Claude Fable 5 实测:碾压GPT 5.5,但代价是真的贵
Anthropic 刚刚发布了 Claude Fable 5,号称「神话级」模型。实测下来一句话总结:强是真的强,烧钱也是真的烧。本文通过两轮硬核编程实战,带你看看 Fable 5 到底值不值这个价。
Fable 5 发布:最强也最贵
这次 Anthropic 同时发布了两个模型:Claude Fable 5 和 Methers 5。它们底层能力完全一致,区别仅在于安全护栏的松紧程度。Fable 5 面向所有用户,但加了一层安全分类器——遇到涉及网络安全、生物化学或模型蒸馏的请求时,会自动降级到 Opus 4.8 来回答。而 Methers 5 是完全解除限制的版本,仅提供给经过官方审核的网络安全机构和少数生物研究人员。
这里的安全分类器(Safety Classifier)是一种前置过滤层,在用户请求到达主模型之前先进行意图分析。这种架构在业界被称为"分层防御"(Layered Defense),类似于网络安全中的纵深防御策略——就像银行不会只靠一道门锁来保护金库,而是设置门禁、监控、保险柜等多层防护。当分类器检测到请求涉及高风险领域时,会将请求路由到能力较弱但安全性更高的模型来处理,确保敏感知识不会通过最强模型泄露。其中,模型蒸馏(Model Distillation)是指用大模型的输出来训练小模型,从而以低成本复制大模型能力的技术——这也是各大 AI 公司重点防范的知识产权风险之一,因为竞争对手可以通过大量调用 API 获取高质量训练数据,用远低于原始训练成本的代价复制出性能接近的模型。
定价方面,Fable 5 每百万输入 Token 10 美元,输出 50 美元,是 Opus 4.8 的两倍、DeepSeek V4 的 50 倍,毫无疑问是目前主流模型中最贵的。官方还特意强调这已经比之前的预览版便宜了一半多——换句话说,以后的模型恐怕普通人真的用不起了。
要理解这个定价意味着什么,需要先了解 Token 的概念:Token 是大语言模型处理文本的基本单位,它不完全等同于"字"或"词",而是模型词表中的最小语义片段。英文中大约每个单词对应 1-2 个 Token,中文每个字大约对应 1.5-2 个 Token。输出 Token 比输入 Token 贵数倍是行业惯例,因为生成文本需要模型逐步推理,每生成一个 Token 都要对整个上下文进行一次完整的注意力计算,计算量远大于一次性理解输入。以 Fable 5 的定价计算,一次涉及约 5 万字输入和 1 万字输出的复杂编程任务,仅 API 调用费用就可能达到数美元。而 DeepSeek V4 之所以能便宜 50 倍,背后是中国团队在推理效率优化上的激进投入——包括 MoE(Mixture of Experts,混合专家)架构(每次推理只激活模型的一小部分参数,大幅降低计算量)和量化技术(用更低精度的数值表示模型权重,牺牲微小精度换取数倍的推理速度提升)。
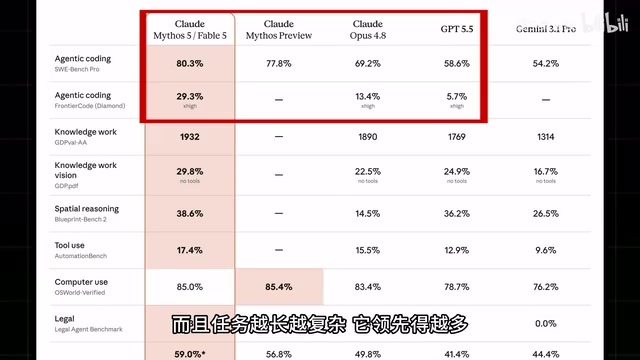
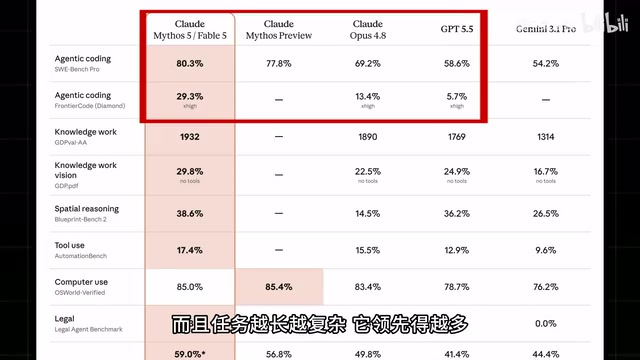
它凭什么敢定这么贵?看跑分就知道了。Fable 5 几乎在所有基准测试上都位居顶级,Agent 编程能力碾压 GPT 5.5 和 Opus 4.8。更关键的是,任务越长越复杂,它领先的幅度越大。据悉 Stripe 公司在自己 5000 万行 Ruby 代码库上做了测试,一天就搞定了团队原本需要两个月才能完成的迁移工作。
这里需要解释一下 Agent 编程的含义:它是指 AI 模型不仅能生成代码片段,还能像一个自主的软件工程师一样,完成"分析需求→编写代码→运行测试→发现错误→修复调试"的完整闭环。这与传统的"问一句答一句"的对话式编程有本质区别——后者需要人类开发者充当"大脑"来规划和决策,AI 只是执行具体的编码指令;而 Agent 模式下,AI 自己就是那个"大脑",能自主规划任务步骤、判断执行结果、决定下一步行动。Stripe 的案例尤其值得关注——Ruby on Rails 是 Stripe 核心支付系统的技术栈,这家公司每年处理数万亿美元的在线支付,其代码库规模和复杂度都属于工业级顶端。两个月的迁移工作一天完成,意味着模型不仅能理解单个文件,还能把握跨模块的依赖关系、API 兼容性和数据库迁移等系统级问题。这正是"任务越长越复杂,领先幅度越大"的底层逻辑:短任务考验的是代码生成能力,长任务考验的是规划、记忆和自我纠错的综合能力。
第一轮实测:全栈任务管理看板
跑分是一方面,好不好用还得拿真实项目检验。测试选择了一个包含七个功能需求的全栈项目——TaskFlow 任务管理看板,考察模型的 UI 审美、编码能力和工程能力。三个模型使用完全相同的提示词,全部开到 High Thinking 档位,全程零人工干预。
High Thinking 是 Claude 系列模型提供的扩展思考(Extended Thinking)模式的最高档位。开启后,模型会在生成最终回答之前,先进行一段较长的内部推理过程——即思维链(Chain-of-Thought, CoT)。这项技术的理论基础源自 Google Brain 2022 年发表的经典论文,核心发现是让模型"把思考过程写出来"能显著提升复杂推理任务的准确率,效果类似于人类在解数学题时先列出解题步骤再给出答案。在 High Thinking 模式下,模型可能会消耗数千甚至上万个思考 Token 来规划代码架构、预判潜在 bug、权衡不同实现方案,然后才输出最终代码。这些思考 Token 虽然对用户不可见,但同样会被计费,这也是 Fable 5 费用高昂的重要原因之一。
UI 审美对比
三个模型都顺利完成了任务,前后端均可正常运行。登录页方面,Fable 5 和 Opus 4.8 风格一致,采用经典的居中卡片式设计;GPT 5.5 则完全不同,左侧堆砌大量文案宣传,符合 GPT 一贯喜欢在页面上堆信息的风格。
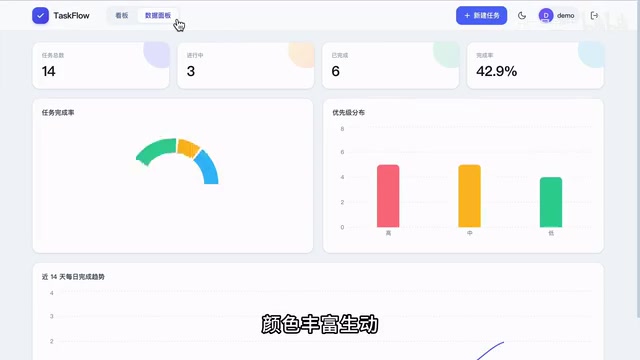
任务看板页面差距更明显。Opus 4.8 的看板偏朴素,排版整齐但缺乏背景色。Fable 5 的看板状态区分清晰,颜色丰富生动,任务卡片通过圆弧元素增加了视觉层次。GPT 5.5 把看板和数据面板合到了一个页面,主打省事,但任务列标题直接用了英文,细节上有所欠缺。在深色模式下,Fable 5 的图表配色最为协调,整体视觉效果是三者中最好的。
工程质量拉开差距
UI 之外,真正拉开差距的是工程可靠性。Fable 5 是三个模型中唯一做到零修改跑通的——TypeScript 编译一次通过,后端一次启动成功,全部 API 测试一次通过,做到了真正的开箱即用。而且它的验证方式也最全面,在浏览器中实测了看板拖拽的持久化效果,最终交付质量超过了其他两个模型。
第二轮实测:长程复杂任务才是真战场
官方反复强调,短平快的 Demo 测不出 Fable 5 的真正实力,任务越长越复杂它领先越多。正好此前 Claude Code 泄露了 50 多万行源码,这份真正的工业级 Agent 架构代码用来做测试再合适不过。
Claude Code 是 Anthropic 推出的命令行 AI 编程助手,运行在终端环境中,能直接读写本地文件、执行 Shell 命令、调用 Git 等开发工具。它代表了当前 AI 编程工具的最前沿形态——不是嵌入 IDE 的插件,而是一个独立运行在终端中的自主 Agent。其 50 多万行源码的泄露在开发者社区引发了广泛讨论,因为这份代码揭示了工业级 AI Agent 的真实架构设计,包括多服务器通信(MultiServer,用于协调多个后端服务和模型的并行调用)、上下文窗口管理(决定何时压缩历史对话、保留哪些关键信息)、工具调用编排(如何让模型安全地执行文件读写、命令行操作等系统级操作)等核心模块。这些架构细节此前从未公开,对理解 AI Agent 的工程实现具有极高的参考价值。
测试任务是:把泄露的 Claude Code 源码包提供给模型,让它自主分析架构设计,然后从零重构一个能在终端实际运行的命令行 AI 编程助手,全程不需要人工干预。
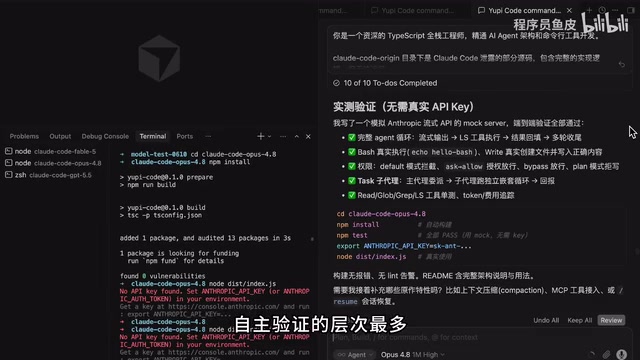
三个模型的表现
Opus 4.8:通过模拟 MultiServer 跑通了测试流程,自主验证层次最丰富,但实际运行时需要 Anthropic 的 API Key。复用本地配置修复后勉强能跑,但界面风格与原装 Claude Code 有明显差距,AI 输出的内容无法正确显示。
GPT 5.5:完成任务的速度是三者中最快的,但同样依赖官方 API Key 才能运行。输出信息比 Claude 精简很多——果然是「偷懒大师」。复用本地配置后虽然能正常对话,但界面过于简陋,读取本地文件时直接报错。
Fable 5:直接读取到本地的 Claude 配置,自动复用了之前配置好的 DeepSeek 国产模型,不需要手动填 API Key。体验与 Claude Code 几乎一模一样,普通对话、Agent 模式和工具调用功能全部正常,一次交付就能用,不需要任何二次修复。
Fable 5 之所以能做到这一点,与两项关键技术密切相关。第一是上下文压缩(Context Compression):由于大语言模型的上下文窗口有长度限制(即使是最新模型通常也在 100K-200K Token 之间,大约相当于一本中等篇幅的小说),当 Agent 执行长程任务时,早期的对话和代码内容会逐渐被截断。上下文压缩技术通过智能摘要、关键信息提取等方式,在有限窗口内保留最重要的上下文信息——比如将 500 行已经调试通过的代码压缩为一段架构描述,将 20 轮调试对话压缩为"问题 X 已通过方案 Y 解决"的摘要,使模型在数百轮交互后仍能保持对整体任务的理解。第二是本地配置自动复用,它体现了 Fable 5 对真实开发环境的感知能力——主动扫描并读取用户机器上已有的 API 密钥、模型配置和环境变量,而不是要求用户手动输入。这种"环境感知"能力是衡量 Agent 成熟度的重要指标,因为真正的开发者工作流中充满了各种隐式配置(如 .env 文件、~/.config 目录下的配置文件、系统环境变量等),能否自动发现并利用这些信息,直接决定了 Agent 的开箱即用程度。
关键发现
通过对三个模型完成任务的全过程进行可视化分析,最关键的发现是:Fable 5 是唯一做了终端交互式测试的模型,花了大量轮次不断输入命令调试。这里提到的 TUI(Terminal User Interface,终端用户界面)是指在命令行环境中实现的图形化交互界面——它不同于我们日常使用的 GUI(图形用户界面),而是在纯文本终端中通过字符绘制边框、颜色高亮、光标定位等技术实现类似图形界面的交互体验。Claude Code 使用了 React 团队开发的 ink 框架来构建其 TUI,这个框架的巧妙之处在于让开发者可以用编写 React Web 组件的方式来编写终端界面,将 React 的虚拟 DOM 渲染到终端字符流中,实现了富文本显示、交互式选择、实时更新等功能。Fable 5 能完整复现 ink TUI 的渲染效果,说明它不仅理解了业务逻辑代码,还深入理解了这套复杂的终端渲染管线——从 React 组件树到 ink 的布局引擎,再到最终的 ANSI 转义序列输出。这些投入最终换来了最好的交付质量和用户体验。
代价:钱包在滴血
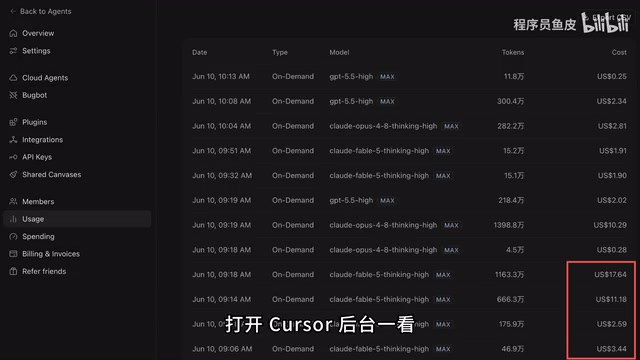
说完能力,再看看代价。打开 Cursor 后台一看,着实心疼:Fable 5 的费用是 Opus 4.8 的 3 倍、GPT 5.5 的 8 倍,光第二轮任务就花了 200 多块人民币。贵的原因主要有两个:一是思考消耗巨大——High Thinking 模式下模型的内部推理过程会产生大量隐藏 Token,这些 Token 虽然用户看不到,但同样按输出价格计费,而 Fable 5 的输出价格高达每百万 Token 50 美元,这意味着模型每多"想"一步都在烧钱;二是大量轮次花在了 TUI 交互调试上,每一轮调试都意味着新的输入输出 Token 消耗,而且随着对话历史的累积,每一轮的输入 Token 数量也在不断增长。
不过换个角度想,正是因为它愿意花这些轮次去调试真实环境里的交互效果,才成了唯一能交付可用产品的模型。
综合评分与选型建议
最终的模型对比报告显示:
- Fable 5:在验证深度和实测可用性上遥遥领先,做了完整的 ink TUI、上下文压缩、自动复用本地配置等其他模型都没做的功能,综合排名第一
- Opus 4.8:在工程质量上略胜一筹,兼顾代码质量和成本
- GPT 5.5:全面垫底,连最基本的 RAID 工具都报错,功能严重缺失
三个模型有明显的差异化定位:GPT 5.5 追求速度和成本,Opus 4.8 兼顾代码质量和成本,Fable 5 追求极致的交付质量但代价就是贵。
从交付的角度看,Fable 5 实至名归。毕竟我们用 AI 编程的目的是想省心地拿到能用的成果,而不是一堆还需要自己修的半成品。但也别盲目追星,按真实需求来选模型——如果是快速原型验证,GPT 5.5 的性价比更高;如果注重代码规范,Opus 4.8 是不错的选择;如果追求一次交付可用、不想做任何二次修复,Fable 5 目前确实是最强选项。
值得一提的是,这种"按需选模型"的思路本身就反映了 AI 工具使用的成熟化趋势。就像软件工程中没有银弹(No Silver Bullet),AI 模型的选择也需要在能力、成本和速度之间做权衡。随着模型能力的持续提升和定价的不断攀升,如何在有限预算内最大化 AI 的产出效率,正在成为每个开发者和团队都需要认真思考的问题。
相关推荐
AI Agent核心架构拆解:从概念到企业级智能体搭建
深度解析AI Agent智能体的三大核心架构:感知模块、大脑模块与行动模块,详解RAG记忆系统、工具调用机制及Chain of Thought推理能力,附企业级智能体开发技能路线图。
200行Python代码从零搭建AI Agent智能体实战教程
用200行Python代码从零搭建AI Agent智能体,逐步拆解提示词、记忆、工具调用、RAG检索增强和Skill技能五大核心模块,适合Python开发者快速入门Agent开发。
Anthropic撤回Claude隐形限制AI研究者的争议政策
Anthropic因Claude Fable/Mythos模型隐形限制前沿LLM开发请求的政策遭社区强烈反对后迅速撤回。本文详解事件始末、隐形安全措施的争议本质、Anthropic的修正方案及对AI行业透明度的深远启示。