CodeGraph实测:代码图索引工具真能省Token吗?结果出乎意料

CodeGraph通过本地语义图网络解决AI编码工具逐文件扫描效率低下的问题
CodeGraph利用Tree-sitter将源代码解析为AST并构建本地SQLite语义图数据库,通过MCP协议让AI一次图查询即可获取精确的符号信息和调用链,替代传统的反复搜索-读取循环。实测显示虽然费用和耗时上升,但缓存命中率翻倍、模型输出量暴涨6倍,说明AI理解深度显著提升。其局限在于静态分析无法覆盖反射、元编程等动态行为。
AI编码工具的结构性痛点:逐文件扫描效率低下
当前主流AI编码工具,无论是Claude Code还是Cursor,处理大型代码库时都面临同一个结构性问题:为了理解项目架构,AI需要反复执行「搜索→读取→再搜索」的循环。先用Grep定位关键词,找到文件后再逐一读取,如此往复。
这个过程的代价是双重的——大量消耗Token,以及频繁的工具调用带来的延迟堆叠。在复杂项目中,AI很容易陷入反复横跳却始终找不到核心调用链的困境。这不是模型能力的问题,而是信息获取方式的结构性缺陷。
CodeGraph的核心解法:本地语义图网络
CodeGraph针对的正是这个问题。它的核心做法是把静态代码分析和本地检索做了深度融合。
具体来说,CodeGraph利用Tree-sitter在本地将源代码解析为抽象语法树(AST),函数、类、接口被抽象为图中的节点,调用关系、继承关系、模块导入则被定义为边,整张图存入本地的SQLite数据库。AI在需要理解代码结构时,不再需要逐文件盲目扫描,而是通过MCP协议向本地数据库发出一次图查询,直接取回所需的符号信息和上下文切片。
技术背景:Tree-sitter与抽象语法树(AST)
Tree-sitter是由GitHub开发并开源的增量解析库,最初为代码编辑器的语法高亮和代码导航而设计。它的核心优势在于「增量解析」——当代码发生局部修改时,无需重新解析整个文件,只更新变化的子树,这使其在实时编辑场景下极为高效。Tree-sitter目前支持超过100种编程语言的语法定义,已成为Neovim、GitHub Copilot等工具的底层解析引擎。
抽象语法树(AST)是源代码的树形结构表示,它剥离了括号、分号等语法噪音,只保留程序的逻辑骨架。例如一个函数调用
foo(a, b)在AST中会被表示为「调用节点→函数名节点+参数列表节点」的层级结构。CodeGraph正是借助Tree-sitter将AST进一步抽象为图结构,把函数、类等符号提取为节点,把调用关系提取为有向边,从而构建出可被高效查询的语义网络。
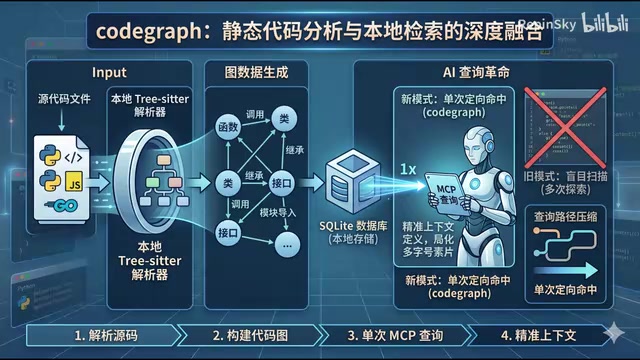
查询路径从多次探索压缩为单次定向命中,这是一个质的飞跃。
框架感知:不止于符号匹配
你可能没注意到,CodeGraph不止做简单的符号匹配,还能识别主流后端框架的路由映射、追踪事件流的触发链路,以及React状态更新到渲染的完整路径。这意味着AI可以做到真正意义上的端到端调用链追踪,而不是停留在单个函数层面的局部理解。
CodeGraph带来的三个工程价值
从工程价值角度来看,CodeGraph带来三方面改善:
- Token消耗优化:AI获取的是结构化的精确上下文,而非原始文件内容的大段重复读取
- 响应速度加快:整个索引和查询流程完全在本地完成,没有网络依赖
- 代码隐私保障:项目结构不会流转到任何第三方服务
技术背景:MCP协议
MCP(Model Context Protocol)是Anthropic于2024年11月发布的开放协议,旨在标准化AI模型与外部工具、数据源之间的交互方式。在MCP出现之前,每个AI工具都需要为不同的数据源单独开发集成接口,形成大量重复的「M×N」适配工作。MCP通过定义统一的服务器-客户端通信规范,将这一问题简化为「M+N」——工具开发者只需实现一次MCP服务器,即可被所有支持MCP的AI客户端(如Claude Code、Cursor等)调用。
MCP协议的核心抽象包括三类能力:Resources(数据资源读取)、Tools(可执行操作)和Prompts(预设提示模板)。CodeGraph作为MCP服务器,将本地SQLite图数据库封装为标准化的查询工具,AI客户端通过MCP协议发出结构化查询请求,获取精确的符号信息和调用链切片,整个过程完全绕过了传统的文件系统遍历。
适用边界:静态分析的天然局限
任何工具都有其适用范围。对于大量依赖反射、元编程或复杂依赖注入的项目,静态分析本身存在天花板,无法覆盖运行时的动态行为。在极大规模的遗留代码库中,首次构建图索引的资源占用也需要纳入评估。
技术背景:静态分析与动态分析的边界
静态分析是在不执行代码的前提下对源代码进行结构和语义分析的技术,其优势在于速度快、无需运行环境、可覆盖全量代码路径。但静态分析存在一个根本性的局限:它无法处理运行时才能确定的行为。
典型的挑战场景包括:Java/Spring中大量使用的反射机制(
Class.forName()动态加载类)、依赖注入框架(Spring IoC容器在运行时动态装配Bean)、Python的__getattr__魔术方法、以及各类元编程技术(如Ruby的method_missing)。这些模式下,函数调用的目标在编译期无法确定,静态分析工具只能看到「有一次动态调用」,却无法追踪其具体指向。动态分析(如运行时追踪、插桩)可以弥补这一缺口,但代价是需要实际执行代码,且只能覆盖特定的执行路径。CodeGraph选择静态分析路线,意味着它在上述场景中的调用链追踪会出现断点,这是工具设计上的合理取舍,而非缺陷——对于大多数结构清晰的现代代码库,静态分析已能覆盖绝大部分有价值的调用关系。
Unity项目实测:费用上升但质量碾压
为了验证CodeGraph的实际效果,作者用两个相同的Unity工程做了对比实测。两边都使用Claude终端加DeepSeek v4,执行相同的提示词。
表面数据:费用和耗时双双上升
右边启用了CodeGraph并构建本地索引,但总费用不仅没有降低,反而从1.13美元飙升到了1.87美元。API耗时也直接翻倍。
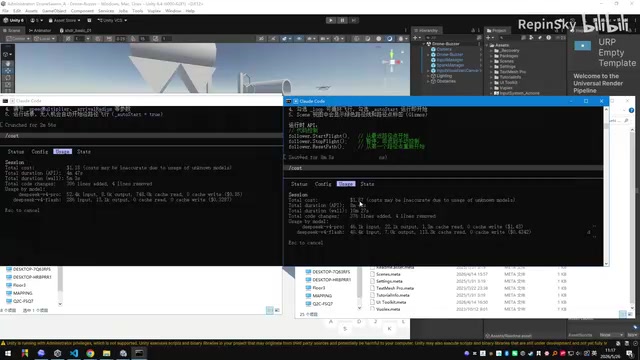
这难道说明CodeGraph的本地索引是个鸡肋吗?
深层数据:一个高级的反直觉现象
恰恰相反。仔细看底层数据,会发现一个非常有趣的反直觉现象。
CodeGraph确实起作用了——右边的提示词缓存命中量高达1.3M token,几乎是左边的两倍。这说明它成功帮模型精准定位了文件,在输入端大幅瘦身。
但为什么总价反而高了?答案藏在Output Token里:右边的模型输出量整整暴涨了6倍。
技术背景:提示词缓存(Prompt Caching)机制
提示词缓存是Anthropic为Claude API推出的成本优化机制,允许将重复出现的上下文内容
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。