Claude Opus 4.8发布:判断力、诚实度与自主工作能力全面升级

概述
Anthropic正式发布了Claude Opus 4.8,这是继Opus 4.7之后的又一次迭代升级。根据官方介绍,新版本在判断力、自我认知诚实度以及独立工作时长方面均有显著提升,且保持与前代相同的定价策略。
Anthropic由前OpenAI研究副总裁Dario Amodei和Daniela Amodei兄妹于2021年创立,公司核心理念是开发安全、可控的AI系统。Anthropic提出了"Constitutional AI"(宪法AI)训练方法,通过让模型依据一组明确的原则进行自我修正,而非完全依赖人类标注反馈。公司已累计获得超过70亿美元融资,投资方包括Google、Salesforce和亚马逊等。Anthropic在产品设计中始终将安全性和诚实性置于性能之上,这也解释了为何Opus 4.8将"自我认知诚实度"作为核心升级方向之一。
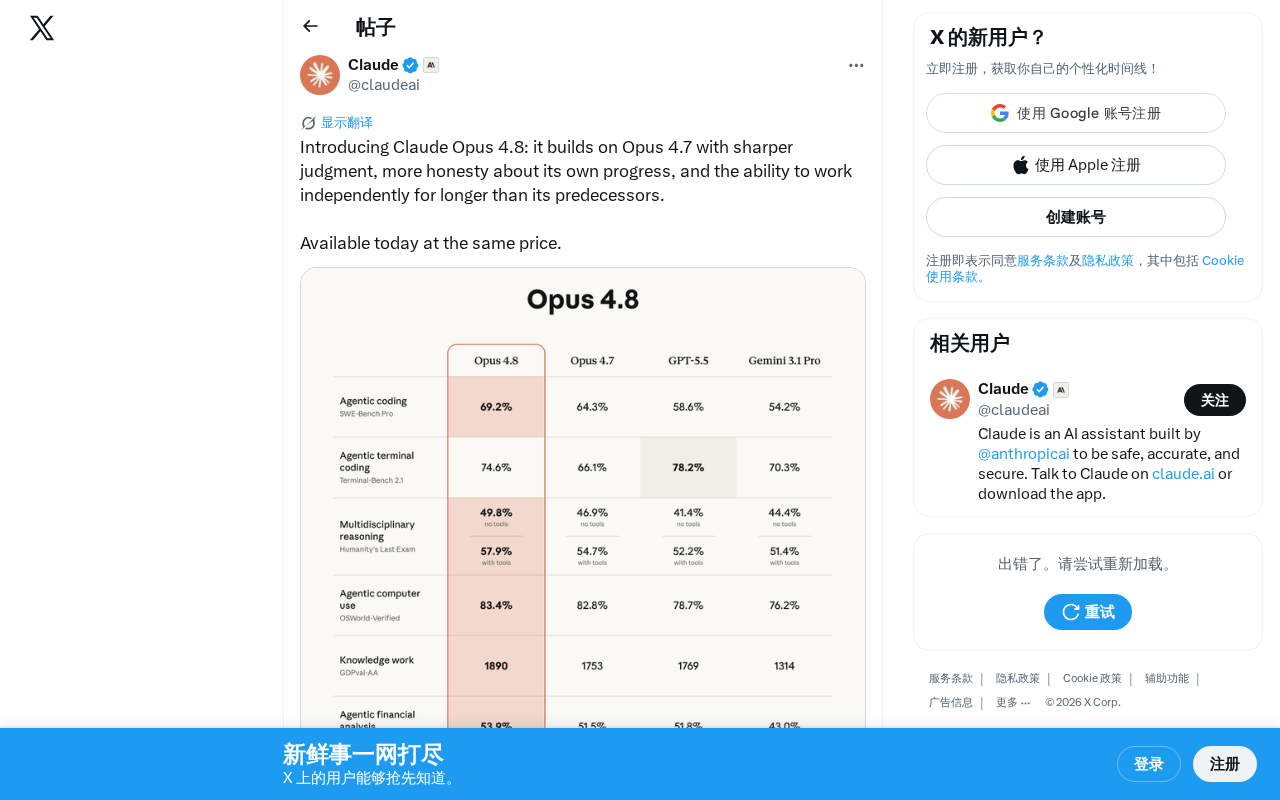
Claude Opus 4.8的三大核心升级
在深入了解具体升级之前,有必要了解Opus在Anthropic模型体系中的定位。Claude模型家族按能力从高到低分为Opus、Sonnet和Haiku三个层级,分别对应不同的使用场景和定价区间。Opus定位于需要最强推理能力和最高输出质量的专业场景,如复杂编程、深度研究和高风险决策支持。从4.7到4.8的版本号递进,反映了Anthropic采用的渐进式版本管理策略,区别于此前从Claude 3到Claude 4的大版本跳跃。
更敏锐的判断力
Claude Opus 4.8在推理和判断能力上进行了针对性优化。所谓"更敏锐的判断力"(Sharper Judgment),意味着模型在面对复杂、模糊或需要权衡的任务时,能够做出更精准的决策。这对于编程调试、文档分析、策略建议等需要深度思考的场景尤为重要。
在技术层面,判断力的提升通常涉及模型在推理链(Chain of Thought)质量上的改进。推理链是指模型在给出最终答案前,逐步展开的中间推理过程。更高质量的推理链意味着模型能够更系统地考虑问题的多个维度,识别隐含假设,评估不同方案的利弊,并在存在冲突信息时做出更合理的取舍。这与简单的知识检索有本质区别——它要求模型具备类似人类专家的"综合研判"能力。
从Anthropic近期的产品迭代节奏来看,Opus系列正在朝着"可靠的AI协作者"方向演进,而非单纯追求基准测试分数的提升。判断力的增强意味着模型在实际应用中犯错的概率更低,输出结果的可信度更高。
对自身能力边界更诚实
这是Claude Opus 4.8一个值得关注的特性。AI模型对自身能力边界的认知一直是业界难题——过度自信会导致"幻觉"输出,过度保守则会降低实用性。Opus 4.8在这方面做了明显改进,能够更准确地评估自己是否真正理解了问题、是否有能力完成任务。
所谓AI幻觉(Hallucination),是指大语言模型在生成内容时,以高度自信的语气输出事实上不正确或完全虚构的信息。这一问题的根源在于语言模型本质上是基于统计概率进行文本预测,而非真正"理解"信息的真伪。元认知(Metacognition)在AI领域指模型对自身推理过程和能力边界的感知能力。传统模型缺乏这种自我评估机制,往往在知识盲区仍然生成看似合理的回答。Anthropic通过训练技术让模型学会识别自身的不确定性,并在适当时候表达犹豫或拒绝回答,这被认为是提升AI可靠性的关键路径之一。
值得注意的是,实现这种"校准良好的不确定性"(Well-Calibrated Uncertainty)在技术上极具挑战。模型需要在训练过程中学会区分"我确信知道答案""我大概知道但不完全确定"和"我实际上不知道"这三种状态。业界目前的主流方法包括:基于强化学习从人类反馈(RLHF)中训练模型的诚实行为、使用对抗性评估发现模型过度自信的场景、以及通过Constitutional AI框架中的诚实性原则进行自我约束。Opus 4.8在这方面的进步,意味着Anthropic可能在训练数据策略和奖励模型设计上取得了新的突破。
这种"元认知"能力的提升,反映了Anthropic在AI安全和可靠性方面的持续投入。一个能够坦诚说"我不确定"的AI,往往比一个总是给出看似自信答案的AI更值得信赖。
更长的独立工作时长
相比前代模型,Claude Opus 4.8能够在更长时间内保持独立工作状态。这一改进直接关联到Anthropic近期力推的AI Agent(智能体)使用场景。
AI Agent是指能够自主感知环境、制定计划、执行多步骤任务并根据反馈调整行为的AI系统。与传统的单轮对话式AI不同,Agent需要具备任务分解、工具调用、错误恢复和长期记忆等能力。2024年以来,AI Agent已成为行业最热门的方向之一,OpenAI、Google、Microsoft等巨头均在布局。Agent的核心挑战之一是"长程可靠性"——即在长时间自主运行过程中保持决策质量不衰减、不偏离目标。Claude Opus 4.8强调的"更长独立工作时长"正是针对这一痛点的改进。
从技术角度看,长时间独立工作能力的提升涉及多个维度的优化。首先是上下文窗口的有效利用——当任务执行时间越长,累积的上下文信息越多,模型需要在有限的上下文窗口内高效管理和检索关键信息。其次是"目标漂移"(Goal Drift)问题的缓解——在长序列任务中,模型可能逐渐偏离原始目标,陷入无关的子任务或重复循环。此外还包括错误累积的控制——每一步决策的微小偏差在长链条中可能被放大,导致最终结果严重偏离预期。Opus 4.8在这些方面的改进,使其更适合作为可靠的自动化工作引擎。
更长的独立工作能力意味着:
- 处理大型项目时无需频繁人工干预
- 多步骤复杂任务的完成率更高
- 在自动化工作流中表现更稳定
这与当前AI行业从"对话式AI"向"任务执行型AI"转型的大趋势高度一致。
Claude Opus 4.8定价与可用性
有意思的是,Anthropic明确表示Opus 4.8与前代保持相同价格(Available today at the same price)。这种"性能升级、价格不变"的策略在当前AI竞争格局中颇具竞争力,降低了用户的迁移成本和决策门槛。
对于已经在使用Claude Opus系列的开发者和企业用户来说,可以无缝切换到新版本,无需调整预算。这种定价策略也反映了AI行业的一个重要趋势:随着训练和推理效率的持续优化,模型厂商能够在不提价的前提下交付更强的能力,竞争的焦点正在从"谁更便宜"转向"同等价格下谁更强"。
具体而言,推理效率的提升主要来自几个方面:模型架构层面的优化(如更高效的注意力机制和稀疏化技术)、推理基础设施的改进(如更好的GPU利用率和批处理策略)、以及蒸馏和量化等模型压缩技术的进步。这些技术红利使得模型厂商的单位推理成本持续下降,从而有空间在维持价格不变的情况下提供更强的模型。对于企业客户而言,这意味着其AI投入的ROI(投资回报率)在自然增长,无需额外投入即可获得更好的效果。
行业观察:大模型迭代进入快节奏时代
Anthropic的快速迭代节奏(从4.7到4.8)表明,大模型的更新正在从"大版本跳跃"转向"持续小步快跑"。这种模式的优势在于:
- 用户适应更平滑:每次升级幅度适中,不会造成使用习惯的剧烈变化
- 风险更可控:小幅迭代便于快速定位和修复问题
- 反馈循环更短:能够更及时地响应用户需求和市场变化
这种迭代模式借鉴了软件工程中"持续交付"(Continuous Delivery)的理念,与传统软件行业从瀑布式开发转向敏捷开发的演变路径高度相似。在AI模型领域,这种策略还有一个额外优势:它允许厂商在每次小版本更新中针对性地解决特定问题(如本次聚焦判断力和诚实度),而非试图在一个大版本中同时解决所有问题,从而降低了引入新问题的风险。同时,快速迭代也对模型评估体系提出了更高要求——厂商需要建立完善的自动化评估流水线,确保每次更新不会在改进某些能力的同时导致其他能力退化(即所谓的"能力回归"问题)。
从竞争角度看,Claude Opus 4.8的发布进一步巩固了Anthropic在高端AI模型市场的地位,尤其是在需要高可靠性和长时间自主运行的企业级AI Agent应用场景中。随着AI Agent成为行业焦点,Opus系列在自主工作能力上的持续强化,正在为Anthropic构建差异化的竞争优势。
核心要点
核心要点
相关推荐
Claude Code 4个必改设置,开发效率直接翻倍
Claude Code 4个必改设置,开发效率直接翻倍
分享Claude Code最值得修改的4个设置:权限模式绕过、聊天记录永久保留、MCP合并规则理解、全局Skill精简到7个。改完告别确认框骚扰,节省6%上下文窗口,开发体验立刻提升。
RTK终端输出压缩工具:Claude Code省下80%Token消耗
RTK终端输出压缩工具:Claude Code省下80%Token消耗
RTK是一款用Rust编写的开源终端输出压缩工具,专为Claude Code设计。通过拦截和压缩git、npm等命令输出,将Token消耗从11.8万降至2.39万,节省约80%。免费、离线、两分钟安装即用。
笨豆:16岁独立拍纪录片,全网播放破亿的10后UP主
笨豆:16岁独立拍纪录片,全网播放破亿的10后UP主
B站UP主笨豆,16岁高一学生,从四年级开始做视频,独立完成印度、蒙古国等人文纪录片拍摄,全网粉丝超百万、播放量破亿。深入了解她的纸上剪辑法、一人纪录片工作流程及创作心路历程。