Claude Opus 4.7发布:编程性能提升20%,同价不涨,国产模型差距再拉大
Claude Opus 4.7发布,编程性能提升20%且不涨价,拉大与国产模型差距。
Anthropic发布Claude Opus 4.7,编程Agent性能提升约20%,定价与前代持平(输入5美元/输出25美元每百万token)。该模型在编程能力上位居第一梯队,国产最强模型GLM 5.1仅处于上一代Opus 4.5和Sonnet 4.6之间,差距进一步拉大。虽然Opus定价约为竞品两倍,但其一轮完成任务的效率优势使综合性价比更高。编程Agent正成为大模型竞争核心战场。
Claude Opus 4.7正式发布:编程性能大幅跃升
Anthropic近日正式发布了Claude Opus 4.7版本,这一更新在AI编程圈迅速引爆讨论。最核心的亮点在于:编程Agent性能提升约20%,定价却与前代Opus 4.4完全一致——输入5美元/百万token,输出25美元/百万token。
在大模型价格战愈演愈烈的今天,Anthropic这波"加量不加价"的操作相当有杀伤力。对开发者和企业用户来说,不多花一分钱就能拿到明显更强的编程能力,升级的理由已经足够充分。
什么是编程Agent? 编程Agent是指能够自主规划、执行多步骤编程任务的AI系统,区别于单纯的代码补全工具。它不仅能生成代码片段,还能理解项目上下文、调用工具链、自动运行测试、根据错误反馈迭代修复,形成完整的「感知-规划-执行」闭环。衡量编程Agent能力的核心基准包括SWE-bench(真实GitHub Issue修复率)和HumanEval等,其中SWE-bench因贴近真实工程场景而被业界视为最具参考价值的指标。20%的性能提升在这类基准上意义重大,因为顶尖模型之间的分数差距通常只有几个百分点。
编程能力排名:Claude Opus 4.7拉开梯队差距
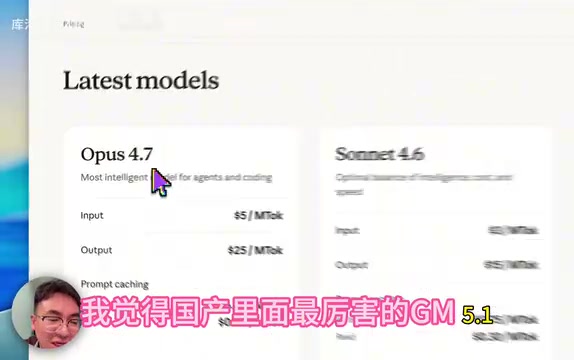
从最新的跑分数据和实测表现来看,Claude Opus 4.7在编程任务上已经拉出了清晰的梯队分层。综合多方评测,当前主流大模型的编程能力排序大致如下:
- 第一梯队:Claude Opus 4.7(最新发布)
- 第二梯队:Claude Sonnet 4.6
- 第三梯队:GLM 5.1(介于Opus 4.5和Sonnet 4.6之间)
- 第四梯队:Claude Opus 4.5、GPT系列、Gemini系列
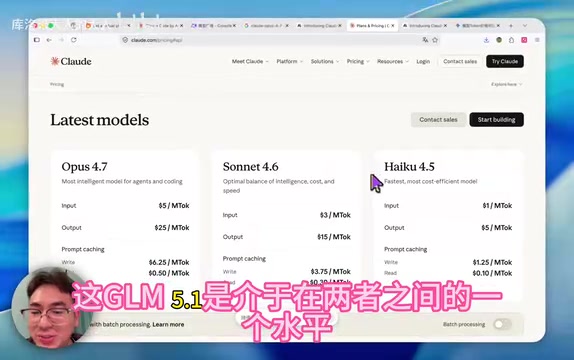
国产模型中目前编程能力最强的GLM 5.1,实测水平大致处于Claude Opus 4.5和Sonnet 4.6之间。换句话说,国产最强选手距离上一代的Sonnet 4.6尚有差距,而Opus 4.7又往前迈了一大步,追赶难度进一步加大。
国产大模型的技术生态 GLM系列由清华大学KEG实验室与智谱AI联合研发,是国内学术界与产业界协同的代表性成果,其架构基于General Language Model预训练框架,在中文理解和代码生成上持续优化。Kimi则由月之暗面开发,以超长上下文处理见长。国产模型在编程能力上的追赶面临多重结构性挑战:一是高质量代码训练数据的获取成本高;二是RLHF(基于人类反馈的强化学习)中专业程序员标注资源稀缺;三是算力基础设施受出口管制影响,训练规模受限。这些因素共同决定了「渐进式迭代」在短期内难以实现跨越式追赶。
性价比分析:看似贵两倍,实际可能更划算
单看API定价,Claude Opus 4.7大约是GPT和Gemini同级模型的两倍。但在实际编程场景中,价格只是成本的一部分,完成效率才是关键变量。
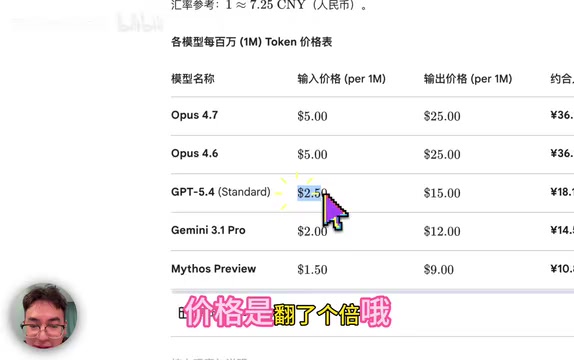
理解Token定价与真实成本 Token是大语言模型处理文本的基本单位,大致对应英文中3/4个单词或中文1-2个汉字。「百万token」定价是行业标准计费单位。值得注意的是,编程任务的输入token通常远多于输出token——完整的代码库上下文、错误日志、需求描述都会消耗大量输入配额,而生成的代码相对较少。因此输入价格(5美元/百万)对重度编程用户的实际账单影响更大。与此同时,Claude支持的200K上下文窗口允许一次性载入大型代码库,减少了多轮对话的碎片化成本,这也是其在复杂工程项目中综合性价比更高的技术原因之一。
不少开发者反馈,Opus一轮对话就能搞定的编程任务,换成GPT或Gemini往往需要两轮甚至更多轮才能达到同样效果。把来回调试、反复迭代的时间成本算进去,Opus的综合性价比反而更高。对于赶项目进度的专业开发者来说,省下的时间远比多出的API费用值钱得多。
对国产大模型的三点启示
Claude Opus 4.7的发布,给国内大模型厂商敲响了几记警钟。
技术追赶的窗口期正在缩短
国产模型还在努力追赶上一代水平的时候,Anthropic已经又往前跑了一截。如果这种"刚追上就被甩开"的循环持续下去,差距只会越拉越大。GLM、Kimi等国产模型要想真正缩小差距,必须在核心技术上实现跨越式突破,光靠渐进式迭代恐怕不够。
不涨价策略挤压竞争空间
Anthropic选择性能大幅提升但不涨价,本质上是在用技术优势和规模效应挤压对手的生存空间。国产模型虽然在价格上一直有优势,但当性能差距拉大到一定程度时,低价策略的吸引力会迅速衰减——毕竟没人愿意为了省钱而忍受明显更差的编程体验。
编程Agent正在成为核心战场
从Opus 4.7的更新重点不难看出,编程Agent能力已经成为大模型竞争最激烈的赛道。谁能在代码生成、Bug调试、架构设计等任务上做到"一轮搞定",谁就能赢得开发者群体的长期信赖和付费意愿。
护城河的深层逻辑 Anthropic的「护城河」策略在技术层面体现为Constitutional AI(宪法AI)训练方法——通过预设原则约束模型行为,使其在复杂Agent任务中保持更高的指令遵循度和安全性,这对企业级编程场景尤为关键。在商业层面,开发者工具链的生态锁定效应显著:一旦团队将CI/CD流程、IDE插件、代码审查工作流与特定模型深度集成,迁移成本会随时间快速累积。这也解释了为何「不涨价」策略的杀伤力远超表面数字——它在加速开发者生态的形成与固化,而生态一旦成型,竞争对手即便在性能上追平,也难以撼动已建立的用户习惯。
总结:AI编程竞争远未到终局
Claude Opus 4.7的发布再次说明,大模型的编程能力竞争还在加速演进。Anthropic凭借持续的技术迭代和克制的定价策略,正在AI编程领域构建越来越深的护城河。
对于国产大模型厂商而言,与其在通用能力上全面追赶,不如集中资源在特定垂直场景寻找突破口,用差异化优势争取一席之地。毕竟在这场马拉松中,找到自己的节奏比盲目跟跑更重要。
核心要点
- Claude Opus 4.7编程Agent性能提升20%,定价与4.4版本持平(输入5美元/输出25美元每百万token)
- 国产最强模型GLM 5.1的编程能力介于Claude Opus 4.5和Sonnet 4.6之间,与Opus 4.7差距进一步拉大
- 虽然Opus定价是GPT和Gemini的两倍,但一轮完成任务的效率优势使其综合性价比更高
- 国产大模型面临技术追赶窗口期缩短、定价策略承压的双重挑战
- 编程Agent能力正成为大模型竞争的核心战场
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。