Claude Code实战:AI接口自动化测试工程化落地指南

Claude Code工程化测试实践:通过驾驭工程让AI可靠地完成接口自动化
文章阐述了AI工具的三大分类,重点介绍Claude Code作为命令行AI工具在工程化测试中的定位。指出让AI生成大量测试代码是错误方式,正确做法是用框架管理用例、让AI维护结构化数据。通过Skill封装和驾驭工程(Harness Engineering)的方法论,建立标准化需求、迭代评审、规则约束等机制,将AI的不确定性控制在工程可接受范围内,实现可靠的自动化测试。
AI工具分类与Claude Code的定位
当前AI工具大致可分为三大类:个人助理类(如ChatGPT、千问等)、IDE集成类(如Cursor、Trae、QCode等)、以及命令行类(如Claude Code、Open Code)。
个人助理类工具的优势在于社交工具集成和日常对话,但对工程化场景并不严谨。IDE类工具集成了AI功能,适合代码编写。而Claude Code这类命令行工具,虽然连界面都没有,却是为工程化而生——纯粹为了完成某件事情而存在。
命令行AI工具(CLI-based AI Agent)代表了一种"无UI优先"的设计哲学。与IDE插件需要适配编辑器API不同,CLI工具直接操作文件系统和Shell环境,天然具备pipeline组合能力,可与grep、sed、git等Unix工具链无缝协作。这种设计使其在CI/CD流水线、远程服务器等无图形界面环境中同样适用,真正实现了"哪里有终端,哪里就能用AI"。
对于程序员和测试人员来说,软件工程是一个严谨的过程,不能容忍"可错也可对"的情况。这正是我们需要学习Claude Code这类工具的核心原因。
环境搭建:Claude Code与IDE的组合使用
实际工作中,单独使用Claude Code的命令行是不够的。推荐的方式是IDE + Claude Code的组合:
- IDE(VS Code/Trae等):适合查看代码、编辑文件、浏览项目结构
- Claude Code:作为顶级的AI Agent工具,在IDE的终端中运行
两者结合的原因很简单:Claude Code改文件、看文件都不方便,而IDE提供了直观的代码浏览能力。在IDE终端中运行Claude Code,既能享受AI的强大能力,又能方便地审查和编辑代码。
关于付费模型的选择,如果预算有限,可以使用MiniMax等国产模型,花一杯奶茶的钱(二三十元)购买Token Plan,每月5小时600次调用基本够学习使用。安装方式支持Windows、Linux、Mac,也可通过NPM方式安装(npm -g),但NPM方式后续可能被取消。
AI接口自动化的常见误区
错误方式:让AI生成大量测试代码
很多人发现AI可以写代码后,就让AI生成Python + PyTest + Request的接口自动化项目——登录、参数提取、依赖处理一应俱全。这种方式能做自动化,但本质上是错误的。
问题在于:
- 难以维护:用例越多、代码越多,维护成本越高。这在编程时代就已经被证明是行不通的方案
- 无法审核:AI写了100行代码,你怎么确定没有埋坑?当接口达到100个时,光审核代码就耗时巨大
- 不确定性:AI生成的代码可能每次都不同,质量参差不齐
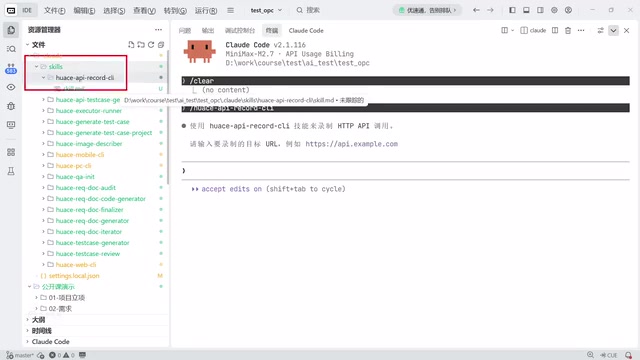
正确方式:让AI维护测试用例而非编写代码
正确的思路是:用框架管理用例,让AI维护用例数据。框架负责执行逻辑,AI负责生成符合框架规格的YAML/CEL格式用例文件。
这里提到的CEL(Common Expression Language)是Google开发的一种轻量级表达式语言,常用于策略规则和数据验证场景。在测试用例管理中,使用YAML描述测试数据结构(接口地址、请求参数、Headers等),CEL描述断言逻辑(如response.status == 200 && response.body.code == 0),可以将测试用例的维护从"编程问题"降维为"数据填写问题"。这样AI生成出错的概率大幅降低——因为它只需要填写结构化数据,而非编写任意形式的程序代码。
接口自动化真正的难点不在于执行——Postman、JMeter、任何成熟框架都能做到。难点在于:
- AI如何知道接口参数的取值来源?
- A接口和B接口的数据依赖关系从哪里获取?
- 接口断言标准如何确定?
- 业务流程如何串联?
工程化落地:Skill开发与工具封装
Skill的本质是什么
Skill本质上是提示词的高级封装。它告诉AI如何使用某个工具、如何完成某个任务。但Skill不是万能的——复杂功能需要封装为独立的CLI工具,Skill只负责告诉AI如何调用这些工具。
Claude Code中的Skill机制类似于LangChain中的Tool定义或OpenAI的Function Calling声明。其本质是通过结构化的提示词模板,定义工具的输入输出schema、调用前置条件和错误处理策略,使AI Agent能够可靠地编排多步骤工作流。例如一个"接口录制"Skill会声明:输入为目标URL,前置条件为录制工具已安装,输出为标准Markdown格式的接口文档,异常时应提示用户检查网络代理配置。
关键原则:
- 简单工具:直接放在Skill中(如一行命令)
- 复杂工具:封装为CLI程序,Skill只描述使用方法
- 版本控制:Skill必须有版本号和升级机制
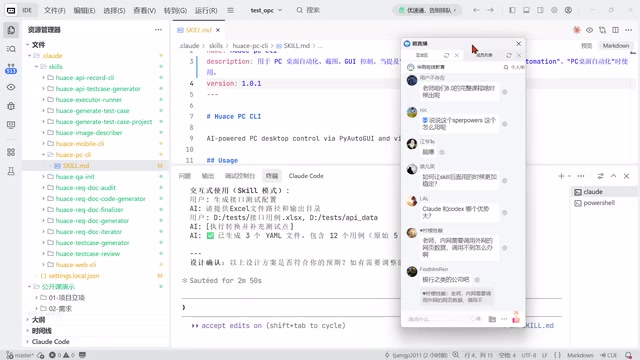
实战示例:接口录制与自动化
以接口录制为例,AI本身不具备抓包能力。解决方案是:
- 开发一个HTTP API录制工具(CLI程序)
- 编写Skill告诉AI如何安装和使用该工具
- AI调用工具启动浏览器,录制接口调用,生成Markdown接口文档
同样的思路适用于PC桌面自动化、移动端自动化、Web自动化——通过AI视觉识别能力,结合本地部署的视觉模型,实现跨平台的自动化操作。
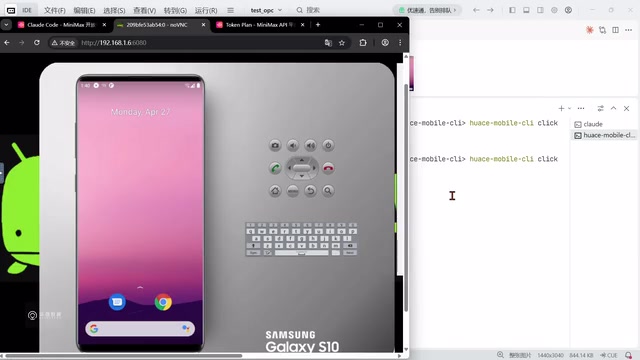
驾驭工程(Harness Engineering):让AI可靠运行
为什么需要驾驭工程
AI的不确定性是最大挑战:
- 第一次生成和第二次生成的结果可能截然不同
- 上午正常、下午可能"降智"
- 本地部署也难以保证完整的模型运行能力
Harness Engineering借鉴了传统软件工程中"约束驱动开发"的思想。类似于类型系统约束代码行为、数据库Schema约束数据格式,驾驭工程通过标准化输入格式、固定输出模板、多轮验证循环来收窄AI的输出空间,将不确定性控制在工程可接受的范围内。这个概念的核心洞察是:与其期望AI每次都生成完美结果,不如设计一套机制让"不完美的结果"能被快速发现和修正。
工程化约束的核心要素
- 需求标准化:将各种格式的需求文档(原型图、Word、PDF、Markdown)规整为AI可理解的标准格式
- 迭代评审:AI分析需求 → 发现问题 → 人工+AI修改 → 新版本 → 再评审,反复打磨
- 接口文档完善:需求文档不完善,测试用例生成就是空谈
- 流程梳理:明确接口依赖关系、业务流程、数据来源
- 规则约束:不是简单的提示词约束,而是工程层面的强约束
完整的工程化流程
需求导入 → 需求标准化 → 需求评审(多轮迭代)
↓
接口文档审核 → 接口依赖梳理 → 流程规范化
↓
工具开发(CLI) → Skill封装 → AI调用执行
↓
用例生成 → 格式约束 → 质量验证 → 测试报告
核心观点总结
AI工具在乎的是使用的人,而不是工具本身。 同样的Claude Code,不同的使用思路产生截然不同的效果。
在AI时代,测试人员的核心竞争力不是"会让AI写代码",而是:
- 能够设计工程化的AI测试体系
- 能够封装AI所需的工具和Skill
- 能够建立约束规则,让AI在可靠范围内工作
- 能够将零散的思路转化为可落地的工程方案
这就是从"AI使用者"到"AI工程师"的本质区别。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。