Claude Mythos Preview研究决策能力超越人类64%意味着什么

AI研究决策能力测试:64%的情况下超越人类研究员
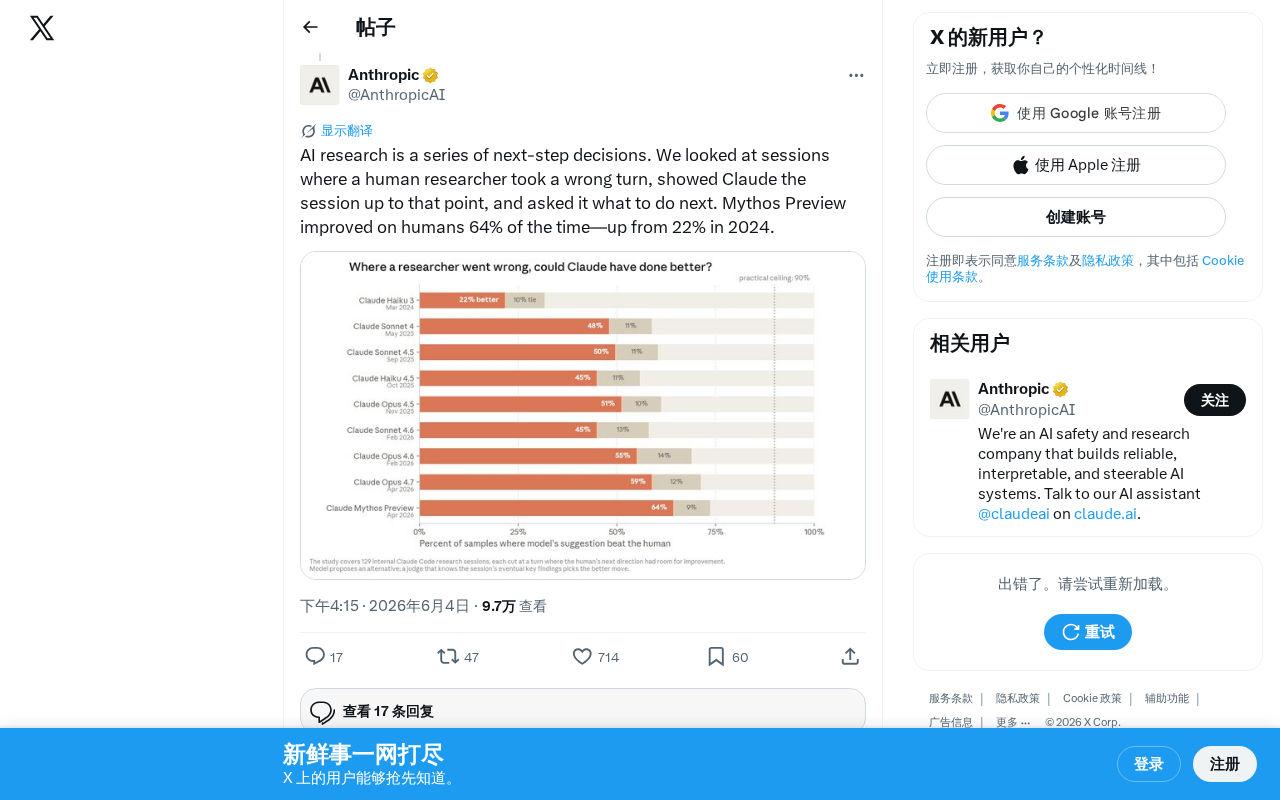
Anthropic近日公布了一项引人注目的研究成果:在AI研究过程中的"下一步决策"测试中,Claude Mythos Preview模型在64%的情况下做出了比人类研究员更优的判断。这一数字相比2024年的22%,实现了近三倍的跃升。
这项测试的设计思路极具启发性——AI研究本质上是一系列"下一步该做什么"的决策链条。研究团队找到了人类研究员在研究过程中"走错方向"的真实案例,将错误发生前的完整研究记录展示给Claude,然后询问它接下来应该怎么做。
在机器学习研究中,一个典型的研究项目可能包含数百个微观决策点。这些决策的质量直接决定了研究效率——业内常说的"research taste"(研究品味)本质上就是在信息不完整的情况下做出高质量方向性判断的能力。顶级研究员与普通研究员的差距,往往不在于编码能力或数学功底,而在于这种"选择正确问题、选择正确方法"的直觉。Anthropic的这项测试正是试图量化这种此前被认为难以衡量的能力。
评估方法为何值得关注
这个评估方法的巧妙之处在于它关注的维度。传统AI能力评测往往衡量最终结果——模型能否解出某道题、能否完成某个任务。但Anthropic的这项测试关注的是过程中的判断力,这更接近真实科研场景。
Claude Mythos Preview是Anthropic专门针对AI研究任务优化的模型变体。与通用对话模型不同,这类专用模型通常在训练数据配比、推理链长度、以及领域特定的微调策略上做了针对性调整。"Preview"标签意味着这仍是一个实验性版本,Anthropic选择公布这一阶段性成果,既展示了技术进步,也为后续正式发布设定了社区预期。
在实际的AI研究工作中,研究员每天都面临大量分支选择:
- 该调哪个超参数?
- 该换什么架构?
- 该去读哪篇论文?
- 当前方向是否值得继续投入?
这些选择的决策复杂度远超表面。以超参数调优为例,学习率、批量大小、正则化强度等参数的组合空间呈指数级增长,传统方法如网格搜索或贝叶斯优化只能在有限维度上探索。而架构选择的决策空间更为广阔——从Transformer的层数、注意力头数,到是否引入混合专家(MoE)结构,每个选择都可能带来截然不同的训练结果。一位资深研究员的核心价值,很大程度上在于能凭借经验快速缩小这个搜索空间。
一个错误的方向性决策可能浪费数天甚至数周的时间。Claude Mythos Preview展现出的能力表明,AI已经能在这类高层次的策略性判断上提供实质性帮助。
从22%到64%:一年内发生了什么
2024年,Claude在同类测试中仅有22%的情况优于人类。这意味着在当时,人类研究员的直觉和经验在绝大多数情况下仍然更可靠。但短短一年内,这个比例跃升至64%,AI在研究决策能力上已经从"偶尔有用的参考"变成了"多数情况下更优的顾问"。
这一进步速度本身就是重要信号,它揭示了几个关键趋势:
AI辅助研究的实用价值已跨过临界点。 当AI在超过半数的情况下能给出更好建议时,将其纳入研究流程不再是可选项,而是竞争力的必要组成部分。
AI研究的自我加速效应可能正在显现。 更强的AI帮助研究员做出更好的决策,进而加速AI本身的迭代进化,形成正反馈循环。这一效应在学术界被称为"递归自改进"(recursive self-improvement),是AI安全研究中的核心关注点之一。其基本逻辑是:如果AI系统A能够帮助创建比自身更强的AI系统B,而B又能创建更强的C,则可能产生能力的指数级增长。Anthropic作为AI安全研究的领军机构,对这一现象保持高度警觉。64%这个数字之所以引起广泛关注,部分原因正是它暗示了这种自我加速循环可能已经开始启动——尽管目前仍处于人类可监督的范围内。
人类研究员的角色正在发生转变。 从独立决策者转向与AI协作的决策者,判断"何时采纳AI建议"本身成为一项核心能力。
对AI研究范式的实际影响
这项成果的深层含义在于,AI正在从"执行工具"向"策略顾问"演进。过去我们谈论AI辅助编程、AI辅助写作,关注的是执行层面的效率提升。而研究决策属于更高层次的认知活动,涉及对问题空间的理解、对可行路径的评估、以及对风险与收益的权衡。
你可能没注意到,64%的优势率也意味着仍有36%的情况下人类判断更优。这一数据指向的最佳实践是人机协作而非完全依赖AI:
- 让AI提供决策建议和替代方案分析
- 由有经验的研究员做最终裁决
- 尤其重视那些需要深度领域直觉的关键节点
在AI研究领域之外,人机协作决策已在医学诊断、金融风控等领域有成熟实践。研究表明,最优的协作模式往往不是简单的"AI建议+人类审批",而是需要精心设计的互补机制。例如,在放射科AI辅助诊断中,当AI置信度极高或极低时直接采用其判断,而人类医生的介入价值最大的区间是AI"不确定"的中间地带。类似的框架正在被引入AI研究流程:让AI处理其擅长的模式匹配型决策,将需要跨领域类比推理或违反直觉创新的决策留给人类。
这一趋势的后续走向
从22%到64%的跃升发生在一年之内。如果这个趋势继续,AI在研究决策上全面超越人类可能并不遥远。这将深刻改变AI研究的组织方式——团队规模、决策流程、资源分配都可能需要重新设计。
同时,这也引发了关于AI自主研究能力边界的重要讨论:当AI不仅能执行研究任务,还能在策略层面持续做出更优判断时,人类在研究环节中的不可替代性究竟体现在哪里?这个问题的答案,可能将定义未来几年AI研究领域的发展方向。
相关推荐
Claude Code 4个必改设置,开发效率直接翻倍
Claude Code 4个必改设置,开发效率直接翻倍
分享Claude Code最值得修改的4个设置:权限模式绕过、聊天记录永久保留、MCP合并规则理解、全局Skill精简到7个。改完告别确认框骚扰,节省6%上下文窗口,开发体验立刻提升。
RTK终端输出压缩工具:Claude Code省下80%Token消耗
RTK终端输出压缩工具:Claude Code省下80%Token消耗
RTK是一款用Rust编写的开源终端输出压缩工具,专为Claude Code设计。通过拦截和压缩git、npm等命令输出,将Token消耗从11.8万降至2.39万,节省约80%。免费、离线、两分钟安装即用。
笨豆:16岁独立拍纪录片,全网播放破亿的10后UP主
笨豆:16岁独立拍纪录片,全网播放破亿的10后UP主
B站UP主笨豆,16岁高一学生,从四年级开始做视频,独立完成印度、蒙古国等人文纪录片拍摄,全网粉丝超百万、播放量破亿。深入了解她的纸上剪辑法、一人纪录片工作流程及创作心路历程。