Claude Opus 4.8 实测:游戏开发与UI还原能力全面评估
Claude Opus 4.8多场景实测:细节优化明显,3D游戏一次生成令人印象深刻
本文通过约50美元Token的深度测试,从2D塔防游戏、UI还原、3D游戏开发和工具生成等维度评估了Claude Opus 4.8的实际能力。结果显示,Opus 4.8相比4.7在UI还原细节上有所提升,3D游戏一次性生成可玩原型的能力令人印象深刻,工具类应用生成质量稳定。但整体属于迭代优化而非革命性升级,在复杂任务的细节处理上仍有瑕疵。
概述
Anthropic 近期推出了 Claude Opus 4.8 模型,作为 Opus 系列的最新迭代版本,它在代码生成、UI 还原、3D 游戏开发等方面的表现备受关注。本文基于多个实际场景的深度测试(总计花费约 50 美元 Token),从游戏开发、系统还原、工具生成等维度,全面评估 Opus 4.8 的真实能力。
背景:Claude 模型家族分级体系 Anthropic 的 Claude 模型采用分级命名体系:Haiku(轻量快速)、Sonnet(均衡)、Opus(旗舰)。Opus 系列定位为最高性能档位,主要面向需要深度推理、复杂代码生成和长上下文处理的专业场景。Anthropic 作为由前 OpenAI 研究人员创立的 AI 安全公司,其模型训练强调「宪法 AI」(Constitutional AI)方法,在能力提升的同时注重对齐与安全性。值得注意的是,旗舰模型的高性能伴随着显著更高的 API 调用成本——本次测试约 50 美元的花费,正是 Opus 系列高定价(通常为输出 $75/百万 token 量级)在复杂任务下的真实体现。
2D 塔防游戏:一次生成基本可玩
测试的第一个场景是让 Opus 4.8 根据预先生成的简单游戏贴图资产,完成一个塔防游戏的开发。实测结果显示,模型能够正确处理塔防布置、镜子区域设置、不同炮台选择等核心功能,甚至连音效都自动生成了。
不过也存在明显瑕疵——炮台无法正常发射炮弹,这对于塔防游戏来说是一个关键功能缺失。综合来看,测试者给出了 80 分(满分 100)的评价。考虑到这是一次性生成的结果,这个表现已经相当不错。
为何模型擅长框架却在细节上失误? 大语言模型的代码生成能力本质上是对海量代码语料(GitHub、Stack Overflow 等)的统计模式学习。模型并不真正「理解」程序逻辑,而是通过 Transformer 架构的注意力机制,在 token 序列层面预测最可能的代码续写。这解释了为何模型能生成结构完整的游戏框架,却可能在「炮弹发射」这类需要精确物理逻辑的细节上出错——游戏框架的整体结构模式在训练数据中频繁出现,而特定交互逻辑(如抛射体碰撞检测)的正确实现需要更精准的上下文推理,训练数据中的正确示例密度相对较低。
UI 还原对比:Opus 4.8 vs 4.7 的微妙提升
衣橱管理原型图还原
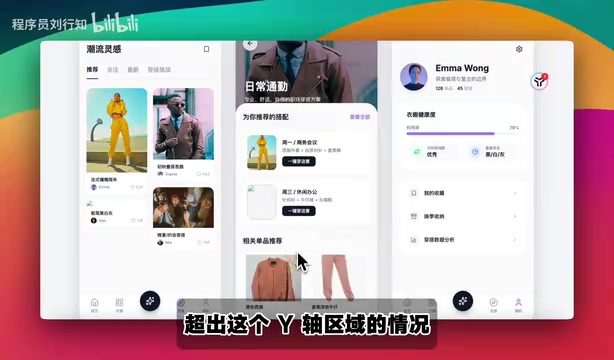
测试使用了一个衣橱管理应用的原型图,包含沉浸体验和平铺展示两种模式。将 Opus 4.7 和 4.8 的还原效果进行对比后发现:
- Opus 4.7:多出了不必要的边框,图片处理存在问题,衣服图片出现了超出区域的溢出
- Opus 4.8:图片和衣橱展示正常,衣服没有超出容器边界,整体布局更加规范
UI 还原的技术本质:视觉-代码跨模态转换 UI 还原测试考察的是模型的「视觉-代码」跨模态转换能力(Vision-to-Code)。模型需要解析输入的原型图截图,识别布局层级、组件类型、间距关系,再将其映射为 HTML/CSS 实现。Opus 4.7 出现的「图片溢出容器」问题,通常源于模型未能正确推断父容器的
overflow: hidden属性,或未设置max-width/object-fit: cover等约束——这类 CSS 细节在训练数据中的正确示例密度,直接影响模型的修复能力。Opus 4.8 的改进表明 Anthropic 在这类视觉精度问题上进行了针对性的微调优化。
评测者认为 Opus 4.8 相对于 4.7 是一个「很小但确实存在的提升」,尤其在 UI 渲染表现上更加优秀。
Mac 与 Windows 系统界面还原
使用 Opus 4.8 还原 Mac 系统界面,效果令人满意:系统可以正常打开、编辑器可以正常输入、窗口移动非常丝滑。Windows 系统的还原同样出色,甚至连应用商店都被还原出来了。
后台管理系统的案例则展现了赛博朋克风格的 UI 设计,配色和布局都没有明显缺陷。不过评测者也指出,网页类 UI 生成在 Claude 早期版本中就已经表现不错,Opus 4.8 更多是迭代优化。
3D 游戏开发:最具挑战性的测试场景
浏览器端 3D 游戏的技术基础 Opus 4.8 生成的 3D 游戏大概率基于 Three.js 或 Babylon.js 等 WebGL 封装库实现。Three.js 是目前最主流的浏览器端 3D 渲染框架,通过封装 WebGL 底层 API,提供场景图、相机、光照、材质等高级抽象,开发者无需直接编写 GLSL 着色器即可构建复杂 3D 场景。由于 Three.js 在 GitHub 上拥有数以万计的示例项目,大模型对其 API 的掌握程度通常优于其他 3D 框架,这也是为何 AI 生成的 3D 游戏往往能快速搭建出可运行的框架。
修仙题材 3D 游戏「云海问道」
这是本次测试中最令人印象深刻的场景之一。Opus 4.8 生成了一个名为「云海问道」的 3D 修仙游戏,包含以下功能:
- 多个秘境/地图可供选择
- 妖兽名称显示与战斗系统
- 御空飞行功能(虽然有些瑕疵)
- 穿越边界抵达不同秘境
- 加速功能(Shift 键)
- 不同地图有不同的野兽设计
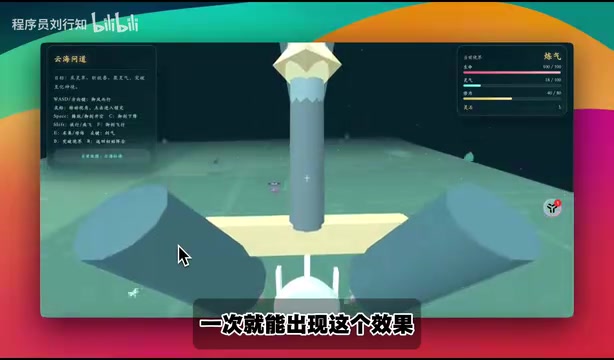
整体而言,一次 prompt 就能生成如此复杂的 3D 游戏框架,充分展现了 Opus 4.8 对复杂指令的理解能力。
穿越火线风格 FPS 游戏
另一个 3D 测试是类似穿越火线的射击游戏,支持多地图选择(荒谷遗墨、熔岩峡谷、极寒冰原等)和不同枪械切换。

测试者给出了 70 分 的评价,主要扣分点在于:
- 地图渲染偏雾蒙蒙,视觉效果不够清晰
- 缺少下蹲等基础 FPS 操作
- 不过击杀数量显示正常,子弹确实能发射出去
「雾蒙蒙」渲染问题的技术原因 FPS 游戏中出现的「雾蒙蒙」视觉效果,很可能源于模型在生成 Three.js 代码时默认添加了
THREE.FogExp2(指数雾效)或THREE.Fog(线性雾效)。这类雾效在游戏开发中常用于遮蔽远处低精度几何体、营造氛围感,但参数设置不当会导致近景也变得模糊。此外,环境光(AmbientLight)强度过低或未添加方向光(DirectionalLight)也会造成整体画面偏暗偏灰的视觉感受。这类渲染参数调优属于「细节层面」的问题,正是当前 AI 生成代码的典型短板。
有意思的是,切换不同地图后,场景风格和武器外观都会相应变化,说明模型对游戏设计的整体性有一定理解。
3D Mario 风格平台跳跃游戏
使用极简 prompt(仅一句「开发一个 3D Mario Out 游戏」)进行测试,Opus 4.8 一次性生成了可玩的结果:支持二段跳(空格键)、加速(Shift 键),3D 场景设计也比较真实。由于 Token 限制,仅设计了第一关,但足以证明模型对简短提示词的理解和执行能力。
工具与应用开发能力测试
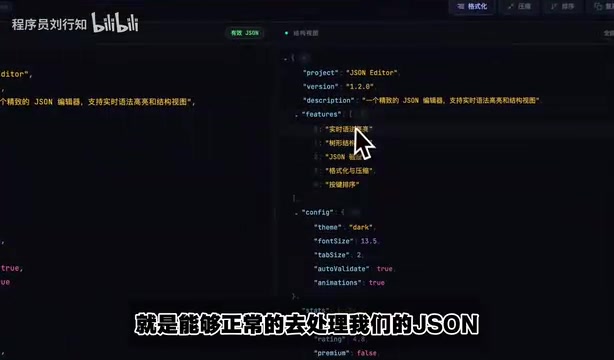
JSON 可视化工具
让 Opus 4.8 开发一个 JSON 可视化工具,支持高亮、压缩、排序等功能。生成结果功能完整,默认采用了赛博朋克风格的 UI 设计。
自媒体商业管理平台
生成的自媒体商业管理平台原型图表现中规中矩,基本功能和布局都能正确实现。
提词管理器
针对 prompt 管理需求,Opus 4.8 生成了一个提词管理器,支持新建提词、分区域展示等功能。虽然图标存在小问题,但整体功能实现到位。
总结与评价
经过多场景实测,Claude Opus 4.8 的表现可以总结为以下几点:
| 测试维度 | 评分 | 说明 |
|---|---|---|
| 2D 游戏开发 | 80/100 | 基本功能完整,核心机制有缺失 |
| UI 还原 | 85/100 | 比 4.7 有提升,网页类表现稳定 |
| 3D 游戏开发 | 70-75/100 | 框架完整但细节有瑕疵 |
| 工具开发 | 85/100 | 功能完整,UI 风格统一 |
Opus 4.8 相对于 4.7 的提升幅度不大,更多体现在细节优化上——比如 UI 元素不再溢出、布局更加规范。但在 3D 游戏这类高复杂度任务上,一次性生成可玩游戏的能力确实令人印象深刻。
AI 辅助开发与 MVP 方法论的结合 「最小可行产品」(MVP, Minimum Viable Product)概念源自精益创业方法论,强调以最低成本验证核心假设,避免在未经市场验证的功能上过度投入。Opus 4.8 在单次 prompt 下生成可玩游戏原型的能力,正在重塑独立开发者和小型团队的工作流:原本需要数天的原型搭建被压缩至数分钟,开发者可将精力集中于产品差异化设计而非基础实现。这与近年兴起的「氛围编程」(Vibe Coding)趋势高度契合——用自然语言描述意图,由 AI 完成技术实现,人类负责方向把控与迭代决策。对于独立游戏开发者和创业团队而言,这种工作模式的效率提升是实质性的。
对于开发者而言,Opus 4.8 在快速原型验证和 MVP 开发方面已经是一个非常实用的工具。
核心要点
- Claude Opus 4.8 相比 4.7 在 UI 还原方面有细节提升,图片处理和布局溢出问题得到改善
- 3D 游戏开发能力突出,仅用简短提示词即可一次性生成包含多地图、多机制的可玩游戏
- 2D 塔防游戏获得 80 分评价,FPS 游戏获得 70 分,主要扣分在核心功能缺失和渲染质量
- 工具类应用(JSON 可视化、管理平台等)生成质量稳定,功能完整度高
- 整体测试花费约 50 美元,Opus 4.8 更多是迭代优化而非革命性升级
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。