Claude Code自动生成CRUD代码:Skill文件编写实战指南
通过Skill文件和MCP配置,让Claude Code根据已有表结构高效生成CRUD代码
本文介绍了使用Claude Code配合MySQL MCP服务器和Skill文件自动生成CRUD代码的完整方法。核心思路是自己设计表结构,通过MCP让AI读取数据库元数据,再用精心编写的Skill文件(含分页策略、测试隔离、代码分层等指令)指导AI生成高质量的Model/DAO/Service三层代码。但作者也坦诚指出,对于标准化CRUD场景,AI相比成熟框架工具并未带来明显效率提升。
引言:为什么不能直接让AI设计表结构?
很多开发者在使用AI编程工具时,习惯把整个需求一股脑丢给AI,让它从表设计到代码生成一步到位。但在实际项目中,这种做法往往事倍功半——AI生成的表结构可能字段多了或少了,你需要反复调教,浪费大量时间。
更好的做法是:自己设计好表结构,让AI根据表结构来生成代码。因为表结构本身就代表了你对业务的深入理解,这是AI短时间内无法替代的。本文将详细介绍如何通过Claude Code配合MCP和Skill文件,实现高质量的CRUD代码自动生成。
两个核心准备:MCP与Skill文件
配置MySQL MCP服务器
要让Claude Code能够读取数据库中的表结构,首先需要配置一个MySQL的MCP(Model Context Protocol)服务器。
MCP是Anthropic于2024年底推出的开放协议,旨在为AI模型与外部数据源、工具之间建立标准化的通信桥梁。在MCP出现之前,每个AI工具要访问外部系统(数据库、API、文件系统等)都需要单独编写集成代码,形成了大量的"M×N"适配问题。MCP通过定义统一的客户端-服务器架构,让AI应用(客户端)可以通过标准协议与任意数量的MCP服务器通信,每个服务器封装了对特定外部资源的访问能力。在本文场景中,MySQL MCP服务器充当了Claude Code与数据库之间的中间层,使AI能够像开发者一样执行SQL查询、获取表结构元数据,而无需将数据库凭证直接暴露给模型本身。
配置文件位于用户目录下的 .claude.json,核心内容包括:
- command:MCP服务器的启动命令
- args:启动参数
- env:环境变量,主要配置数据库连接信息(服务器地址、端口、库名、用户名、密码)
配置完成后,Claude Code就能通过MCP直接连接到你的MySQL数据库,执行 SHOW TABLES 等操作来获取表结构信息。
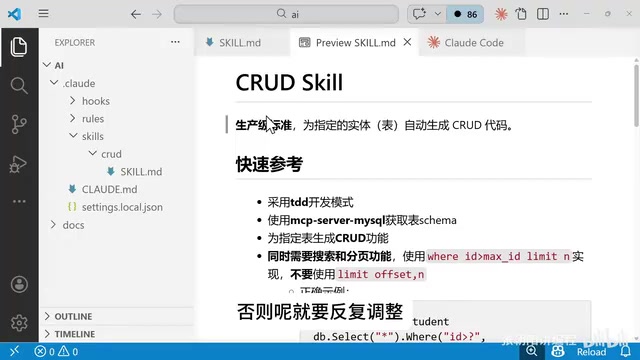
编写CRUD Skill文件(核心中的核心)
Skill文件是整个流程的灵魂。一个写得好的Skill文件,能让生成的代码一遍过;写得不好,就要反复调整。
Skill文件本质上是一种结构化的Prompt Engineering(提示工程)实践。传统的Prompt Engineering通常是在对话中临时编写指令,而Skill文件将这些指令持久化、模块化,存储在项目目录中随项目版本管理。这种做法与业界流行的"System Prompt"理念一脉相承,但更进一步——它支持关键词触发、条件激活,类似于编程中的事件驱动模式。Skill文件的编写质量直接决定了AI输出的可预测性,这也是为什么业界逐渐形成了"Prompt as Code"的理念:将提示词视为代码资产,进行版本控制、Code Review和持续优化。
Skill文件放置在项目根目录下 .claude/skills/crud/skill.md,Claude启动时会自动加载。文件中通过关键词触发机制,当用户输入包含"CRUD"、"实体生成"等关键词时,才会激活该Skill。
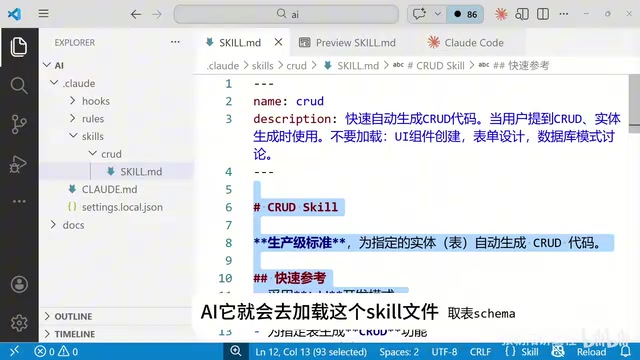
Skill文件中包含了以下关键指令:
- 测试驱动开发模式:先写测试,再写代码
- 分页策略:明确要求使用
WHERE id > maxId LIMIT N而非LIMIT offset, N,因为后者随着offset增大性能会急剧下降 - 连接池共享:所有DAO层代码共用同一个数据库连接池
- 测试隔离:使用SQLite内存数据库运行测试,不污染正式MySQL库
- 代码分层:生成Model、DAO、Service三层代码,避免冗余
深入理解分页性能问题
特别你可能没注意到,为了防止AI不理解分页优化的含义,Skill中专门写了正确示例和错误示例。这种"手把手教AI"的方式非常实用,也是Skill文件编写的核心技巧。
传统的 LIMIT offset, N 分页方式在MySQL中存在严重的深分页性能问题。其根本原因在于MySQL的InnoDB存储引擎处理这类查询时,即使只需要返回N条记录,也必须先扫描并丢弃前offset条记录。例如 LIMIT 1000000, 20 实际上需要扫描1000020行数据,随着页码增大,查询时间呈线性甚至超线性增长。而 WHERE id > maxId LIMIT N 的游标分页方式(也称Keyset Pagination或Seek Method),利用了主键索引的B+树有序性,数据库可以直接通过索引定位到起始位置,时间复杂度始终为O(log N + M),其中M是返回的记录数。这种优化在百万级以上数据量的表中效果尤为显著,查询时间可从数秒降至毫秒级。不过游标分页也有局限性:它不支持随机跳页,只能实现"上一页/下一页"的连续翻页模式,适用于信息流、列表加载等场景。
实际执行流程演示
一句Prompt触发完整CRUD生成
准备工作完成后,只需在Claude Code中输入一句简短的提示:
生成CRUD代码
Claude会自动命中Skill中的关键词,然后按照预设流程逐步执行:
- 列出所有表:通过MCP连接数据库,执行
SHOW TABLES - 用户选择表:交互式多选,比如选择
user和student两张表 - 选择技术栈:询问使用什么语言和框架,这里选择了 Go + Gin + GORM
- 逐表生成代码:从底层到上层,依次生成Model → DAO → Service → Test
- 运行测试并自动修复:发现问题会自动修正代码
生成代码的质量如何?
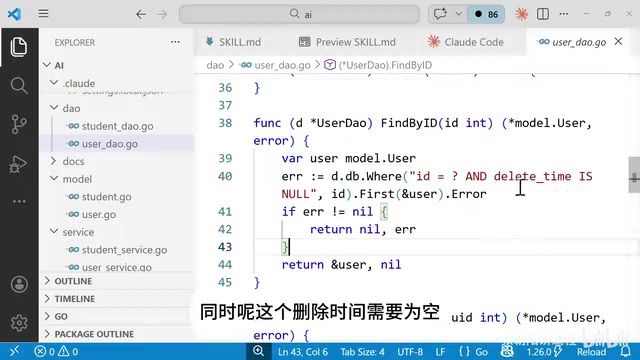
经过人工检查,生成的代码质量相当不错:
Model层:结构体包含完整的JSON tag和GORM tag,每个字段都有对应映射,并指定了真实表名。
DAO层:
Create:调用gorm.DB.Create插入数据Update:调用Save函数更新Delete:根据ID软删除FindById:查询时自动过滤已删除记录(deleted_at IS NULL)- 分页查询:正确使用了
id > maxId的高性能分页方式,支持keyword模糊搜索和city精确筛选
Service层:封装了Request结构体(带JSON tag),负责参数转换后调用DAO层,职责清晰。
测试代码:使用SQLite内存数据库,通过AutoMigrate建表,从Service层往下测试,覆盖了各个CRUD操作,每个断言都检查字段是否符合预期。
测试隔离策略的技术细节
测试驱动开发(Test-Driven Development, TDD)是Kent Beck在2003年系统化提出的软件开发方法论,其核心循环为"红-绿-重构":先编写一个会失败的测试(红),再编写最少量的代码使测试通过(绿),最后重构代码保持整洁。在本文的AI代码生成场景中,TDD不仅是开发方法,更是质量验证机制——AI生成的代码必须通过预设的测试才算完成。
而使用SQLite内存数据库(:memory:模式)做测试隔离是Go生态中的常见实践。SQLite内存数据库的生命周期与进程绑定,测试结束后数据自动销毁,既避免了对MySQL测试库的依赖和数据残留问题,又大幅提升了测试执行速度(内存操作比磁盘I/O快数个数量级)。GORM框架原生支持SQLite驱动,配合AutoMigrate可以根据Go结构体自动建表,使得同一套代码可以在MySQL和SQLite之间无缝切换。
最终执行 go test -v ./ 命令,所有测试全部通过。
效率与成本的冷思考
整个过程耗时约7分半钟。其中第一张表耗时较长(约5分钟),第二张表因为有了模板参考,只用了不到2分钟。
但客观来说,如果是人工操作,简单的CRUD代码其实更快——因为大部分代码都是复制粘贴后简单修改。更不用说Go生态中已有 go-zero、GoFrame 等框架,Java中有Spring等工具,都能自动生成ORM代码。
现有代码生成工具的成熟度
Go语言生态中已有多个成熟的代码生成方案。go-zero是由好未来(TAL)开源的微服务框架,其goctl工具可以根据API定义文件和数据库DDL自动生成完整的CRUD代码、路由、中间件等,覆盖从接口层到数据层的全链路。GoFrame框架的gf gen dao命令同样支持从数据库表结构反向生成Model、DAO和Service代码。此外,GORM官方提供的gen工具可以生成类型安全的查询代码,sqlc则走了另一条路——从手写SQL反向生成Go代码。这些工具经过大量生产环境验证,生成的代码模式固定、性能优化成熟,且执行速度通常在秒级。相比之下,AI生成代码的优势在于灵活性——它可以根据Skill文件中的自定义规范生成非标准化的代码结构,适应团队特有的架构约定,这是模板化工具难以做到的。
"简单的增删改查,AI能够完成任务,但相比之前并没有带来效率提升,而且还花费了更多的钱。"
这个观点值得深思。AI编程工具的真正价值可能不在于这类模式化的CRUD生成,而在于处理更复杂的业务逻辑和非标准化的开发任务。
核心经验总结
- 表结构自己设计:不要让AI猜你的业务需求,表结构是业务理解的精确表达
- Skill文件要详尽:包括正确示例、错误示例、性能要求、架构约束,越具体AI执行越准确
- 测试隔离很重要:用SQLite内存数据库做测试,避免污染生产环境
- 分页性能要明确:
id > maxId比LIMIT offset性能好得多,这类优化经验需要人工注入Skill文件 - 理性看待AI效率:对于标准化CRUD,AI未必比成熟框架工具更快,但Skill文件的编写思路可以复用到更复杂的场景中
核心要点
- 自己设计表结构再让AI生成代码,比让AI从零设计更高效可控
- Skill文件是代码质量的关键,需包含分页策略、连接池共享、测试隔离等详细指令
- 通过MCP连接MySQL数据库,Claude Code可自动读取表结构并交互式生成Model/DAO/Service三层代码
- 使用SQLite内存数据库做测试隔离,不污染正式环境,支持测试驱动开发
- 对于标准化CRUD场景,AI编程工具相比成熟框架并未带来明显效率提升,但Skill编写思路可复用到复杂场景
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。