性,以此类推。在测试的PR(约11,000行新增代码的语音通话功能)中,Find阶段共发现了64个潜在Bug候选。
Verify阶段:独立验证,过滤误报
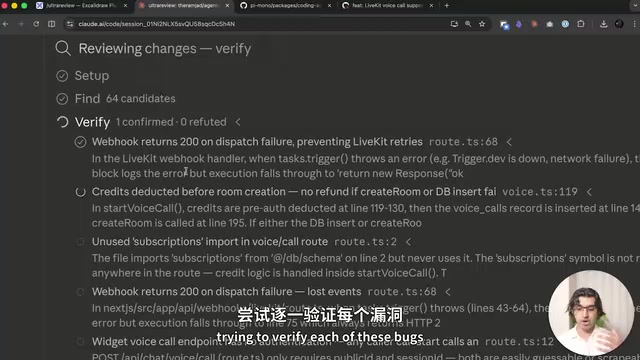
这是Ultra Review与传统代码审查工具最大的区别。误报(False Positive)是代码静态分析工具长期面临的核心痛点。 业界知名工具如SonarQube、Coverity的误报率通常在30%-70%之间,导致开发者产生"警报疲劳"(Alert Fatigue),逐渐忽视工具输出。Google内部研究显示,当工具误报率超过10%时,开发者的采纳率会急剧下降。
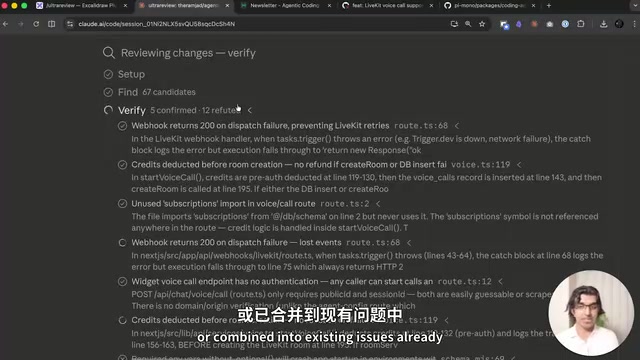
Verify阶段引入了独立的验证Agent,逐一检查Find阶段发现的候选Bug,确认它们是否真实存在。其本质是在模拟人工二次确认流程,将AI的高召回率(Recall)与验证步骤的高精确率(Precision)结合,试图在自动化层面解决这一行业难题。在测试中,验证阶段驳回了至少9个误报Bug。这种机制有效防止了Claude Code对虚假问题进行不必要的修改。
Dedupe阶段:去重合并
由于多个子Agent可能从不同角度发现了同一个Bug(只是表述不同),Dedupe阶段会将重复发现合并为唯一的Issue,确保最终报告简洁清晰。
Ultra Review vs 普通Review对比
对同一个11,000行的PR分别运行普通/review和Ultra Review,结果差异显著:
| 维度 | /review | Ultra Review |
|---|---|---|
| 运行时间 | 3-4分钟 | 约17分钟 |
| 运行位置 | 本地 | 云端 |
| 验证步骤 | 无 | 有 |
| 审查风格 | 快速审计,标记偏差 | 攻击者视角,深度追踪 |
通过GPT Codex对两份报告的比较分析:
- 普通Review更像是对整个代码库的快速审计,任何偏离常规的地方都会被标记
- Ultra Review更像是一个攻击者,它会选择PR中的某条路径并尝试各种方式打破它
Ultra Review发现了普通Review完全遗漏的竞态条件(Race Condition)和生命周期Bug,并且在跨文件关联分析方面表现更优。竞态条件是并发编程中最难发现的Bug类型之一,指多个执行线程或进程在访问共享资源时,因执行顺序的不确定性导致程序行为异常。这类Bug在单线程测试中几乎不会复现,只在高并发生产环境下偶发,传统静态分析工具因无法模拟运行时状态而难以检测。Ultra Review能发现竞态条件,说明其多Agent深度追踪机制具备跨文件、跨调用链的语义理解能力,而非简单的模式匹配。
将验证模式应用到自己的工作流
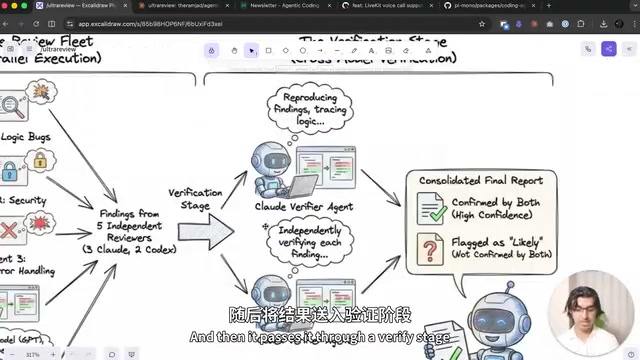
即使无法使用Ultra Review,其核心设计模式——"发现+验证"——完全可以复制到自己的工作流中。基于这一思路,可以创建一个自定义的Fleet Review Skill:
- 发现阶段:同时启动3个Claude Code子Agent和3个Codex CLI(Headless模式)子Agent寻找Bug
- 验证阶段:分别使用Claude Code验证器和Codex验证器交叉验证
这种交叉验证特别有价值——有时Codex会判定Claude Code发现的Bug并非真正的Bug,反之亦然。两个不同模型的验证能显著提高结果的可靠性。这一思路与机器学习中的**模型集成(Model Ensemble)**原理一脉相承:不同架构或训练数据的模型往往具有互补的错误模式,组合使用可以系统性地降低单一模型的盲区。
使用建议与展望
基于目前的信息,推荐的代码审查策略可以按重要程度分层:
- 日常PR:使用
/review进行快速审查(3-4分钟) - 重要功能:额外使用Codex进行补充审查
- 关键/大型PR:使用
/ultra review进行深度审查(10-20分钟)
Ultra Review目前每月仅提供3次免费使用,这暗示其运行成本较高。Anthropic可能在云端使用了不同的模型配置,甚至可能混合使用了未发布的模型。未来该功能可能会进行A/B测试,尝试不同的子Agent配置和提示词组合。
从更宏观的角度看,Ultra Review代表了AI代码审查的一个重要趋势:从单一Agent的一次性扫描,走向多Agent协作、多阶段验证的深度审查。这种"舰队式"的审查架构,配合独立验证机制,正在重新定义自动化代码审查的质量上限。
核心要点
- Ultra Review采用四阶段流程(Setup→Find→Verify→Dedupe),默认启动5个子Agent从不同角度并行搜索Bug
- 独立验证阶段是其核心创新,有效消除误报,防止对虚假Bug进行不必要的代码修改
- 与普通/review相比,Ultra Review能发现竞态条件等深层Bug,但耗时更长(17分钟 vs 3-4分钟)
- 该功能内部代号Bug Hunter,目前$200/月计划仅提供3次免费使用,暗示运行成本较高
- 其"发现+验证"的设计模式可通过自定义Skill复制,结合Claude Code和Codex交叉验证效果更佳
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。