Claude Haiku 4.5实测:速度虽快,性价比不敌GPT-5 Mini

Claude Haiku 4.5速度快但性价比不敌GPT-5 Mini和GLM 4.6
Anthropic发布的Claude Haiku 4.5虽然速度比Sonnet 4快两倍,且是首个支持推理的Haiku模型,但在第三方评测中落后于GPT-5 Mini 9个点,定价却比前代Haiku 3.5还贵25%,远高于GPT-5 Mini和GLM 4.6。综合性价比来看,Haiku 4.5更像是一次防守性更新,竞争对手进步更快、定价更激进。
时隔近一年,Anthropic终于更新了旗下的轻量级模型Haiku。Claude Haiku 4.5号称拥有接近Sonnet 4的智能水平,价格仅为其三分之一,速度则快两倍。然而,当我们将它放到更广阔的竞争格局中审视时,这款模型的表现却让人有些五味杂陈。
速度实测:Haiku 4.5确实比Sonnet 4快得多
为了验证Anthropic的速度承诺,视频作者在Cursor编辑器中进行了一场直观的速度对比测试,将Haiku 4.5与Claude Sonnet 4进行了正面较量。Cursor是目前最受欢迎的AI原生代码编辑器之一,它基于VS Code的开源代码构建,深度集成了多种大语言模型,允许开发者在编写代码的过程中直接调用AI进行代码生成、重构、调试和解释。由于Cursor支持用户自由切换底层模型(包括Claude系列、GPT系列等),它成为对比不同AI模型实际编码表现的理想测试平台。
测试结果相当明确:Haiku 4.5以超过一分钟的优势胜出。为了排除Cursor自身功能对测试的干扰,作者还在Claude Code中重新进行了测试,结果基本一致。Claude Code是Anthropic推出的命令行AI编程工具,它允许开发者通过自然语言指令直接操作代码库,执行从代码编写到Git提交的完整开发流程。这两款工具分别代表了AI辅助编程的两种主流范式——IDE集成式和命令行代理式——在两种范式下都取得一致的速度优势,说明Anthropic关于速度提升的宣传是站得住脚的。
有意思的是,新版Haiku是该系列首个支持推理(reasoning)功能的模型,拥有20万token的上下文窗口和6.4万token的最大输出长度。推理模式是近两年大语言模型领域最重要的技术突破之一:传统的LLM在收到问题后会直接生成答案,而具备推理能力的模型会在输出最终答案之前,先进行一段内部的"思考链"(Chain-of-Thought)过程——将复杂问题拆解为多个步骤,逐步推导出结论。这种机制最早由OpenAI的o1模型大规模推广,随后各大厂商纷纷跟进。推理模式的代价是会消耗额外的token并增加延迟,但在数学、编程、逻辑推理等需要多步骤思考的任务上,性能提升非常显著。Haiku 4.5作为首个支持推理的Haiku系列模型,意味着用户可以在轻量级模型上也获得这种深度思考能力,而不必为此付出使用更昂贵的Sonnet或Opus模型的代价。
至于20万token的上下文窗口,它意味着Haiku 4.5可以一次性处理大约15万个英文单词或约30万个中文字符的内容,足以容纳一本中等篇幅的技术书籍。对于开发者而言,更大的上下文窗口意味着可以将更多的代码文件、文档和对话历史一次性输入模型,减少信息丢失。而6.4万token的最大输出长度则决定了模型单次回复能生成多长的内容,这对于需要一次性生成完整代码文件或长篇文档的场景尤为重要。作为参考,GPT-4o的上下文窗口为12.8万token,因此Haiku 4.5在这一维度上具有明显优势。这些规格参数在轻量级模型中相当有竞争力。
代码质量对比:快归快,生成效果如何?
速度测试中,两个模型分别生成了一个打字游戏。从实际产出来看,作者认为Haiku的UI设计更好看一些,但文字滚动速度偏快。而Sonnet 4生成的版本则在功能完整度上更胜一筹,"解锁了一个全新的层次"。
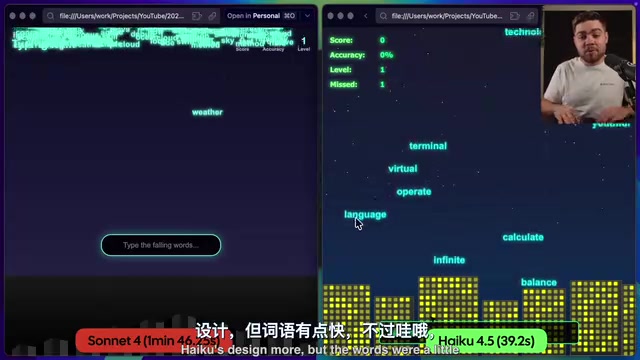
不过,单个案例不足以下定论。让我们看看更系统化的基准测试数据。
基准测试:官方数据亮眼,第三方评测却打折扣
Anthropic官方基准成绩
根据Anthropic自己公布的数据,Haiku 4.5的表现确实令人印象深刻:
- SWEbench上击败了Sonnet 4,甚至超过了GPT-5
- 在大多数基准测试中都与Sonnet 4持平或胜出
- 仅在四项测试中落后于Sonnet 4
SWEbench(Software Engineering Benchmark)是由普林斯顿大学研究团队开发的一项专门评估AI模型软件工程能力的基准测试。与传统的代码生成测试不同,SWEbench从真实的GitHub开源项目中提取实际的bug修复任务——模型需要理解项目的代码库结构、定位问题所在的文件和代码行,然后生成正确的修复补丁。这种测试方式更接近真实的软件开发场景,因此被业界广泛认为是衡量AI编码实力的"黄金标准"之一。Haiku 4.5在SWEbench上击败Sonnet 4,说明Anthropic在训练过程中对模型的实际工程能力进行了重点优化。
这也表明Anthropic在训练这款模型时明显侧重于编码能力,在其他领域做出了一定的取舍。
第三方独立评测结果
然而,当我们转向Artificial Analysis等第三方评测平台时,画风就有所不同了。Artificial Analysis是AI模型领域最具影响力的独立评测平台之一,它通过标准化的测试流程对各家厂商的模型进行横向对比,涵盖智能水平、速度、价格等多个维度。与厂商自行公布的基准成绩不同,第三方评测的价值在于其测试条件的一致性和中立性——所有模型在相同的提示词、相同的评分标准下接受测试,避免了厂商"针对基准测试优化"(benchmark gaming)的问题。业界普遍存在一种现象:模型在官方基准测试中表现优异,但在实际使用或第三方评测中却大打折扣,这通常是因为训练数据中包含了与基准测试相似的样本,导致模型"过拟合"于特定测试。因此,第三方评测结果往往被认为更能反映模型的真实能力。
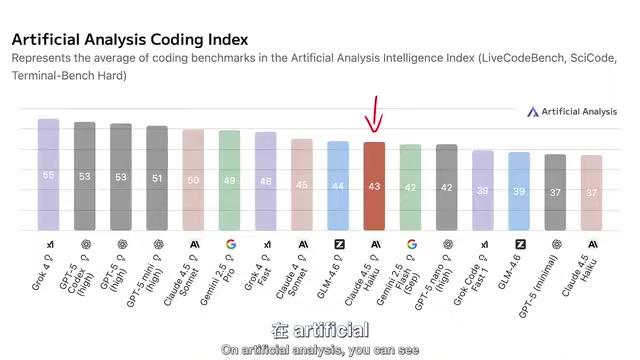
在编码指数(开启推理模式)上,Haiku 4.5仅落后Sonnet 4两个点,看起来还不错。但问题在于:
- GPT-5 Mini High的得分高出9个点
- GLM 4.6也领先1个点
- 而这两个竞品模型的价格都显著低于Haiku 4.5
价格对比:Anthropic的定价策略令人困惑
这是最让人失望的部分。让我们直接看数字:
| 模型 | 输入价格(/百万token) | 输出价格(/百万token) |
|---|---|---|
| Claude Haiku 4.5 | $1.00 | $5.00 |
| Claude Haiku 3.5(去年) | $0.80 | $4.00 |
| GPT-5 Mini | $0.25 | $2.00 |
| GLM 4.6 | $0.50 | $1.75 |
AI模型的API定价通常以"每百万token"为单位,且输入和输出分别计价。输出价格通常高于输入价格,这是因为生成(输出)过程需要逐个token进行自回归推理,计算密度远高于一次性处理输入文本的编码过程。模型的运营成本主要由GPU算力决定,而GPU的利用效率、模型的参数量、推理优化技术(如量化、投机解码、KV缓存优化等)都会直接影响每个token的边际成本。
一个颇为讽刺的事实是:Haiku 4.5比去年的Haiku 3.5还要贵——输入价格涨了25%,输出价格涨了25%。在AI模型价格普遍下降的大趋势下,Anthropic逆势涨价,这多少有些令人费解。当前市场中,AI模型价格呈现快速下降趋势——这得益于推理硬件的进步、模型蒸馏技术的成熟以及厂商之间的激烈竞争。Anthropic逆势涨价的做法之所以引发争议,正是因为它违背了这一行业大趋势。
更关键的是,GPT-5 Mini的输入价格仅为Haiku 4.5的四分之一,输出价格不到其一半,而在第三方评测中的表现还更好。
性价比与速度综合分析

当我们将智能水平与成本放在同一张图上分析时,结论非常清晰:
- GPT-5 Mini在性价比维度上遥遥领先,是当前轻量级模型的最优选择
- GLM 4.6同样优于Haiku 4.5
- 即使在智能水平与输出速度的对比中,开启推理模式后的Haiku也仅与GLM 4.6持平
值得一提的是,GLM 4.6来自中国AI公司智谱AI(Zhipu AI),由清华大学技术团队孵化,是中国最早一批专注于通用大模型研发的企业之一。近年来,中国AI厂商在模型性价比方面展现出极强的竞争力,通过更高效的训练方法、更低的运营成本以及激进的定价策略,在全球市场中形成了独特的竞争优势。GLM 4.6以极低的价格提供与国际顶级模型相当的性能,这种"以价换量"的策略正在深刻改变全球AI模型的定价格局,迫使Anthropic和OpenAI等西方厂商也不得不考虑更具竞争力的价格方案。
Haiku 4.5还值得用吗?适合哪些场景
尽管在纯粹的性价比较量中Haiku 4.5并不占优,但它仍然有其独特价值:
优势方面:
- 速度确实快,适合需要快速迭代的开发场景
- 与Claude Code深度集成,对于已在Anthropic生态中的用户来说切换成本低
- Anthropic模型在实际代码库中的表现往往比基准测试更可靠
- 首个支持推理的Haiku模型,功能上有质的飞跃
不足方面:
- 价格不够有竞争力,甚至比前代还贵
- 第三方评测表现不如GPT-5 Mini和GLM 4.6
- 明显偏科编码,通用能力有所牺牲
写在最后:竞争才是开发者的福音
客观来说,Haiku 4.5并不是一款"令人失望"的模型——它确实实现了接近Sonnet 4的智能水平和更快的速度。真正的问题在于,竞争对手的进步速度更快、定价更激进。
OpenAI的GPT-5 Mini和智谱的GLM 4.6都在用更低的价格提供相当甚至更好的性能。这种激烈的竞争态势对开发者来说是绝对的利好——轻量级、高性价比的AI模型正在变得越来越好、越来越便宜。
对于Anthropic而言,Haiku 4.5更像是一次防守性的产品更新,而非进攻性的市场突破。在这个价格敏感的细分市场中,Anthropic或许需要重新审视自己的定价策略,否则可能会在这场性价比之战中逐渐失去阵地。
核心要点
- Claude Haiku 4.5速度比Sonnet 4快一分钟以上,是首个支持推理的Haiku模型
- 官方基准测试中Haiku 4.5在SWEbench上击败Sonnet 4和GPT-5,但第三方评测中GPT-5 Mini高出9个点
- Haiku 4.5定价$1/$5(输入/输出),比去年的Haiku 3.5还贵,而GPT-5 Mini仅$0.25/$2
- 综合性价比分析中GPT-5 Mini和GLM 4.6均优于Haiku 4.5
- Haiku 4.5更像是Anthropic的防守性更新,轻量级模型市场的激烈竞争对开发者是利好
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。