CLIProxyAPI部署教程:聚合多平台AI账号,免费Token无限用
CLIProxyAPI可聚合多个AI平台账号,统一管理免费额度实现低成本AI使用。
CLIProxyAPI(CPA)是一个开源API代理聚合服务器,能将OpenAI、Gemini等多个AI平台的账号集中到统一接口下,通过负载均衡式的多账号轮询和配额管理,将分散的免费额度汇聚成可观的资源池。文章详细介绍了基于Docker和Zipper平台的部署流程、AI客户端接入方法及批量注册账号的技巧,同时提醒了合规性、时效性和稳定性方面的风险。
前言
在AI工具百花齐放的今天,不少人手头同时握着OpenAI、Gemini、CodeX等好几个平台的账号。来回切换不同的AI服务不仅麻烦,密钥和配额的管理更是一团乱麻。CLIProxyAPI(CPA) 就是为了解决这个问题而诞生的开源代理服务器——它能把多个AI平台的账号聚合到同一个API接口下,实现集中管理、统一调用。
更值得关注的是,目前不少AI厂商都给免费账户开放了一定的使用额度。主流AI厂商普遍采用"免费层+付费层"的定价策略来吸引开发者——例如OpenAI为新注册用户提供一定的免费API调用额度,Google的Gemini API在免费层提供每分钟一定次数的请求配额,Anthropic的Claude也有类似的试用额度。这些免费额度的设计初衷是降低开发者的试用门槛,但单个账号的免费量通常只够进行基础测试。这里需要了解一个基本概念:Token是大语言模型计费的基本单位,一个Token大约对应英文中的4个字符或中文的1-2个字符,一次普通对话可能消耗数百到数千个Token。单个账号的免费额度可能只够聊几轮,但如果你手上有大量账号,通过CPA做聚合管理,累积起来的免费Token总量相当可观,完全能覆盖个人日常使用。
什么是CLIProxyAPI?一个AI账号的负载均衡器
CLIProxyAPI本质上是一个API代理聚合服务器,核心功能包括:
- 多账号聚合:将OpenAI、Gemini、CodeX等多个平台的多个账号集中到一个服务中
- 统一API接口:对外提供标准化的API端点,兼容主流AI客户端
- 配额管理:可视化查看每个Token的使用情况和剩余配额
- 密钥管理:统一管理API密钥,无需在客户端频繁切换
简单来说,CPA就像一个AI账号的"负载均衡器",把分散在各平台的免费额度汇聚成一个可用的资源池。负载均衡(Load Balancing)是分布式系统中的经典架构模式,最早广泛应用于Web服务器集群,通过将请求分发到多个后端节点来提高系统的吞吐量和可用性。常见的负载均衡策略包括轮询(Round Robin)、加权轮询、最少连接数等。CLIProxyAPI将这一思路移植到了AI API管理领域——它不是在多台服务器之间分发流量,而是在多个AI平台账号之间轮询请求,同时监控每个账号的配额消耗情况,自动跳过已耗尽额度的账号。这种设计模式在API网关(API Gateway)领域也很常见,Kong、Tyk等开源网关都提供类似的多上游(upstream)管理能力。
这跟之前Groq API的玩法类似——单个免费账号额度有限,但多个账号聚合后就能形成可观的使用量。
CLIProxyAPI Docker部署教程(基于Zipper平台)
第一步:创建Docker服务
本次部署使用Zipper平台(一个便捷的服务器管理工具)。如果你还没有Zipper账号,需要先注册并添加自己的服务器。
在开始之前,简单了解一下Docker的工作原理会有帮助:Docker是一种操作系统级别的虚拟化技术,它将应用程序及其所有依赖项打包到一个标准化的容器(Container)中,确保应用在任何环境中都能一致运行。与传统虚拟机相比,Docker容器共享宿主机的操作系统内核,启动速度更快、资源占用更少。Docker镜像(Image)是容器的只读模板,包含了运行应用所需的代码、运行时、库和配置文件。
具体步骤如下:
- 登录Zipper后台,点击**「新建服务」,选择Docker**方式
- 输入CPA的Docker镜像地址
- 配置环境变量,变量只需输入
Cloud - 添加端口映射:将默认的3000端口改为8370
- 添加数据卷:卷ID输入
Data,挂载路径同样输入Data - 输入启动命令后,点击部署
这里涉及两个Docker的核心概念:端口映射(Port Mapping) 是Docker网络的核心机制之一,它将容器内部的端口映射到宿主机的端口,使外部网络能够访问容器内的服务——在这里就是把CPA服务从容器内部暴露到宿主机的8370端口。数据卷(Volume) 则是Docker提供的持久化存储机制,即使容器被删除或重建,挂载在数据卷中的数据也不会丢失,这对于保存CPA的配置文件和Token数据至关重要。
第二步:绑定域名与编辑配置文件
部署启动后,接下来进行域名绑定和配置文件设置:
- 添加域名:在Zipper后台添加一个自定义域名,输入你想要的名称,点击绑定。域名旁边变成绿色就说明绑定成功了
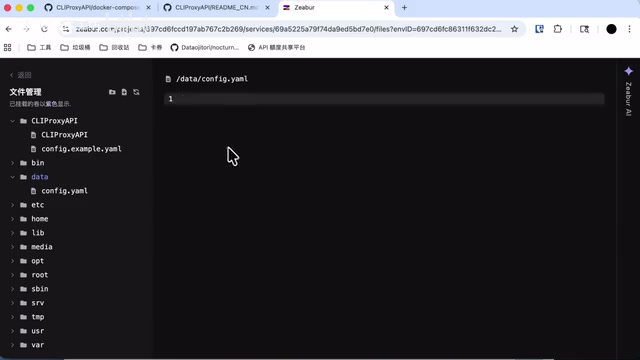
- 编辑配置文件:等服务状态显示为"运行中"后,进入文件管理,在
Data目录下找到Config文件(如果没有显示,退出后重新进入即可) - 填写关键配置:
Key:后台登录密码(例如Separate123)API Key:对外提供的API密钥
- 保存配置后,重启服务使配置生效
第三步:登录后台并上传Token
通过绑定的域名访问CPA后台:
- 在域名后添加后台路径,跳转到登录页面
- 输入之前设置的密钥登录
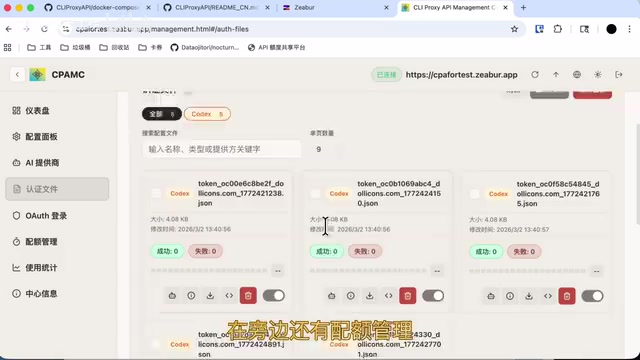
- 进入**「认证文件」**页面,上传你的AI平台Token
- 在**「配额管理」**中可以查看每个Token的当前使用情况
- 在**「仪表盘」**中可以看到已连接的BaseURL地址
如何在AI客户端中接入CPA
部署完成后,就可以在任意支持自定义API的AI客户端中使用了。这里的关键在于CPA对外提供的统一API接口遵循的是OpenAI API的事实标准格式,这一格式已经成为AI行业的通用协议。其核心端点包括/v1/chat/completions(聊天补全)、/v1/models(模型列表)等RESTful接口,请求和响应均采用JSON格式。由于OpenAI最早定义了这套API规范,后来的大量AI客户端(如ChatBox、NextChat、LobeChat等)和开发框架(如LangChain、LlamaIndex)都内置了对这一格式的支持。这意味着只要CPA正确实现了这套接口规范,几乎所有主流AI客户端都可以无缝接入,无需任何额外的适配工作。
具体接入步骤:
- 在客户端中新建一个API配置,输入名称
- BaseURL填写仪表盘中显示的地址(BaseURL的作用就是告诉客户端将请求发送到CPA的地址而非OpenAI的官方地址,实现请求的透明代理)
- API Key在CPA后台的「管理密钥」中复制
- 添加完成后获取模型列表,选择需要的模型(如CodeX系列)并开启
- 进入聊天界面,选择刚配置的CPA服务和对应模型,即可开始对话
整个过程对客户端来说是透明的——它只需要对接CPA这一个API端点,背后的多账号轮询和配额管理全部由CPA自动处理。
批量注册OpenAI账号的方法与注意事项
要充分发挥CPA的聚合优势,拥有足够多的账号是关键。目前有一些自动化注册脚本可以使用,基本流程如下:
- 获取OpenAI注册脚本(Python编写)
- 创建Python虚拟环境:
python3 -m venv env - 激活虚拟环境并安装依赖包
- 运行注册脚本
关于Python虚拟环境,这里做一个简要说明:Python虚拟环境(Virtual Environment)是Python生态中隔离项目依赖的标准做法。通过python3 -m venv命令创建的虚拟环境会在项目目录下生成一个独立的Python解释器副本和包管理空间,避免不同项目之间的依赖冲突。自动化注册脚本通常依赖Selenium或Playwright等浏览器自动化框架来模拟用户操作,或者直接调用平台的注册API接口。这类脚本需要处理验证码识别、邮箱验证、IP风控等多重挑战。
需要特别注意的几点:
- 你的IP地址必须属于ChatGPT允许访问的国家/地区,否则注册会直接失败
- 在本地网络环境下成功率偏低,建议在海外服务器上运行脚本,成功率会明显提高。海外服务器成功率更高的原因在于:一方面避免了某些地区的网络访问限制,另一方面海外数据中心的IP地址在平台风控系统中的信誉评分通常更高
- 脚本运行过程中部分注册失败是正常现象,多跑几次就行
风险提示与使用建议
潜在风险
虽然这套方案看起来很诱人,但有几个风险必须提前了解:
- 合规性问题:批量注册账号可能违反各平台的服务条款,存在被封号的风险。大多数AI平台在其服务条款(Terms of Service)中明确禁止一人持有多个账号,违反者可能面临所有关联账号被永久封禁的处罚
- 时效性:免费额度政策随时可能调整,厂商也可能加强反滥用检测。AI厂商通常会通过设备指纹、IP关联分析、使用模式识别等手段来检测批量注册和滥用行为,这些风控系统在持续升级
- 稳定性:依赖免费Token的方案本身不够稳定,不适合在生产环境中使用
总结
CLIProxyAPI作为一个API聚合代理工具,设计思路非常实用——统一接口、集中管理、自动轮询。对于个人用户来说,它提供了一种低成本甚至零成本使用多个AI模型的途径。配合Zipper等部署工具,整个搭建过程也并不复杂。
不过,"免费午餐"往往伴随着不确定性。建议把它当作学习和体验的工具,如果有稳定的使用需求,还是应该考虑付费方案。技术本身是中性的,关键在于怎么合理使用。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。