Codex Browser Use 实测:GPT 5.5 驱动的 AI 浏览器自动操控到底有多强?

Codex Browser Use 实测:GPT 5.5 驱动的 AI 浏览器自动操控到底有多强?
当 AI 不再只是帮你写代码,而是像真人一样打开浏览器、点击按钮、填表单、找 bug——Codex 的 Browser Use 功能正在把这件事变成现实。OpenAI 最新推出的 Codex 桌面应用,由 GPT 5.5 驱动,把浏览器自动操控、桌面控制、自动化测试塞进了同一个平台。这篇文章带你完整看一遍它到底能做什么、怎么用、以及哪些地方值得警惕。
本文基于海外博主的抢先体验视频整理,视频来源:BiliBili
GPT 5.5 加持下的 Codex,凭什么叫"超级应用"?
"超级应用"这个词在科技圈已经被用滥了,但 Codex 这次可能真的配得上。
OpenAI 的 Codex 应用由 GPT 5.5 驱动,功能覆盖面相当广:数据分析、应用开发、游戏构建、Web 开发、浏览器操控、计算机控制,基本上你能想到的开发相关场景它都想插一脚。
最能说明问题的是一个数字:GPT 5.5 在 OS World Verified 基准测试中拿到了 78.7% 的得分。这个基准专门衡量 AI 能不能自主操作真实的计算机环境——打开软件、管理文件、浏览网页这些事。要知道,2024 年初最先进的模型在这个测试上通常连 20% 都拿不到,短短一年多时间,能力直接翻了好几倍。
不过冷静想想,还有 21.3% 的失败率。在真实生产环境中,每五次操作就有一次可能出错,这个数字放在任何 QA 标准里都不算及格。但方向是对的,而且 GPT 5.5 同时具备显著更高的 token 效率——完成同样的任务消耗更少的计算资源。这才是真正的杀手锏,因为它直接决定了这类 AI Agent 能不能从烧钱的实验室走进普通开发者的日常。
Browser Use 插件:AI 自己写代码、自己测代码的闭环
这是整个产品最精妙的设计。
OpenAI 在 Codex 中以插件形式推出了 Browser Use 功能,干的事情说白了就是:让 AI 写完前端代码之后,自己打开浏览器,像真实用户一样点击测试。它能看到用户看到的一切画面,同时还会检查控制台日志和网络日志,发现问题直接自动修复。
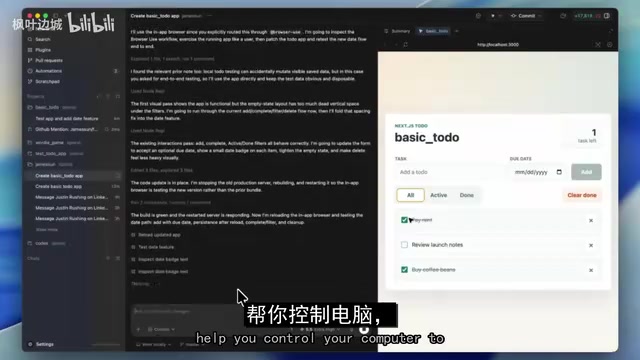
传统软件开发中,写代码和测试代码之间有一道巨大的鸿沟——开发者写完代码后要切换思维模式,去想"用户会怎么用"。Codex 把这个闭环彻底打通了:同一个 AI 既是建筑师又是质检员。
但这里有一个深层悖论值得警惕——让同一个 AI 既写代码又测试代码,本质上是"自己批改自己的作业"。它可能会系统性地忽略自己认知盲区中的 bug。真正的软件质量保障需要的是对抗性思维,而不是自洽性验证。这个闭环看起来很美,但可能制造一种危险的虚假安全感。
Computer Use 速度提升 42%:AI 操作 GUI 终于跟上了真人
由于大量用户涌入使用浏览器操控和计算机操控功能,OpenAI 做了一次重大性能更新:Computer Use 的运行速度提升了 42%。
这意味着什么?这是第一次大语言模型操作图形界面的速度能跟真人相当。过去所有的 AI 自动化都卡在一个瓶颈上:API 驱动的自动化快但脆弱(接口一改就废),GUI 驱动的自动化灵活但慢到没法用。现在这个瓶颈正在被打破。
另一个值得关注的点是定价策略:Codex 完全免费,支持 Windows 和 macOS。OpenAI 显然在用 Codex 做用户增长的钩子,用海量真实使用数据来喂养模型迭代。你以为你在免费用工具,其实你在免费给 OpenAI 做数据标注。这不是慈善,这是最精明的数据飞轮策略。
手把手教程:怎么在 Codex 中启用 Browser Use
操作流程其实不复杂:
- 安装登录:下载 Codex 桌面应用,登录后在主面板保持默认权限
- 创建项目:先新建一个项目
- 安装插件:使用斜杠命令(
/)或者点击加号,进入 Plugins 面板,找到 Browser Use 插件并安装 - 启用功能:在聊天面板中通过
app命令启用 Browser Use - 开始使用:可以让它发邮件、测试结账流程、打开网页等等
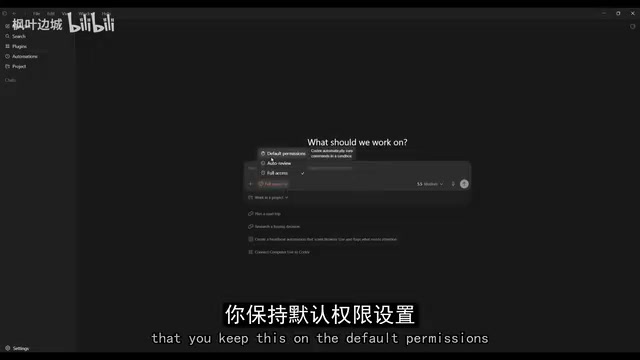
一个实用小技巧:对于简单任务,可以把智能等级设为 Low,省下 rate limit 配额。不过这里有个隐患——当开发者习惯性地为了省配额而降低 AI 智能等级时,实际上是在用质量换数量。简单任务上无所谓,但一旦形成习惯,关键任务也可能被"降级处理"。
自动化工作流:定时抓取 AI 新闻生成 PDF
Codex 不只是一次性工具,它还能设置自动化任务。
演示案例是这样的:设置一个每天自动运行的任务,用 Browser Use 抓取最新的 AI 话题,然后生成一份 PDF 新闻汇总。系统会自动抓取所有来源,并在页面底部列出引用。
这个案例精准击中了信息焦虑时代的痛点。但让我们诚实面对:这类自动化工作流的真正价值不在于"能做",而在于"做得可靠"。网页结构变了怎么办?源站反爬了怎么办?生成的摘要出现幻觉怎么办?
演示永远是完美的,但生产环境中的自动化任务需要的是 99.9% 的可靠性。真正的考验不是 Day 1 的惊艳,而是 Day 30 还能不能稳定运行。
用 AI 测试 AI 写的应用:Notes App 实测
博主用 GPT 5.5 生成了一个简单的笔记应用,然后用 Browser Use 来测试用户流程。效果确实让人眼前一亮:
- AI 自动与应用的所有组件交互——添加新任务、写笔记
- 能走完注册登录的完整流程,像真实用户一样点击每个按钮
- 能捕获 bug、控制台错误和网络错误
- 整个测试流程还可以设成自动化定期运行
这对独立开发者和小团队来说是真正的福音:过去你需要专门的 QA 工程师来做端到端测试,现在 AI 可以在几分钟内走完整个用户流程。
但有一个被忽视的风险:AI 的测试路径是基于"合理用户行为"的假设,而真实用户最擅长的恰恰是做出不合理的操作。一个三岁小孩随机点击屏幕发现的 bug,可能比 AI 系统性测试一百遍发现的都多。AI 测试是补充,不是替代。
游戏测试演示:让 AI 自己下国际象棋找 bug
为了展示 Browser Use 能测试更复杂的应用,博主创建了一个国际象棋游戏,然后让 AI 自己下棋来验证功能。
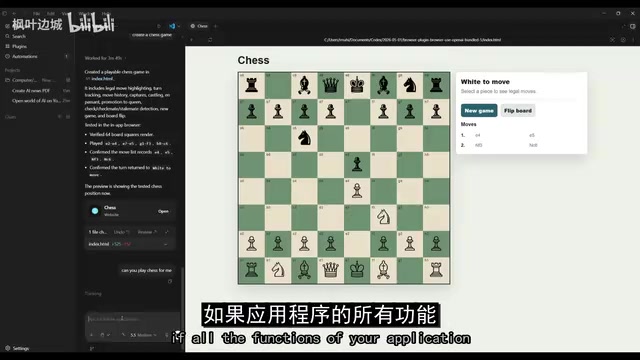
你可以智能提示 Browser Use 去做特定的事情:捕获控制台 bug、检查视觉异常、验证特定功能是否正常。AI 能实时发现问题并修复,实现"待命状态下的自动 bug 修复"——这个概念确实令人兴奋。
不过说句实话,国际象棋是规则完全确定的系统,AI 当然能测得很好。但真实的游戏测试需要验证的是物理引擎的边界情况、多人同步的网络延迟、极端操作下的内存泄漏——这些才是让游戏开发者彻夜难眠的问题。用最简单的场景做演示,然后暗示它能处理最复杂的情况,这是所有 AI 产品演示的经典套路。
Computer Use:让 AI 帮你整理桌面文件
Computer Use 功能不限于浏览器,它可以直接操控桌面。演示案例是让 AI 整理桌面上一堆杂乱的缩略图文件,AI 很快就把所有文件按数字 1-15 重新命名并整理好了。
坦白说,这是整个演示中最"杀鸡用牛刀"的环节。一个 shell 脚本十行代码就能搞定的事情,动用了 GPT 5.5 级别的 AI 来做视觉识别和鼠标点击。
但 OpenAI 展示这个案例的真正意图不是解决文件整理问题,而是在说:"看,我们的 AI 能操作你电脑上的一切。" 这是在为更复杂的桌面自动化场景铺路——想象一下 AI 帮你操作 Excel、Photoshop、甚至是没有 API 的遗留企业软件。真正的价值在那里,而不是在重命名 15 个文件上。
跨设备操控:Codex + iPhone Mirroring 打通手机
这可能是整个视频中最具前瞻性的部分。
博主把 Codex 和 Apple 的 iPhone Mirroring 功能结合起来,让 GPT 通过 Mac 间接操控 iPhone 上的应用。精度比原生桌面操作略低(毕竟完全依赖视觉点击和屏幕解读),但效果出奇地好。
适用场景包括:
- 移动应用 UX 测试
- 社交媒体自动发布
- 消息管理和邮件发送
- 移动游戏测试
- iOS UI 测试
当 AI 能跨浏览器、桌面、手机无缝操作时,"应用"这个概念本身就被重新定义了。用户不再需要学习每个 App 的界面,只需要告诉 AI 你想做什么。
但"精度略低"这四个字背后藏着巨大的工程挑战:移动端的触控精度要求远高于桌面端,一个像素的偏差就可能点错按钮。而且这种方案完全依赖 Apple 的 iPhone Mirroring 功能,等于把核心能力建立在别人的平台特性上——Apple 随时可以改变政策或限制第三方访问。
Codex vs Claude Code:该不该切换?
博主强烈推荐从其他工具切换到 Codex,认为它的用量限制优于 Claude Code 等竞品。他也声明了没有收 OpenAI 的赞助。
客观来说,Codex 确实在做一件其他竞品没做到的事:把编码、测试、浏览器操控、桌面控制整合进一个统一平台。Claude Code 在纯编码能力上可能不输,但在"全栈自动化"这个维度上,Codex 目前确实领先一个身位。
不过,"单一平台完成所有任务"这个愿景本身就是一把双刃剑——它意味着你把所有鸡蛋放进了 OpenAI 的篮子里。当平台出问题、涨价或改变策略时,你的整个工作流都会被绑架。
写在最后
我们正在见证的不只是工具升级,而是软件开发范式的一次根本性变化。AI 从"帮你写代码"进化到了"帮你写代码、测代码、修 bug、操作浏览器、整理文件、甚至操控手机"。
但在兴奋之余,有一个问题值得每个开发者认真想想:当我们把构建和验证都交给同一个 AI 时,谁来验证 AI 本身?
AI Agent 的终极承诺不是让程序员失业,而是让每个人都成为程序员。在那一天真正到来之前,把 AI 当作强力助手而不是无脑替代,可能才是最明智的姿态。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。