Claude Code架构深度解析:单循环设计为何碾压多智能体

Claude Code凭借极简单循环架构和精细工具提示词,击败复杂多智能体方案
Claude Code发布6个月年收入破10亿美元,其核心设计哲学却是"什么都不做"——采用单一控制循环而非多智能体架构,将重点放在9400 token的工具提示词和协作记忆文件claude.md上。这种极简设计践行了《苦涩的教训》的核心观点:简单方法加强大算力终将胜过复杂人为设计。
文章正文
最近,Claude Code 成为 AI 编程领域最炙手可热的工具。Google 高级工程师称它一小时内生成了团队花一年才完成的东西,前特斯拉 AI 总监 Karpathy 表示"从未感到如此落后",而 Claude Code 的创造者 Boris 更是透露:30天内他对代码库的所有贡献——4万行新代码、259个PR——100%由 Claude Code 编写。
发布仅6个月,这款工具年收入已突破10亿美元。然而,当 Metis X 团队拦截并分析了它的每一个网络请求后,得出的结论却令人惊讶:它的强大,恰恰来自于它什么都没有做。
反常识:单循环架构击败多智能体
整个 AI 圈都在卷多智能体编排、复杂的 RAG 流水线和嵌套 Agent,而 Claude Code 内部只遵循一条规则——Keep It Simple(保持简单)。
这践行了 AI 领域经典文章《苦涩的教训》(The Bitter Lesson)的核心观点。这篇文章由强化学习先驱、图灵奖得主 Rich Sutton 于2019年发表,他回顾了70年AI研究史后得出结论:每当研究者试图将人类领域知识硬编码进AI系统时,短期内看似有效,但长期都会被"更多算力+更简单算法"的方案所超越。国际象棋、围棋、语音识别、计算机视觉——无一例外。这篇文章在大模型时代被反复引用,因为它精准预言了GPT系列的崛起:不是靠精心设计的语言规则,而是靠Transformer架构加海量数据和算力。历史反复证明,依靠通用算力和简单方法,最终会打败那些花哨的人为设计。
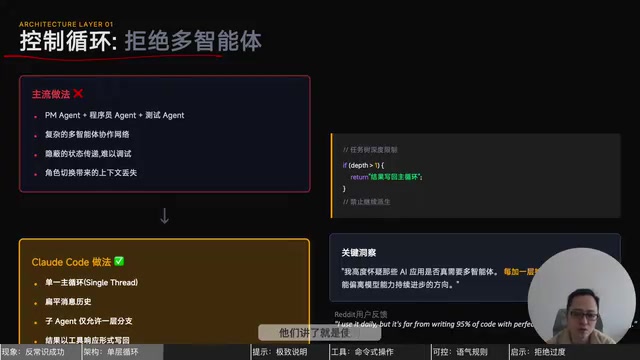
多智能体(Multi-Agent)架构在2023-2024年成为AI应用开发的热门范式,代表框架包括AutoGen、CrewAI、LangGraph等,核心思想是将复杂任务分解给多个专职Agent并行处理。然而实践中暴露出严重问题:Agent间通信的上下文损耗、错误在链路中的级联放大、以及几乎无法调试的"黑盒"行为。随着Claude 3.5、GPT-4o等模型上下文窗口扩展到20万token以上,单模型处理复杂任务的能力大幅提升,多Agent的必要性被进一步削弱。
Claude Code 只开了一个单一控制循环:模型返回工具调用就执行工具,返回文本就结束对话。对话历史是扁平的,子任务最多只允许一层分支。比如在写 Python 脚本时发现需要先用 pip 安装依赖包,主线程会启动一个 sub-agent 完成安装,然后结果写回主干线继续执行——但绝不允许在 sub-agent 里再嵌套 sub-agent。
为什么要这样设计?Reddit 用户说得很直接:每增加一层抽象,调试就难十倍。 当你有五个以上的智能体时,A 的输出传给 B,B 传给 C,C 传给 D……一旦出错,你需要沿着整条链路反推找根源,工作量巨大且不一定能成功。而单循环架构下,所有决策权保留在一个主模型中,工具调用结果直接写回同一上下文窗口,状态始终可见可追溯,顺着一条线就能快速定位 bug 源头。
提示词工程:9400 token的工具说明书有多重要
一组关键数据揭示了 Claude Code 的设计哲学:
- 系统提示词(System Prompt):仅 2800 个 token
- 工具提示词(Tool Prompt):长达 9400 个 token
- 协作记忆文件(claude.md):1000-2000 token
这意味着它把力气花在教模型怎么使用工具,而不是教模型"你是谁"。
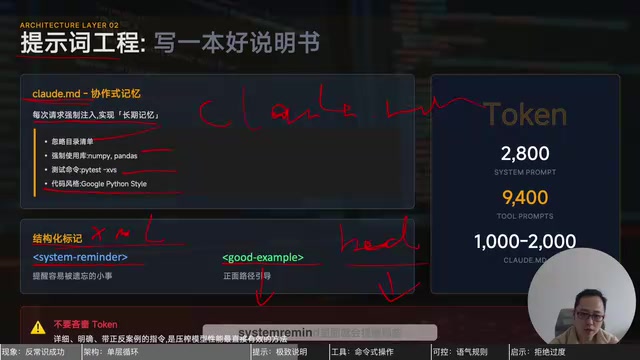
claude.md 是一个协作式的记忆文件,记录着项目规则:忽略哪些目录、强制使用哪些库(如 NumPy、Pandas)、测试命令是什么、代码风格规范等。理解这个设计需要先了解大语言模型的记忆局限——模型本质上是无状态的,每次API调用都从零开始,没有跨会话的原生记忆能力。工程界为此发展出多种方案:向量数据库存储历史摘要、结构化数据库记录用户偏好,以及最简单直接的"记忆文件注入"。claude.md 采用的正是最后一种方案,其设计哲学与软件工程中的"约定优于配置"(Convention over Configuration)异曲同工。它不是一次性的提示,而是在开发过程中持续被修改和更新,每次请求都会强制注入,实现长期记忆。这种方案的有效性高度依赖模型对长上下文的理解能力——这也是为什么它在 Claude 3 系列发布后才真正成熟可用。
提示词中还使用了 XML 做结构化标记,包含 good_example 和 bad_example 来引导模型行为,以及 system_reminder 来提醒容易遗忘的细节。正如一位工程师所说:**"模型就像最聪明的实习生,你需要把规则写进它的 DNA,它才不会犯错。
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。