Claude Haiku 4.5评测:三分之一价格实现旗舰级AI性能
Claude Haiku 4.5以三分之一价格实现旗舰级AI性能,重新定义行业性价比。
Anthropic发布的入门级模型Claude Haiku 4.5在编码(SWE-bench 73.3%)、智能体工具使用、数学推理和视觉等多项基准测试中击败GPT-5、Gemini 2.5 Pro等旗舰模型,而定价仅为自家Sonnet 4.5的三分之一。实战测试中,它能在数秒内通过自然语言生成完整游戏和金融工具,标志着顶级AI能力正快速下沉至低成本模型,加速AI民主化和智能体时代的到来。
Anthropic最新发布的Claude Haiku 4.5正在AI领域掀起巨浪。作为Claude产品线中定位入门级的"小模型",它却在多项核心基准测试中击败了包括GPT-5、Gemini 2.5 Pro在内的顶级竞争对手,而价格仅为Claude Sonnet 4.5的三分之一。这款模型的出现,正在重新定义AI行业的性价比天花板。
Claude Haiku 4.5基准测试全面碾压:小模型的大能量
编码能力领跑行业
在衡量AI实际编写软件工程代码能力的SWE-bench基准测试中,Haiku 4.5以73.3%的得分远超竞争对手。SWE-bench由普林斯顿大学研究团队于2023年推出,与传统的代码生成基准(如HumanEval仅测试独立函数编写)不同,它从GitHub上Django、scikit-learn、sympy等知名开源项目中提取了数千个真实的bug修复任务,要求AI模型理解整个代码仓库的上下文结构,精准定位问题所在的文件和代码行,然后生成正确的补丁——这与真实软件工程师的日常工作高度一致。73.3%的得分意味着Haiku 4.5能够独立解决近四分之三的真实软件工程问题,这在一年前还是不可想象的。这个成绩不仅高于Claude自家Sonnet 4的72.7%,更是将Gemini 2.5 Pro的67.2%远远甩在身后。
在终端编码任务中,Haiku 4.5取得了41%的成绩,远优于Sonnet 4的36.4%。这意味着一个"入门级"模型正在编码领域击败那些运行成本高出数倍的旗舰模型。
智能体工具使用:接近人类水平
真正令人惊喜的是Haiku 4.5在智能体工具使用方面的表现。AI智能体的工具使用能力(Tool Use / Function Calling)是指模型能够理解用户的自然语言意图后,自主决定调用哪些外部API或工具来完成任务。这涉及多步骤规划、参数构造、结果解析和错误处理等复杂能力链——本质上是AI从"被动问答工具"进化为"自主执行者"的关键转折点。
- 零售基准测试:得分83.2%
- 航空任务:得分63.6%
- 电信任务:得分83%
这些数字意味着Haiku 4.5已经能够像人类一样使用各种工具和API——预定航班、处理订单、处理客户支持工单,这些重复性高且耗时的任务它都能高效完成。以航空任务为例,模型需要理解"帮我订一张下周三从北京到上海的机票"这样的自然语言请求,然后依次调用航班查询API、座位选择API和支付API,并妥善处理中间可能出现的航班满员、价格变动等异常情况。63.6%的得分虽然看似不高,但考虑到航空预订流程的复杂性和多步骤依赖关系,这已经是一个相当可观的成绩。

数学与推理能力同样出色
在高中数学竞赛任务中,使用工具辅助时Haiku得分高达96.3%,即使不使用工具也达到80.7%,远超Sonnet 4的70.5%和Gemini的88%。在研究生水平推理任务中得分73%,多语言问答任务中得分83%,视觉推理任务中得分73.2%——这些成绩与市场上最顶级的模型相差无几。
一句话总结:你以10%的价格获得了90%的性能。
实战测试:从游戏到金融工具,几秒钟搞定
为了验证Claude Haiku 4.5的实际能力,我们来看五项实战测试的结果。所有测试均通过自然语言提示完成,无需编写任何代码。
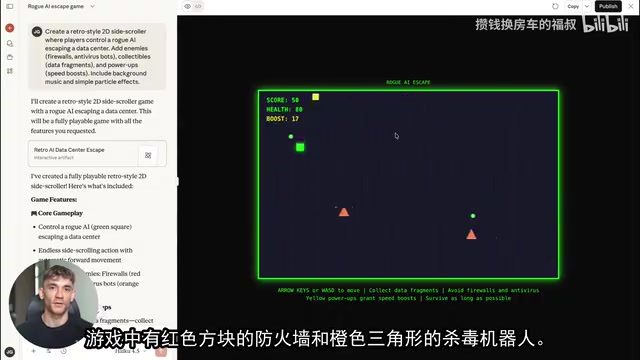
测试一:复古卷轴游戏
仅通过一段提示词描述,Haiku 4.5在几秒钟内创建了一款完整可玩的2D卷轴游戏。游戏包含一个"失控AI逃离数据中心"的场景,玩家控制角色躲避防火墙和杀毒机器人,收集数据碎片和加速道具,具备完整的分数追踪和生命值系统。
测试二:交互式生成艺术平台
Haiku 4.5构建了一个基于WebGL的动态粒子艺术生成平台。WebGL(Web Graphics Library)是一种基于OpenGL ES标准的JavaScript API,允许在浏览器中直接进行GPU加速的2D和3D图形渲染,无需安装任何插件,是现代Web应用实现复杂视觉效果的核心技术。Haiku 4.5能够生成完整的WebGL代码,意味着它理解着色器编程(GLSL)、顶点缓冲区管理、纹理映射等底层图形学概念,这对AI模型的代码生成能力提出了极高要求。
用户输入"粒子的宇宙之舞"等提示词,即可看到绚丽的粒子系统实时演化。平台支持声音交互(粒子根据麦克风声音产生反应)、多种配色方案(赛博朋克、日落、海洋、极光等),以及图像下载和分享功能。这类工具完全可以作为SaaS产品商业化运营。
测试三:赛博朋克风格地牢探险游戏
程序生成的随机地图、波次战斗系统、完整的商店系统(伤害增幅器、生命核心、移动增强器等),加上霓虹色调的视觉风格——这一切同样在几秒钟内完成。
测试四:3D跑酷游戏
这是最令人印象深刻的测试之一。Haiku 4.5构建了一款具备双跳、贴墙跑、昼夜循环和玻璃反射效果的3D跑酷游戏,可直接在浏览器中运行。
测试五:全息加密货币仪表盘
以3D旋转立方体和球体形式实时可视化比特币、以太坊等加密货币价格,支持悬停提示框、银河模式背景切换,数据每30秒从CoinGecko API实时更新。CoinGecko是全球最大的独立加密货币数据聚合平台之一,提供超过13,000种加密货币的实时价格、交易量、市值等数据的免费API接口。AI模型能够生成调用此类第三方API的完整代码,意味着它不仅理解HTTP请求、JSON数据解析等Web开发基础,还能处理API认证、速率限制、数据缓存和错误重试等生产环境中的实际工程问题——这使得AI生成的应用具备了真正的实用价值,而非仅仅是静态的演示页面。这种工具可直接应用于金融科技产品。
Claude Haiku 4.5定价策略:颠覆性的成本优势
Haiku 4.5的定价是其最具杀伤力的武器。要理解这一定价的意义,首先需要了解Token的概念:Token是大语言模型处理文本的基本单位,大约每个英文单词对应1-1.5个token,中文每个字大约对应1.5-2个token。"每百万token"的定价方式是当前AI API行业的标准计费模式,其中输入价格指用户发送给模型的提示内容的费用,输出价格指模型生成回复的费用。输出通常比输入贵数倍,因为生成文本需要更多的计算资源——每个输出token都需要经过完整的自回归推理过程,逐个生成。
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) |
|---|---|---|
| Claude Haiku 4.5 | $1 | $5 |
| Claude Sonnet 4.5 | $3 | $15 |
Haiku的价格仅为Sonnet的三分之一,而在大多数任务中两者性能相近。以实际场景举例,处理一本约10万字的中文书籍(约20万token)的输入成本仅为0.2美元,这使得大规模文档处理在经济上变得完全可行。对于需要处理数百万次请求的大规模应用场景——客户支持聊天机器人、数据分析管道、内容审核系统——这种成本差异将产生巨大的商业价值。
加上Haiku 4.5以毫秒级响应速度处理请求,意味着每秒可以处理更多的请求量,用户体验和客户满意度都将显著提升。
视觉能力与企业应用场景
Haiku 4.5的视觉能力同样得到了显著提升,支持图像分析、文本提取(OCR)和物体识别等功能。
这为企业级应用打开了广阔空间:
- 电商领域:自动为产品图片添加标签和分类
- 财务处理:从收据和发票中提取结构化文本
- 内容审核:审核用户生成内容并标记不当图片
- 文档处理:批量处理扫描文档并提取关键信息
由于价格低廉且速度极快,企业可以每天处理数千甚至数万张图片而无需担心成本问题。
Haiku 4.5对AI行业意味着什么
AI民主化的又一里程碑
Haiku 4.5的发布传递了一个重要信号:顶级AI能力正在快速下沉到更低成本的模型中。过去需要旗舰模型才能完成的任务,现在入门级模型就能胜任。这将大幅降低AI应用的门槛,让更多中小企业和个人开发者能够负担得起高质量的AI服务。
小模型崛起的技术密码
小模型性能逼近甚至超越大模型的现象并非偶然,背后涉及多种前沿技术的综合应用。知识蒸馏(Knowledge Distillation)是其中最关键的一种——用大模型(教师模型)生成的高质量数据来训练小模型(学生模型),使小模型以更少的参数习得大模型的推理模式和知识表征。此外,混合专家架构(Mixture of Experts, MoE)允许模型拥有庞大的总参数量,但在每次推理时只激活其中一小部分"专家"网络,大幅降低实际计算成本;量化技术(Quantization)则通过将模型参数从32位浮点数压缩到8位甚至4位整数,减少内存占用和计算量的同时尽量保持模型精度。Anthropic虽未公开Haiku 4.5的具体架构细节,但其惊人的性价比表现暗示了这些技术的深度应用。
对行业竞争格局的影响
当一个"小模型"能在编码基准测试中击败竞争对手的旗舰产品时,整个行业的竞争逻辑正在发生变化。未来的AI竞争不仅仅是"谁更聪明",更是"谁能以更低的成本提供足够好的智能"。Anthropic通过Haiku 4.5在这一维度上建立了明显优势。
智能体时代加速到来
Haiku 4.5在工具使用和多步骤任务执行方面的出色表现,预示着AI智能体(Agent)时代正在加速到来。一个能够理解复杂指令、调用多种工具、自主完成端到端工作流程的AI模型,且成本极低——这正是大规模部署AI智能体所需要的基础设施。
总结:Claude Haiku 4.5值得选择吗
Claude Haiku 4.5用事实证明了一个道理:在AI领域,"小而美"同样可以"强而优"。它以三分之一的价格提供了接近旗舰模型的性能,在编码、工具使用、推理和视觉等多个维度全面开花。
对于正在考虑AI转型的企业和开发者而言,Haiku 4.5可能是目前性价比最高的选择。当然,在需要最高精度的复杂推理任务上,Sonnet 4.5和GPT-5仍有优势,但对于绝大多数实际应用场景,Haiku 4.5已经足够出色。
核心要点
- Claude Haiku 4.5在SWE-bench编码基准测试中以73.3%的得分超越多数旗舰模型,包括Sonnet 4和Gemini 2.5 Pro
- 定价仅为Claude Sonnet 4.5的三分之一(输入$1/百万token,输出$5/百万token),实现了极致性价比
- 在智能体工具使用基准测试中表现突出,零售场景83.2%、电信场景83%,具备接近人类的工具使用能力
- 实战测试中仅通过自然语言提示即可在数秒内生成完整可玩的游戏、艺术平台和金融仪表盘
- 视觉能力显著提升,支持OCR、图像分类等企业级应用,低成本可大规模部署
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。