Claude Opus 4.8深度解析:判断力、诚实度与性价比全面评测

Claude Opus 4.8在判断力、诚实性和持久工作能力上实现务实增强
Anthropic发布Claude Opus 4.8,定价不变但Fast Mode成本降至三分之一。核心提升体现在三方面:判断能力增强,短提示词即可完成复杂任务;诚实反馈机制优化,减少幻觉和无效输出;结合1M上下文窗口和xhigh思考模式,独立工作时间显著延长。整体属于务实迭代而非革命性突破。
Anthropic近日发布了Claude Opus 4.8模型,作为Opus系列的最新迭代,这次更新并非简单的参数堆叠,而是在判断能力、诚实反馈和独立工作时长等方面做出了务实的增强。本文将从定价策略、核心能力提升以及与竞品的对比三个维度,深入分析这次升级的实际价值。
定价策略:价格不变,Fast Mode成本骤降
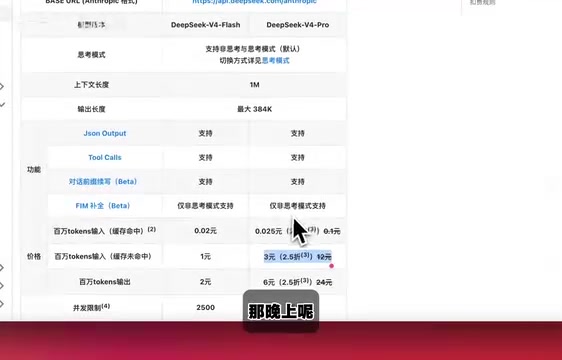
Opus 4.8的定价与上一代4.7保持一致,依旧是每百万token输入15美元、输出75美元的水平(约合人民币35元/百万输入token)。
关于Token定价机制:大模型的定价以"每百万token"为计量单位,token是模型处理文本的基本单元,大致上1个英文单词约等于1-1.5个token,1个中文字符约等于1.5-2个token。输入token(prompt)和输出token(completion)分开计价,且输出价格通常远高于输入——这是因为生成文本需要模型进行自回归推理,计算量远大于编码输入。Opus 4.8的输入/输出比价为1:5,这一比例在高端模型中较为典型,直接反映了推理计算的实际成本结构。
从绝对价格来看,这在当前大模型市场中属于高端定位——同样的预算可以调用约11次DeepSeek V4,或35次DeepSeek V4 Turbo。

不过,真正值得关注的是Fast Mode(快速模式)的成本变化。Anthropic宣称该模式的成本降至了此前的三分之一,换句话说,同样的预算在Fast Mode下可以提出三倍数量的问题。这对于日常轻量级查询场景来说是一个实质性的利好,意味着用户可以在不需要深度推理的场景下大幅降低使用成本。
从性价比角度来看,如果你的使用场景以简单问答和快速迭代为主,DeepSeek系列仍然是更经济的选择。但如果你需要处理复杂的编程任务或长上下文推理,Opus 4.8的综合能力可能更值得投入。
核心能力提升:不是更强,而是更"稳"
判断能力的质变
Opus 4.8最显著的进步并非体现在跑分数据上,而是在实际使用中的"容错率"大幅降低。具体表现为:以前需要精心构造的长提示词才能完成的复杂任务,现在用简短的提示词就能准确理解用户意图。
关于Prompt Engineering:Prompt Engineering(提示词工程)是指通过精心设计输入文本来引导大模型产生期望输出的技术实践。早期模型对提示词的格式和措辞极为敏感,细微的表达差异可能导致截然不同的结果,由此催生了"少样本提示"、"思维链提示"(Chain-of-Thought)等专门技术。模型判断能力的提升,本质上是其对用户意图的鲁棒性增强——即在输入信息不完整或表达模糊时,仍能准确推断出任务目标。这种能力的改进通常来自更大规模的RLHF(基于人类反馈的强化学习)训练和更高质量的对齐数据。
这意味着模型在语义理解和任务分解方面有了本质性的改进。对于开发者而言,这直接降低了prompt engineering的门槛——你不再需要花费大量时间去"教"模型理解你的需求,而是可以更自然地表达意图,让模型自行推断出正确的执行路径。
诚实反馈机制的优化
另一个重要改进是模型在处理任务时的"诚实度"。在之前的版本中,模型有时会生成看似合理但实际无效的输出,用户需要反复验证才能发现问题。Opus 4.8在这方面做了针对性优化,能够更坦诚地反馈自己的处理进展,包括明确告知哪些部分已完成、哪些部分存在不确定性。
关于AI幻觉与诚实性:大语言模型的"幻觉"(Hallucination)问题是指模型生成看似合理但实际错误或虚构内容的现象,是当前AI系统最核心的可靠性挑战之一。幻觉产生的根本原因在于模型的训练目标是预测下一个token的概率分布,而非验证事实真实性。Anthropic在模型对齐研究中将"诚实性"(Honesty)列为核心价值观,涵盖不欺骗、不操纵、校准不确定性等维度。Opus 4.8在诚实反馈上的改进,正是这一对齐方向的工程化落地——让模型在不确定时主动表达不确定性,而非强行生成一个置信度虚高的答案。
这种改进对于AI编程场景尤为关键。当模型在生成代码时遇到不确定的逻辑,与其"硬编"一个可能有bug的实现,不如明确标注出来让开发者介入判断。这种"知之为知之,不知为不知"的态度,反而能显著提升整体开发效率。
独立工作时间延长
结合1M上下文窗口和xhigh思考模式,Opus 4.8能够在更长时间内独立完成复杂任务,而不需要用户频繁介入纠偏。这对于大型代码重构、长文档分析等需要持续推理的场景来说是一个重要突破。
关于上下文窗口与长程推理:上下文窗口(Context Window)决定了模型在单次对话中能处理的最大token数量。1M token约等于75万个英文单词,相当于一部完整的长篇小说或数万行代码。然而,超长上下文并不等于超强推理——研究表明,大多数模型在上下文超过一定长度后,对中间位置信息的利用率会显著下降,即"迷失在中间"(Lost in the Middle)现象。xhigh思考模式通过延长模型的内部推理链(Extended Thinking),在一定程度上缓解了这一问题,使模型能在长上下文中保持更稳定的注意力分配,从而支撑更持久的独立工作能力。
与竞品的横向对比
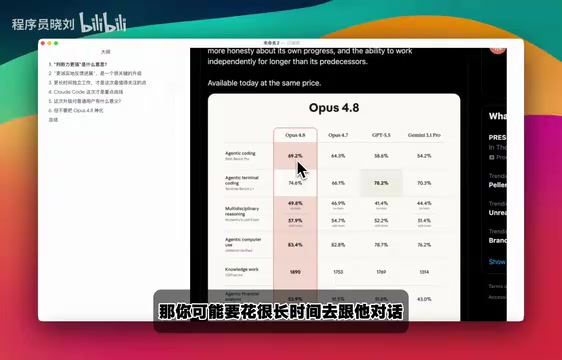
从公开的基准测试来看,Opus 4.8在AI Coding领域的表现相比GPT-5.5又上了一个台阶。但需要注意的是,基准测试与实际使用体验之间往往存在差距。
关于AI Coding基准测试的局限性:当前主流的AI编程基准测试包括HumanEval、SWE-bench、LiveCodeBench等,通过让模型解决标准化编程题或真实GitHub Issue来评估代码能力。然而,基准题目通常边界清晰、有标准答案,而实际工程问题往往涉及模糊需求、遗留代码和跨文件依赖。此外,随着模型训练数据可能包含基准题目,"数据污染"问题也使得高分的参考价值逐渐降低。因此,在解读"超越GPT-5.5"这类基准对比时,需结合具体测试集的设计和真实使用场景综合判断,而非将其视为绝对的能力排名。
当前大模型竞争已经进入了一个新阶段:单纯的能力提升已经不足以形成差异化优势,用户更关注的是模型在真实场景中的稳定性和可靠性。从这个角度来看,Opus 4.8选择在"稳定性"和"判断力"上下功夫,而非一味追求跑分,是一个相当务实的策略。
理性看待:务实增强而非革命性突破
总结来看,Claude Opus 4.8的升级可以概括为三个关键词:
- 判断更稳:短提示词即可完成复杂任务,降低了使用门槛
- 反馈更诚实:减少无效输出,提升人机协作效率
- 独立工作更持久:长上下文+深度思考模式,适合复杂项目
不需要将Claude神化,它并没有彻底改变一切。但作为一次务实的迭代升级,Opus 4.8在保持价格不变的前提下,切实解决了上一代模型在实际使用中的痛点。对于重度AI编程用户和需要处理复杂长文本任务的专业人士来说,这次升级值得认真评估。
对于预算有限的个人开发者,建议优先体验Fast Mode的降价红利;而对于企业级用户,xhigh思考模式配合1M上下文窗口的组合,可能会在复杂项目中带来显著的效率提升。
核心要点
- Claude Opus 4.8定价与4.7保持不变,但Fast Mode成本降至此前的三分之一
- 核心提升在于判断能力增强,短提示词即可完成此前需要长提示词的复杂任务
- 模型诚实反馈机制改进,减少无效输出,能更坦诚地汇报处理进展
- 独立工作时间显著延长,配合1M上下文和xhigh思考模式适合复杂项目
- AI Coding基准测试超越GPT-5.5,但属于务实增强而非革命性突破
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。