Claude Haiku 4.5实测:编程能力接近Sonnet 4,成本仅三分之一
Claude Haiku 4.5以极低成本实现接近旗舰模型的编程能力
Anthropic发布Claude Haiku 4.5,编程性能接近旗舰模型Claude 4,价格仅为其三分之一。SWE Bench成绩73.3%,工具调用和计算机使用能力超越Sonnet 4。实测表现稳定,性价比突出,适合日常开发任务。此前Anthropic削减高端模型配额疑似为推广该模型铺垫。
概述:Anthropic的策略性发布
Anthropic近日发布了Claude Haiku 4.5模型,官方宣称其编码性能接近五个月前的旗舰模型Claude 4,但价格仅为三分之一,速度提升一倍多。结合近期Anthropic大幅削减算力配额的背景,这次发布显然是一次有预谋的产品策略——先制造痛点,再提供高性价比方案。
Anthropic在发布Haiku 4.5前大幅削减了Pro订阅用户的Sonnet和Opus模型使用配额,许多用户反映日常使用量被压缩了50%以上。这种"先制造痛点再提供解决方案"的策略在SaaS行业并不罕见——通过限制高端产品的免费/低价使用量,引导用户转向性价比更高的替代方案,或升级到更高价格的订阅层级。这也反映出大模型公司在烧钱竞赛中面临的商业化压力,需要在用户体验和运营成本之间寻找平衡点。
基准测试表现亮眼
Haiku 4.5在SWE Bench上取得了73.3%的成绩,略高于Sonnet 4,接近GPT-5 Codex水平。SWE Bench(Software Engineering Benchmark)是由普林斯顿大学研究团队开发的一项标准化评估基准,专门用于测试AI模型解决真实世界GitHub issue的能力。它从12个流行的Python开源项目中提取了2294个真实的bug修复任务,要求模型在理解问题描述后自主修改代码库来解决问题。73.3%的成绩意味着模型能够独立解决近四分之三的真实软件工程问题,这在一年前还是不可想象的水平。
具体亮点:
- Agent Coding评分高出Claude 4约5个百分点
- 代理工具使用达83%,远超Claude 4的9.6%
- 计算机使用50.7%,超越Sonnet 4的42.2%
- 安全性评估中表现出最低的不对齐行为率
其中,Agent Coding指的是AI模型以自主代理(Agent)模式运行时的编程能力,即模型不仅生成代码片段,还能自主规划任务、读取文件系统、执行命令、调试错误并迭代改进。代理工具使用(Tool Use)评分衡量的是模型调用外部工具(如文件读写、终端命令、浏览器操作等)的准确性和效率。Haiku 4.5在工具使用上达到83%而Claude 4仅9.6%,这一巨大差距表明新模型在理解何时以及如何调用工具方面有了质的飞跃,这对于构建自主编程助手至关重要。
说个细节,Alignment(编程工具)也将Haiku 4.5纳入其软件中,评估显示其表现达到Sonnet 4.5的90%。Alignment是一款专注于AI辅助编程的开发工具平台,它通过标准化的代码生成任务来评估不同模型的实际编程表现。当评估显示Haiku 4.5达到Sonnet 4.5的90%表现时,这意味着在实际软件开发工作流中,使用成本更低的Haiku 4.5仅会损失约10%的代码质量,但能节省大量API调用费用。第三方独立评估的加入为官方基准测试提供了重要的交叉验证。
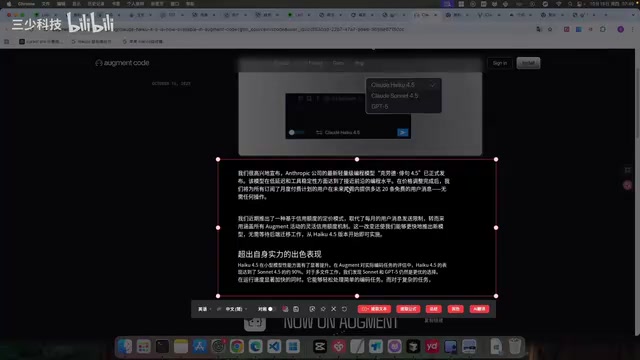
实际编程测试对比
视频作者使用Claude Code分别以Haiku 4.5、Sonnet 4.5和Opus 4.1完成三个编程任务:
天气卡片
Haiku 4.5样式较简单但功能完整,动画效果正常;Sonnet 4.5样式更好但存在动画bug;Opus 4.1效果最佳。
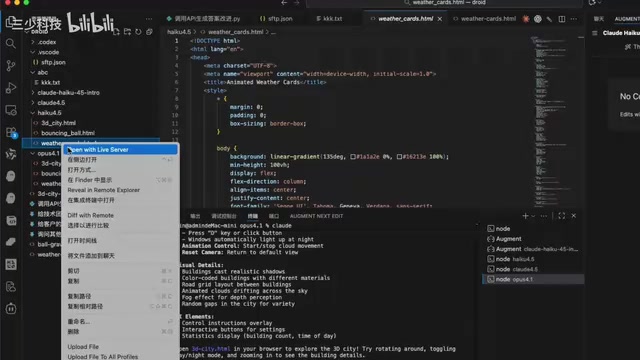
小球掉落物理模拟
Haiku 4.5的小球带弹力效果,表现不错;Sonnet 4.5反而不如Haiku;Opus 4.1物理效果最真实。
3D场景渲染
Haiku 4.5功能正常但美观度一般;Sonnet 4.5生成的场景无法交互,完败;Opus 4.1效果堪称完美,含白云、窗户细节和昼夜切换功能。
性价比分析
综合来看,Haiku 4.5在编程能力上确实接近甚至某些场景超越Sonnet 4,而成本仅为Opus 4.1的十几分之一。Anthropic采用三层模型架构:Haiku(轻量快速)、Sonnet(平衡型)和Opus(旗舰型),这种分层策略类似于OpenAI的GPT-4o mini/GPT-4o/o1系列。Haiku 4.5的输入价格为每百万token 0.80美元,输出为4美元;而Opus级别模型的输入价格可达15美元/百万token,输出75美元/百万token。对于高频调用的开发场景,这种十几倍的价格差异意味着月度成本可能从数千美元降至数百美元,这对中小型开发团队和独立开发者具有决定性意义。
对于日常开发任务,Haiku 4.5提供了极具竞争力的性价比选择。复杂多文件项目仍建议使用Sonnet或GPT-5,但简单到中等复杂度的编码任务,Haiku 4.5完全够用。
核心要点
- Claude Haiku 4.5价格为Claude 4的三分之一,速度提升一倍,编程能力接近Sonnet 4
- SWE Bench成绩73.3%,在计算机使用和工具调用上甚至超越Sonnet 4
- 实测中Haiku 4.5在3个编程任务中表现稳定,某些场景优于Sonnet 4.5
- Opus 4.1效果最佳但成本高出十几倍,Haiku 4.5性价比突出
- Anthropic此前削减算力配额疑似为推广Haiku 4.5做铺垫
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。