Claude Fable 5实测:Token翻倍值不值?Rust编程对比Opus 4.8
引言:Fable 5来了,但值得切换吗?
Anthropic刚发布Opus 4.8没多久,紧接着又推出了第五代模型家族中的新成员——Fable 5。根据官方说明,这个模型在工作时会消耗两倍于Opus的Token数量。这就引出了一个非常实际的问题:性能提升是否足以补偿翻倍的Token消耗?
在大语言模型的使用中,Token是计算成本的基本单位。一个Token大约对应英文中的4个字符或中文中的1-2个汉字。当Anthropic说Fable 5消耗两倍Token时,这意味着模型在内部推理过程中会进行更多的"思考步骤"——这种机制通常被称为"扩展思维"(Extended Thinking)或"思维链"(Chain of Thought)。模型会在生成最终答案前,先在内部进行大量的推理和自我验证,这些中间推理步骤都会消耗Token。对于按Token计费的API用户来说,这直接意味着成本翻倍。
一位专注于AI编程的B站UP主通过一个Rust语言的模拟项目,对Fable 5和Opus 4.8进行了正面对比测试。结论出乎很多人的意料。
测试环境与任务设计
如何在Claude Code中启用Fable 5
要在Claude Code中使用Fable 5,需要先将Claude Code更新到最新版本,只需执行一个简单的cloud update命令即可。更新完成后,在模型选择界面就能看到Fable 5选项。你可能没注意到,Anthropic在选择界面再次提醒用户:该模型的Token消耗是Opus的两倍。
测试任务:Rust模拟项目
为了公平对比,UP主专门设计了一个新任务——用Rust语言创建一个模拟程序。这个任务有几个关键特点:
- 语言要求:必须使用Rust编写(对模型的代码能力是较高挑战)
- 参数复杂度:需要支持大量可配置参数
- 有参考实现:UP主此前已经手动完成过一个参考版本,可以作为评判基准
选择Rust作为测试语言具有特殊的评估价值。Rust是一门以内存安全和零成本抽象著称的系统级编程语言,由Mozilla Research于2010年发起开发。与Python或JavaScript不同,Rust拥有严格的所有权系统(Ownership System)、借用检查器(Borrow Checker)和生命周期(Lifetime)机制,编译器会在编译阶段就拒绝存在内存安全问题的代码。这意味着AI模型生成的Rust代码必须通过极其严格的编译检查才能运行,任何对内存管理的疏忽都会导致编译失败。因此,Rust代码能否一次编译通过,是衡量AI编程能力的高标准测试。
这个任务已被添加到UP主的公开仓库中,感兴趣的开发者可以自行实验。
Fable 5 vs Opus 4.8:对比测试全过程
第一步:规划阶段对比
两个模型都被要求先进入Planning Mode(规划模式),为项目创建实现计划。
Planning Mode是Claude Code中的一项重要功能,它要求模型在动手写代码之前,先制定一份详细的实现计划。这一设计理念源自软件工程中的"先设计后实现"原则。在实际的AI辅助编程中,规划阶段的质量往往决定了最终代码的架构合理性。一个好的规划应该包含模块划分、数据结构设计、接口定义和实现顺序等要素。规划过于简略可能导致实现时缺乏方向,而规划过于冗长则可能包含冗余信息,反而增加理解成本。
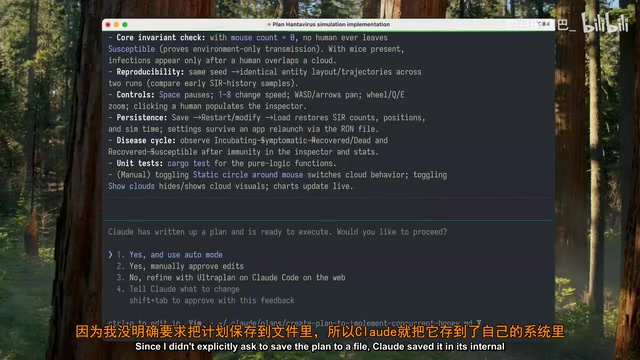
Opus 4.8的表现:
- 在规划过程中主动提出了几个澄清性问题
- 几分钟后完成了计划
- 计划整体结构清晰,虽然不够详细但组织良好
- 将计划保存在了内部文件夹中
Fable 5的表现:
- 生成的计划包含更多技术细节
- 计划长度是Opus版本的两倍以上
- 但在结构性和可读性上,UP主认为不如Opus的版本
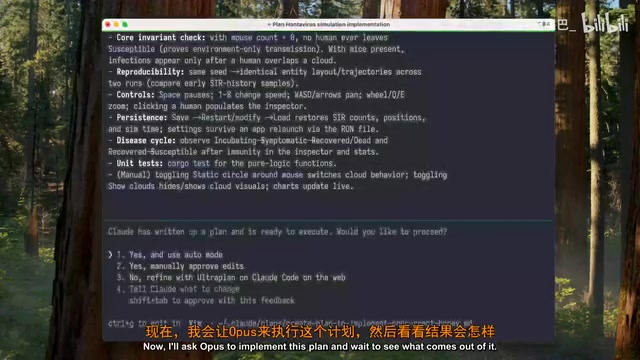
有趣的是,两个模型生成的计划差异明显,这至少说明Fable 5并非简单地在Opus基础上套了一层壳。这次测试中两个模型在规划风格上的差异,恰好反映了AI模型在"深度思考"和"简洁表达"之间的不同权衡策略。
第二步:代码实现阶段
规划完成后,两个模型分别被要求按照各自的计划实现项目。实现过程中主要是自动化的代码生成,偶尔需要用户授权某些操作权限。
意外插曲:Fable 5的稳定性问题
UP主在视频后期编辑时透露了一个重要细节:他最初在Fable 5发布几小时后就完成了测试。但当他第二天想要重新测试并补充视频细节时,Fable 5拒绝执行同样的任务。
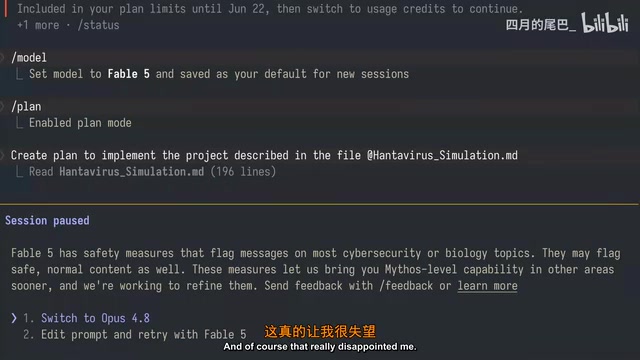
由于项目描述文件并未修改,UP主怀疑是Anthropic在模型发布后调整了内置的安全规则。这一现象反映了AI行业中一个普遍存在的实践——模型上线后的持续安全调优。大型语言模型在发布后,运营团队会根据真实用户的使用数据,持续监控和调整模型的安全过滤规则(通常称为Safety Filter或Guardrails)。这些规则决定了模型会拒绝哪些类型的请求。由于"模拟"(Simulation)这个词在某些语境下可能触发安全过滤器(例如涉及疾病传播模拟、武器模拟等敏感场景),Anthropic可能在发布后收紧了相关规则。这种动态调整虽然是出于安全考虑,但对开发者来说意味着工作流程的不可预测性——昨天能运行的提示词今天可能被拒绝,这是当前AI工具在生产环境中面临的一个实际挑战。
这个问题让UP主对Fable 5的使用意愿大幅下降。不过,由于第一天的测试确实成功完成了,他仍然基于首次测试结果进行了对比。
最终输出结果对比
Opus 4.8的输出
- ✅ 编译:一次通过,无错误
- ✅ 功能完整性:模拟正常运行,所有要求的控制参数都已实现
- ⚠️ 视觉效果:感染云的尺寸比预期大很多(但容易修复)
- ⚠️ UI美观度:界面较为粗糙,但作为第一版可以接受
Fable 5的输出
- ✅ 编译:同样一次通过,无错误
- ✅ 功能完整性:模拟正常运行,所有必需的设置项都已包含
- ✅ 视觉效果:感染云和整体模拟效果看起来更好
- ⚠️ 差距有限:虽然整体优于Opus,但差异并不显著
值得注意的是,两个模型生成的Rust代码都实现了一次编译通过。考虑到Rust编译器的严格程度,这一结果本身就说明当前顶级AI模型在代码生成方面已经达到了相当高的水平。
总体来看,Fable 5的输出质量确实略胜一筹,但提升幅度远未达到"翻倍"的程度。
核心结论:Token翻倍,效果远未翻倍
日常编程使用不推荐切换
UP主的最终判断非常明确:对于日常编程任务,从Opus 4.8切换到Fable 5不值得。理由如下:
- 性能提升有限:在Rust模拟项目中,Fable 5的输出质量仅略优于Opus 4.8,差距远不足以证明两倍Token消耗的合理性
- 稳定性存疑:模型发布后短时间内就出现了拒绝执行任务的情况,暗示Anthropic可能还在调整模型的行为边界
- 性价比不高:对于大多数日常编程场景,Opus 4.8已经足够胜任
Fable 5可能的适用场景
不过,UP主也指出了Fable 5可能有价值的使用场景:当Opus无法完成某个任务时,可以尝试用Fable 5来攻克。换句话说,Fable 5更适合作为"备用重炮",而非日常主力工具。
这种"用更多计算换更好结果"的产品思路,与OpenAI的o1/o3系列模型的设计哲学类似——后者同样通过在推理阶段投入更多计算来提升复杂任务的表现,但代价是更高的延迟和成本。从行业趋势来看,这类"重推理"模型正在成为各大AI公司的标配产品线,但它们的定位更多是解决高难度问题的专用工具,而非替代通用模型的全能选手。
对开发者的启示
这次实测对比给我们几个重要启示:
- 更多Token ≠ 更好结果:模型消耗更多计算资源并不意味着输出质量成比例提升,尤其在结构化编程任务中。这一现象在机器学习领域被称为"收益递减"(Diminishing Returns),即当计算投入超过某个阈值后,性能提升的边际效益会急剧下降
- 模型选择要看场景:没有一个模型适合所有场景,合理的策略是根据任务难度选择不同模型
- 新模型需要观察期:刚发布的模型可能存在规则调整和稳定性问题,不建议立即全面切换
- 规划能力同样重要:在这次测试中,Opus虽然规划更简洁,但结构更清晰,最终实现效果也不差,说明"详细"不等于"更好"
对于大多数开发者来说,目前继续使用Opus 4.8作为主力模型,在遇到瓶颈时再尝试Fable 5,可能是最务实的策略。
核心要点
相关推荐

托管Agent时代来临:Anthropic与Google的两条路线之争
深度解析Anthropic与Google托管Agent的架构差异、定价策略与选型建议。托管Agent将Agent运行时从基础设施工作中解放出来,成为AI基础设施的新产品品类。
零基础搭建Claude Code开发环境:安装配置避坑指南
详细记录零基础用户从安装VS Code到配置Claude Code的完整流程,涵盖插件安装报错、API配置、模型切换等常见问题的解决方案,帮助新手快速上手AI编程工具。
AI召唤力:零代码用AI开发游戏的启示与实践
一位没有编程经验的UP主,仅凭自然语言提示词用AI开发出完整游戏。本文解析AI召唤力的核心维度,探讨零代码开发如何打破游戏开发工种壁垒,以及AI协作能力对产品经理、开发者和普通人的深刻启示。