Claude Code全栈交付实战:一人完成企业级RAG项目开发
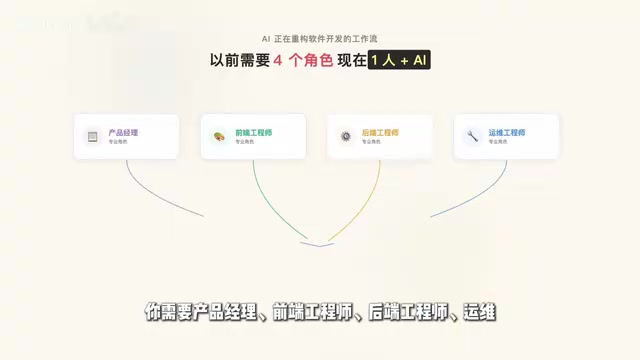
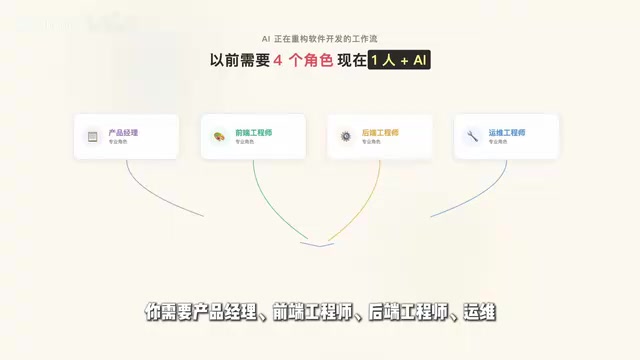
AI编程工具正在重构软件开发流程,一人可交付小团队产出
文章阐述了AI编程工具如何重构全栈开发工作流。核心观点包括:企业级RAG项目应采用"后端驱动前端"策略,先验证技术链路再开发界面;规范文档是AI协作开发的关键底座,用于解决AI会话失忆问题,确保项目一致性。掌握AI编程工具的人,个人产出可比肩小团队。
AI编程正在重构软件开发工作流
用AI做全栈项目,最容易翻车的环节不是写代码本身,而是一开始就没想清楚该从前端起手还是后端起手。方向一错,后面AI生成的每一行代码都在往错的地方堆。不少人用AI写了三天,回头发现前后端接口全对不上,只能自己动手重写一半以上。
以前交付一个完整的前后端项目,需要产品经理、前端工程师、后端工程师、运维四个角色配合才能推完。而现在,一个人加一个AI编程工具,就有可能把这四个角色的活全部打通。
行业背景:全栈角色重构的本质 传统软件开发的角色分工源于技术复杂度的专业化壁垒:前端需要掌握React/Vue生态、CSS布局、浏览器兼容性;后端需要熟悉数据库设计、API安全、性能优化;运维需要理解容器化、CI/CD、云服务配置。这些知识体系的学习曲线使得一人全栈在工程质量上难以保证。AI编程工具正在压缩这些专业壁垒的学习成本,但并未消除判断力的需求——何时打断AI、如何验证生成代码的正确性、如何设计系统架构,这些仍然需要人的工程经验。因此,AI全栈交付能力的本质是「工程判断力 × AI执行力」的乘积,而非单纯的工具使用熟练度。
这意味着什么?熟练掌握AI编程工具的人,一个人能交付的东西相当于以前一个小团队的产出。但还停留在用AI写写片段代码阶段的人,与前者之间的差距每过一个月都在拉大。本文将拆解如何用Claude Code驱动,从技术调研到部署上线,完整交付一个企业级多模态RAG项目。
技术背景:什么是多模态RAG RAG(Retrieval-Augmented Generation,检索增强生成)是当前企业级AI应用的核心架构范式。它解决了大语言模型的两个根本缺陷:知识截止日期和幻觉问题——模型不再依赖训练时固化的知识,而是在回答时实时检索外部知识库。传统RAG仅处理文本,而多模态RAG进一步整合了图像、表格、PDF等非结构化数据的检索能力,使得企业内部的技术文档、产品手册、财务报表都能成为可检索的知识源。向量数据库(如Pinecone、Weaviate、Chroma)是RAG架构的存储核心,它将文本和图像转化为高维向量,通过语义相似度而非关键词匹配来检索信息,这也是为什么RAG系统能理解「这份合同的违约条款」而不只是搜索「违约」这个关键词。
前端起手还是后端起手:方向选错全盘皆输
这两条路的工作流完全不同,选择哪条路取决于你的项目特征。
前端起手:产品形态已确定
前端起手意味着你已经很清楚这个产品长什么样、用户怎么用。先出UI原型,先把页面交互定死,再反过来搭后端服务来适配它。这种方式适合需求明确、交互复杂的ToC产品。
后端起手:技术可行性待验证
后端起手则是先验证技术能不能跑通。比如你要给公司做一个内部的知识库问答系统,得先把检索链路跑通、接口规范定好,确认这条路走得通,再回过头用PRD去驱动前端。
对于企业级RAG项目,后端起手是更稳妥的选择。因为多模态检索、向量数据库、大模型调用这些核心链路如果跑不通,前端做得再漂亮也是空中楼阁。
工程背景:前后端接口对齐问题的根源 前后端接口不对齐是传统协作开发中最高频的返工原因之一。其根本原因在于前后端开发并行推进时,双方对数据结构、字段命名、错误处理的隐性假设不同步。业界通常用API-First开发方法论来解决这个问题:先用OpenAPI/Swagger定义接口契约,前后端基于同一份契约并行开发,最后联调时只需验证实现是否符合契约。在AI协作开发场景中,这个问题被进一步放大——AI在不同会话中可能生成风格迥异的接口定义。本文提到的「后端驱动前端」策略,本质上是将API-First方法论与AI工作流结合:先用后端MVP确立接口事实标准,再用PRD文档将这个标准传递给前端开发会话,从架构层面消除接口漂移的可能性。
企业级RAG项目完整交付流程
整个项目的交付流程可以拆解为五个关键步骤:
- 技术选型调研:用Claude Code做深度调研,确定技术栈
- 生成规范文档:把架构锁住,为后续AI协作建立一致性底座
- 搭后端MVP:跑通核心链路(检索、问答、多模态处理)
- 输出PRD驱动前端:基于已验证的后端能力设计前端界面
- 前后端联调上线:全程用Claude Code驱动,减少手写代码

这套流程的核心理念是"后端驱动前端"——先确保技术链路跑通,再用产品文档驱动界面开发,最大程度避免前后端接口对不上的问题。
规范文档:AI协作开发的隐藏底座
很多人觉得写文档是浪费时间,代码能跑就行。但在AI协作开发中,规范文档的角色发生了根本性转变——它不是给人看的,它是给AI看的。
为什么规范文档如此关键
用AI做项目有一个绕不开的问题:每次开一个新的会话,AI就是失忆的。它不记得你前面做了什么决策、接口是怎么定义的、架构约束在哪里。结果就是你改了一个模块,它顺手把另一个模块的逻辑也改了,越改越乱。
技术背景:AI会话失忆的本质原因 AI会话失忆问题的技术根源在于大语言模型的无状态性(Stateless)。每次新建会话,模型都从零开始,没有持久化的项目记忆。这与人类开发者的工作方式形成了根本性矛盾——人类工程师会在脑中积累项目上下文,而LLM每次都是「第一天上班」。业界对此有多种解决方案:向量数据库存储会话历史、Memory模块、以及本文提到的规范文档注入法。规范文档注入法的优势在于其确定性——它是人工精心提炼的结构化知识,比自动化的记忆检索更可控、更精准,特别适合需要严格一致性的工程项目。每次开启新会话时,将规范文档作为系统提示词(System Prompt)或首条消息注入,相当于给AI做了一次「项目入职培训」,让它在统一的约束框架下工作。
规范文档在AI协作开发里,是让AI在整个项目周期里保持一致性的底座。有这个文档和没有这个文档,项目的走向完全是两回事。

规范文档应该包含哪些内容
一份合格的AI协作规范文档至少需要覆盖:
- 技术栈约束:明确使用的框架、库版本、数据库类型
- 接口规范:API路径、请求/响应格式、错误码定义
- 架构约束:模块划分、数据流向、依赖关系
- 编码规范:命名规则、目录结构、注释要求
每次开启新会话时,将规范文档作为上下文喂给Claude Code,它就能在统一的约束下工作,而不是每次都在"真空
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。