Cloudflare AI Search实战:零基础搭建智能知识库问答系统

Cloudflare AI Search:托管式RAG服务的部署与架构解析
Cloudflare推出AI Search托管式RAG服务,免去自建向量数据库和GPU服务器的运维负担。它支持R2存储和网站爬取两种数据源,采用递归式文本切分、两阶段检索(向量召回+Reranker精排)和语义缓存机制,通过六步控制台向导即可完成部署,大幅降低了构建智能搜索应用的门槛。
什么是 Cloudflare AI Search?
Cloudflare 近期推出了 AI Search——一项托管式 RAG(检索增强生成)服务。它能够自动索引用户的知识库,并通过自然语言查询返回精准答案。
RAG 技术背景:RAG(Retrieval-Augmented Generation)是一种将信息检索与大语言模型生成能力结合的架构范式。传统 LLM 存在知识截止日期和幻觉(Hallucination)问题,RAG 通过在生成答案前先从外部知识库检索相关文档片段,再将其作为上下文注入提示词,从而让模型基于真实数据作答。这一架构由 Meta AI 在 2020 年的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中正式提出,此后迅速成为企业级 AI 应用的主流方案。
与传统的 RAG 方案相比,AI Search 的核心优势非常明显:
- 无需自建向量数据库:省去了 Pinecone、Weaviate 等向量数据库的运维成本
- 无需管理 GPU 服务器:所有模型推理由 Cloudflare Workers AI 完成
- 全球网络深度集成:依托 Cloudflare 遍布全球的边缘节点,响应速度极快
向量数据库原理:嵌入模型(Embedding Model)将文本映射为高维向量空间中的数值表示,语义相近的文本在向量空间中距离更近。向量数据库专门存储和检索这些向量,通过近似最近邻(ANN)算法在毫秒级完成语义相似度搜索。自建这套体系需要处理向量维度选择、索引策略、分片扩容等复杂运维问题,而 Cloudflare 将其封装为托管服务,底层依托自研的 Vectorize 向量数据库。
简单来说,AI Search 让开发者可以快速构建生产级的智能搜索应用,而不必操心底层基础设施。本文将从零开始,完整演示如何创建和部署一个基于 AI Search 的知识库问答系统。
部署前的准备工作
准备数据源(R2 存储桶)
Cloudflare AI Search 目前支持两种数据源模式:
- R2 存储:上传文件到 Cloudflare R2 对象存储
- 网站爬取:AI Search 自动爬取指定网站页面
如果选择网站模式,AI Search 会自动抓取页面内容进行索引。本次演示以 R2 存储为例,提前在 R2 桶中存放了几个 PDF 文件作为知识库。
AI Search 支持的文件类型相当丰富:
| 类型 | 支持格式 |
|---|---|
| 纯文本 | TXT、JSON、YAML、JS 等 |
| 富文本 | PDF、HTML、CSV、PNG 等 |
有意思的是,AI Search 会自动将富文本文件转换为 Markdown 格式进行处理,这意味着即使是 PDF 中的复杂排版,也能被有效解析和索引。
创建 AI Gateway
AI Search 在不同处理阶段(文本向量化、查询重写、答案生成)都需要调用 AI 模型,而这些调用统一通过 AI Gateway 来管理。
创建 AI Gateway 的步骤非常简单:进入 AI Gateway 页面,点击创建,为 Gateway 起一个名字,其他配置保持默认即可。AI Gateway 不仅是模型调用的统一入口,还提供了日志记录、速率限制、请求追踪等管理能力——这对于生产环境中监控 AI 调用成本和排查问题至关重要。
创建 AI Search 实例:分步详解
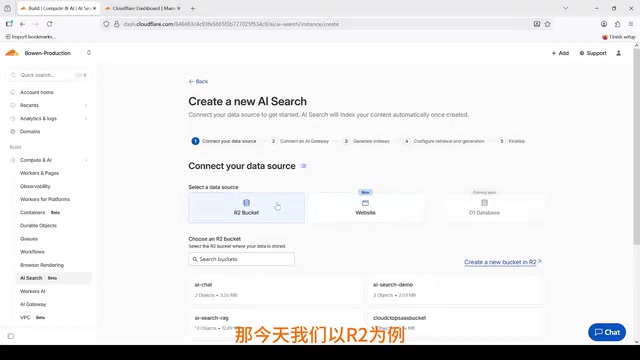
第一步:选择数据源
在 Cloudflare 控制台导航到 AI Search 页面,点击 Create 按钮开始创建实例。首先选择之前准备好的 R2 桶作为数据源。
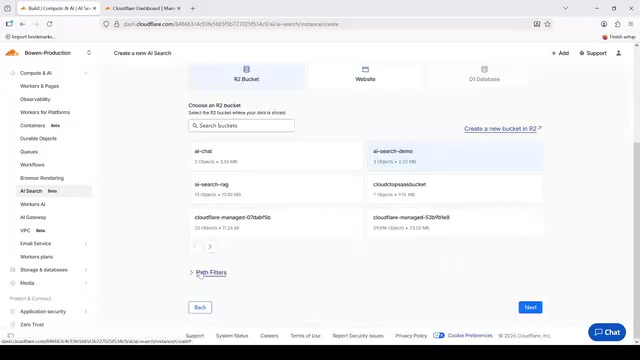
下方的 Pass Filter 选项可以控制知识库的索引路径。如果文件放在根目录下,则无需额外配置;如果文件组织在特定子目录中,可以通过路径过滤来精确控制索引范围。
第二步:配置 AI Gateway
选择刚刚创建的 AI Gateway。这一步将 AI Search 与模型调用通道关联起来,后续所有的模型推理请求都会通过该 Gateway 路由。
第三步:嵌入模型与文本切分
嵌入模型(Embedding Model) 负责将文本转化为向量表示,这是语义检索的基础。嵌入模型通过神经网络将任意长度的文本压缩为固定维度的稠密向量(通常为 768 或 1536 维),使得"苹果手机"和"iPhone"这类语义相近的表达在向量空间中距离更近,从而支持超越关键词匹配的语义搜索。Cloudflare Workers AI 内置了多种嵌入模型,免去了用户自行处理数据向量化的复杂过程。这里选择默认的嵌入模型即可。
文本切分(Chunking) 是向量化之前的关键步骤——将大文档拆分为更小的内容片段。AI Search 采用递归式切分方式,其策略是:
- 优先在段落或句子的自然边界进行拆分
- 如果内容仍然过大,再继续细分
- 通过 Overlap(重叠) 机制,让相邻切片之间保留一部分重叠文本
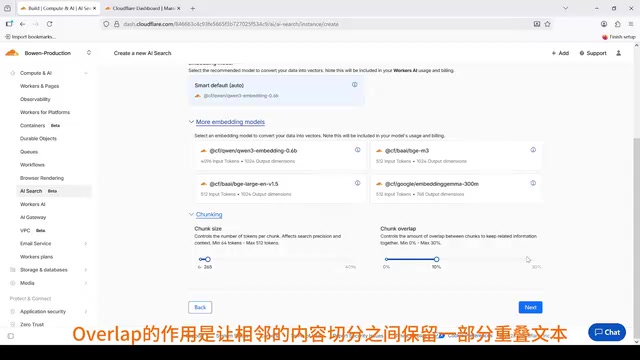
递归式切分深度解析:递归式切分(Recursive Character Text Splitting)是 LangChain 等框架推广的主流策略,按照段落 → 句子 → 词语的优先级依次尝试切分,尽量在语义完整的边界处断开。Overlap 重叠机制通常设置为 chunk size 的 10%-20%,例如 chunk 大小为 512 tokens 时,相邻 chunk 共享约 50-100 tokens 的内容。这样即使某个关键概念恰好跨越切分边界,也能在至少一个 chunk 中完整保留,避免语义断裂导致的检索失效。
Overlap 的设计非常巧妙——它避免了关键信息被切断的问题。例如一个跨段落的重要概念,如果恰好被切分到两个片段的边界,重叠区域可以确保语义检索时上下文更完整,命中结果更准确。
第四步:重新排序模型(Reranker)
这一步选择用于**重新排序(Reranking)**的模型。Reranker 的作用是在初步检索完成后,使用第二个模型对候选结果进行重新打分和排序,再输出最终结果。
这是一个两阶段检索架构:
- 第一阶段:基于向量相似度的粗筛,快速召回候选结果
- 第二阶段:Reranker 精排,显著提高结果的相关性和质量
两阶段检索原理:两阶段检索是现代搜索系统的标准范式。第一阶段使用轻量级向量检索快速召回 Top-K 候选(通常 20-100 个),追求高召回率;第二阶段使用计算代价更高的**交叉编码器(Cross-Encoder)**模型对候选结果逐一打分重排,追求高精确率。Cross-Encoder 会同时处理查询和文档的完整语义关系,比第一阶段的双塔模型(Bi-Encoder)精度更高,但因为无法预先计算文档向量,所以不适合用于大规模初筛。这种分层架构在精度和效率之间取得了最优平衡。
同时还可以配置最大回复结果数量和相似度阈值,这里保持默认设置即可。
第五步:语义缓存
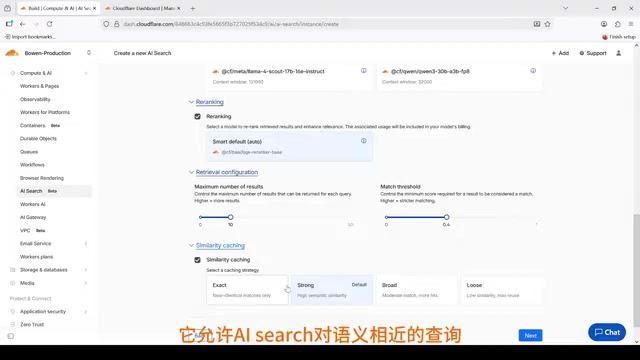
基于相似度的语义缓存是 AI Search 的一大亮点。它允许系统对语义相近的查询直接命中 Cloudflare 缓存,而不是每次都重新生成答案。
语义缓存工作原理:语义缓存不同于传统的精确字符串匹配缓存,它将历史查询也向量化存储,当新查询到来时,先计算其与缓存查询的向量相似度,若超过设定阈值则直接返回缓存答案。这一机制在 Cloudflare 边缘节点层面实现,意味着缓存命中时请求甚至不需要到达后端模型服务。对于企业知识库场景,用户提问往往高度集中在少数热点问题上,语义缓存的命中率通常可达 30%-60%,显著降低 LLM API 调用成本。
举个例子:用户 A 问"如何配置 DNS?",用户 B 问"DNS 怎么设置?"——这两个问题语义高度相似,第二次查询可以直接复用第一次的缓存结果。这样做的好处是:
- 降低成本:减少模型调用次数
- 提高速度:缓存命中时响应几乎是即时的
第六步:命名与授权
最后一步,为 AI Search 实例起一个名字,并配置 Service API Token。这个 Token 赋予 AI Search 访问和配置 Cloudflare 账户资源的权限,包括 R2、Vectorize 和 Workers AI。没有它,AI Search 就无法索引数据或响应查询。
可以创建一个新的 Token,也可以使用现有的。点击 Create,AI Search 实例就创建完成了。
架构总结与思考
回顾整个创建流程,Cloudflare AI Search 实际上封装了一套完整的 RAG 管线:
文档上传 → 文本提取 → 切分 → 向量化 → 索引存储
↓
用户查询 → 查询重写 → 向量检索 → Reranker精排 → 答案生成
这套流程如果自建,通常需要整合文档解析器、向量数据库、嵌入模型 API、LLM API 等多个组件,开发和运维成本不低。而 AI Search 将这一切打包成了一个托管服务,对于中小团队或快速原型验证来说,是一个非常实用的选择。
当然,托管服务也意味着在模型选择、切分策略等方面的灵活性有所限制。对于有深度定制需求的场景——例如需要使用私有部署的嵌入模型、自定义 Reranker 训练,或对数据主权有严格要求的企业——可能仍需考虑自建方案。但作为快速上手 RAG 应用的起点,Cloudflare AI Search 无疑大幅降低了门槛。
核心要点
- Cloudflare AI Search 是托管式 RAG 服务,无需自建向量数据库和 GPU 服务器即可构建智能搜索应用
- 支持 R2 存储和网站爬取两种数据源,可处理 PDF、HTML、CSV 等多种富文本格式并自动转换为 Markdown
- 采用递归式文本切分和 Overlap 重叠机制,确保语义检索时上下文完整、命中准确
- 内置两阶段检索架构(向量召回 + Reranker 精排)和语义缓存机制,兼顾检索质量与响应速度
- 整个部署流程通过控制台向导完成,涵盖数据源、AI Gateway、嵌入模型、排序模型、缓存策略等六个配置步骤
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。