Claude Code实战:半小时从零搭建电影数据爬取与展示系统

AI辅助编程半小时可搭建原型,但从原型到产品仍需工程师专业判断。
一位B站UP主用Claude Code在半小时内从零搭建了包含爬虫、Doris数据库、Spring Boot后端和Vue前端的电影数据系统。过程中发现两大关键挑战:现代反爬策略要求使用真实浏览器模拟人类行为,以及不同AI模型在爬虫场景下表现差异巨大。案例表明AI擅长快速原型开发,但稳定性、异常处理等工程化问题仍需人工持续迭代。
AI时代的快速原型开发有多快
刷朋友圈时,总能看到有人晒用AI搭建的各种系统截图。这种「手搓一个系统」的冲动,相信很多开发者都有过。B站UP主分享了自己用Claude Code在不到半小时内,从零搭建了一个完整的电影数据爬取与展示系统的全过程。
Claude Code是Anthropic推出的命令行AI编程助手,它能够直接在终端中理解开发者的自然语言指令,自动生成、修改和调试代码。与传统的代码补全工具(如GitHub Copilot)不同,Claude Code具备项目级别的上下文理解能力,可以同时处理多个文件、理解项目架构,并执行从创建文件到运行测试的完整开发流程。这使得它特别适合全栈项目的快速搭建场景。
这个案例的价值不在于系统本身有多复杂,而在于它展示了AI辅助编程在「快速原型验证」场景下的真实效率——从想法到可运行的系统,半小时足矣。
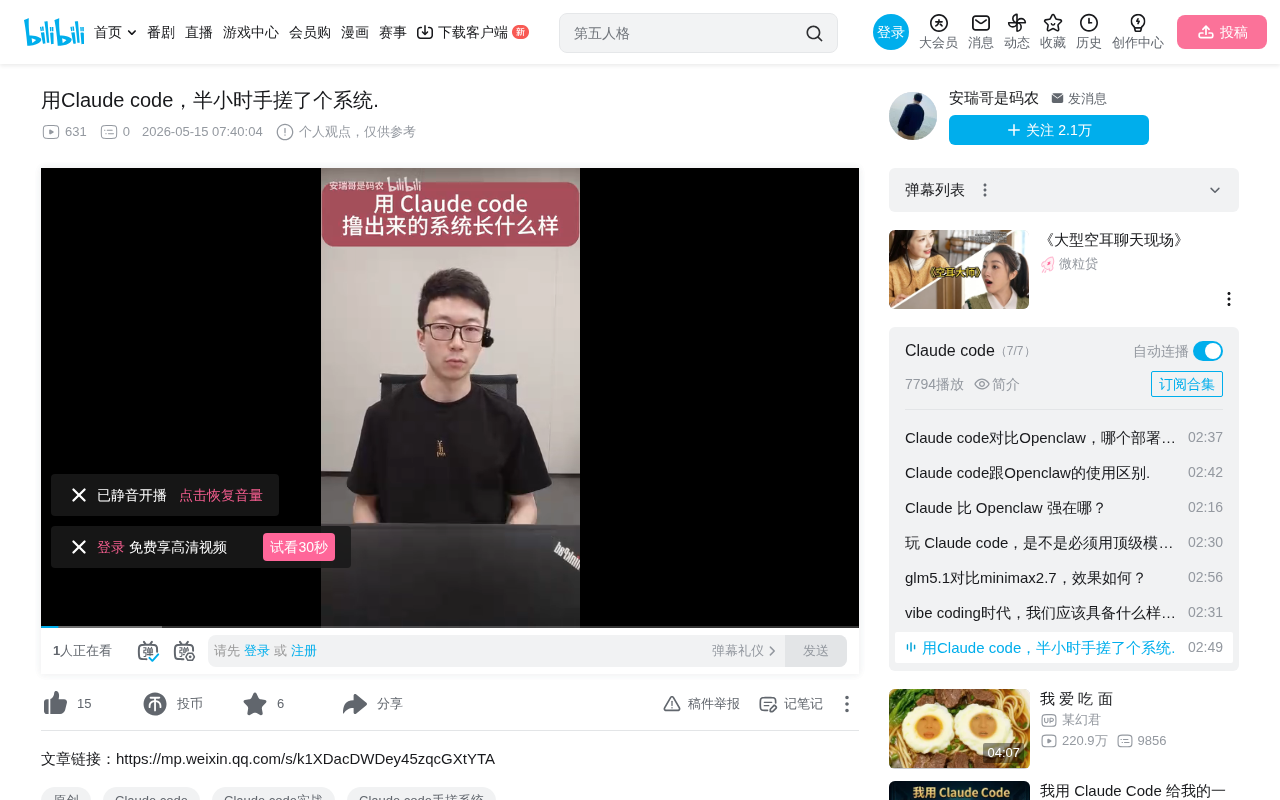
系统架构:四大模块的设计思路
这个电影数据系统的需求很明确:把一个电影网站的数据爬取下来,存入数据库,再通过前后端展示出来。整体架构包含四个核心部分:
- 爬虫程序:负责从目标电影网站抓取数据
- 数据库:选用Doris的去重引擎表,防止数据重复
- 后端服务:基于Spring Boot,处理数据查询请求
- 前端展示:使用Vue + ECharts,实现数据可视化展示

其中数据库选型值得特别说明。Apache Doris是一款高性能的实时分析型数据库,其Unique Key模型(即去重引擎表)能够根据指定的主键自动对数据进行去重处理。当插入重复主键的数据时,新数据会自动覆盖旧数据,无需开发者手动编写去重逻辑。这对于爬虫场景特别有价值——同一部电影可能被多次爬取,去重引擎表能在数据库层面自动保证数据唯一性,大幅简化了应用层的代码复杂度。相比MySQL中需要手动处理INSERT ON DUPLICATE KEY UPDATE的方式,Doris的方案更加优雅。
当把这四个部分的大致想法喂给Claude Code之后,它会先进行思考并给出执行计划,然后逐步实现各个模块。对于这种结构清晰、技术栈明确的全栈开发项目,AI的执行效率确实惊人。
关键挑战一:现代反爬策略的应对
系统虽然简单,但爬虫部分依然是最大的技术难点。如今几乎所有网站都有反爬策略,传统的HTTP请求方式早已失效。
现代网站的反爬体系已经从早期的User-Agent检测、IP频率限制,演进到基于浏览器指纹识别、行为分析和机器学习的综合防护。像Cloudflare的Turnstile、Google的reCAPTCHA v3等验证系统,会通过分析鼠标轨迹、键盘输入节奏、Canvas指纹、WebGL渲染结果等数百个维度来判断访问者是否为真人。无头浏览器(Headless Browser)由于缺少某些浏览器API特征和渲染行为,已经很容易被这些系统识别出来。
因此,唯一靠谱的方式是:让爬虫程序像真人一样操作浏览器。具体来说:
- 必须启动真实的浏览器实例(而非无头模式)
- 模拟真实用户的点击、滚动等行为
- 爬虫运行的服务器必须带桌面功能
- 爬取过程中需要频繁弹出浏览器窗口
- 偶尔还需要人工介入完成验证
这意味着部署环境不能是普通的无GUI服务器,需要配置桌面环境(如XFCE、GNOME等Linux桌面,或通过VNC/RDP远程访问)。这是很多开发者在实际爬虫开发中容易忽略的关键细节——当你在本地开发时一切正常,但部署到云服务器后爬虫就失效了,往往就是因为缺少图形界面环境。
关键挑战二:模型选择决定成败
一个非常有意思的发现是:不同AI模型在爬虫场景下的表现差异巨大。
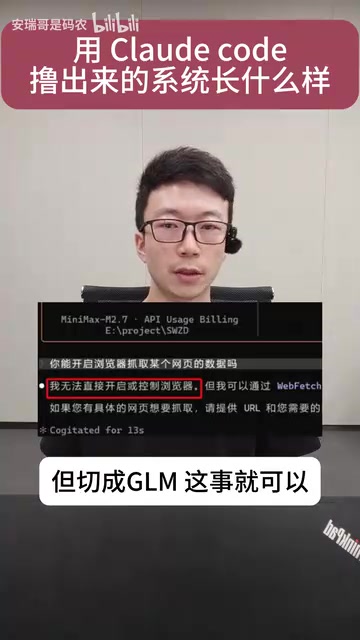
UP主对比了MiniMax 2.7和GLM 5.1两个模型,结果令人意外:
- 同样的爬虫任务,MiniMax表示「搞不定」
- 切换到GLM后,同样的代码逻辑就能正常运行
- 更关键的是,在浏览器页面验证环节,MiniMax调用浏览器时验证始终过不去,而GLM则可以顺利通过
MiniMax 2.7是稀宇科技推出的大语言模型,在文本生成和对话方面表现优秀;GLM 5.1则是智谱AI基于GLM架构推出的最新版本模型。两者在浏览器自动化场景下的表现差异,可能源于训练数据中涉及Web自动化、Selenium/Playwright等工具使用的代码样本比例不同,以及模型在工具调用(Tool Use)和多步推理方面的能力差异。
这也反映出当前大模型在垂直场景下的能力分化现象——通用评测分数接近的模型,在特定任务上可能有天壤之别。选择合适的模型,有时比优化Prompt更重要。对于开发者来说,在关键技术环节进行多模型对比测试,应该成为工作流中的标准步骤。
从玩具到产品:后续迭代的现实问题
虽然半小时就能跑起来一个初级版本,但要把它做成一个稳定可用的系统,还需要面对大量工程问题:
- 程序卡死:长时间运行的爬虫进程可能因各种原因挂起
- 数据丢失:网络中断、进程异常退出导致数据未持久化
- 数据格式不对:不同页面结构差异导致解析失败
- 数据入库失败:类型不匹配、字段缺失等数据库层面的问题
软件工程中有一个经典的「最后10%问题」——项目的前90%功能可能只占20%的时间,而最后10%的打磨(异常处理、边界情况、性能优化、监控告警)却要消耗80%的时间。AI工具目前擅长的是生成「Happy Path」代码——即一切正常运行时的逻辑路径。但生产环境中的网络抖动、内存泄漏、并发冲突、数据异常等问题,需要开发者基于实际运行经验进行针对性处理。
这些工程化的细节才是真正耗时的部分,也是AI辅助编程目前还不能完全替代人工的地方。一个爬虫程序在开发环境跑通和在生产环境稳定运行7×24小时,是完全不同量级的工程挑战。
总结与思考
这个Claude Code实战案例给我们的启示是:
- AI最擅长「从0到0.5」的快速原型开发:搭建原型、验证想法,这是Claude Code等AI编程工具的最大价值
- 技术选型仍需人工判断:选择Doris去重表、选择带桌面的服务器,这些决策需要开发经验
- 模型选择是隐性成本:不同模型在特定场景下表现差异巨大,需要实际测试才能确定
- 「从0.5到1」依然需要耐心:稳定性、异常处理、数据质量等问题需要持续迭代
AI让「想法变成代码」的门槛大幅降低,但让「代码变成产品」依然需要工程师的专业判断和持续投入。对于开发者来说,善用AI工具做快速验证,再用工程思维打磨细节,才是当下最高效的开发方式。这也意味着,未来开发者的核心竞争力将从「写代码的速度」转向「做正确决策的能力」——知道该用什么技术、该防范什么风险、该在哪里投入精力,这些判断力在AI时代反而变得更加珍贵。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。