Codex vs Kiro vs Coder实测对比:2025年AI编程工具怎么选
实测对比Codex、Kiro和Coder三款AI编程工具,国产Coder表现最优
本文通过让OpenAI Codex、亚马逊Kiro和国产Coder用相同关键词生成HTML小游戏的实测对比,发现Coder生成的射击游戏在完整度、可玩性和逻辑严密性上全面胜出;Codex视觉效果好但存在方向键Bug;Kiro粒子特效炫酷但缺乏游戏性。结论是国产AI工具不应被偏见否定,选择工具应以实际效果为准。
2025年AI编程工具的竞争已经白热化。Cursor和Augment虽然口碑不错,但价格和门槛让不少开发者望而却步。目前真正主流且值得关注的方案,集中在OpenAI Codex、亚马逊Kiro和国产Coder这三款AI编程工具上。本文通过一个统一的实战测试——用相同的关键词让三款AI各自生成一个HTML小游戏——来直观对比它们在代码生成质量和实际可用性上的真实表现。
AI编程工具的技术底座:当前这一代AI编程工具的核心技术基础,是大型语言模型(LLM)与代码专项训练的深度结合。这类工具通常在海量开源代码库(如GitHub上数十亿行代码)上进行预训练,再通过RLHF(人类反馈强化学习,Reinforcement Learning from Human Feedback)对代码生成质量进行对齐优化。不同工具之间的能力差异,本质上来自底层模型参数规模、上下文窗口大小、系统提示词工程设计,以及与IDE集成深度的综合叠加效果。这也解释了为什么使用"官方原版模型"是公平测试的前提——任何中间层的修改都会引入额外变量,干扰对模型本身能力的判断。
测试方案与环境搭建
为了保证对比测试的公平性,我们采用了同一套关键词,分别发送给三款AI编程工具,让它们各自随机生成一个HTML小游戏。核心原则是:使用官方原版模型,不借助反代或第三方API,避免"掺水"干扰测试结果。
OpenAI Codex:通过Warp终端直接调用官方GPT 5.3 Codex模型,cd到项目文件夹后用快捷键唤起对话窗口,粘贴关键词即可开始生成代码。
亚马逊Kiro:使用Claude Sonnet 4.5模型,直接在Kiro IDE界面中发送相同关键词。值得注意的是,Kiro是亚马逊基于Claude系列模型构建的IDE产品,其底层推理能力来自Anthropic,但产品层的交互设计、上下文管理和工具调用逻辑由亚马逊团队独立开发,因此与直接使用Claude API存在体验差异。
Coder:通过终端方式,在Windows的Linux子系统(WSL)中启动Coder Client,进入Coder Ultimate测试项目后发送关键词。WSL(Windows Subsystem for Linux)是微软在Windows 10/11中内置的Linux兼容层,允许开发者在Windows环境下直接运行Linux命令行工具和应用程序,无需虚拟机或双系统。WSL 2采用真实的Linux内核,I/O性能和系统调用兼容性大幅提升,已成为Windows平台开发者进行后端开发、AI工具调用的主流环境选择——这也是为什么有一定开发经验的用户更容易上手这套工作流。
三款工具几乎同时开始工作,几分钟后各自交出了答卷。
三款AI生成结果对比
Codex生成结果:迷红风车生存冲击
Codex生成了一款名为"迷红风车生存冲击"的游戏。玩家需要用方向键控制角色躲避不断飘来的小方块。整体视觉效果不错,有一定的可玩性,但存在一个明显的Bug——按"上"方向键时角色无法移动,只能左右移动。这种功能性缺陷在实际开发项目中是比较致命的。
从代码质量角度看,Codex能够快速搭建出一个完整的游戏框架,视觉表现力也不弱,但在细节打磨和逻辑完整性上仍有提升空间。这类方向键冲突Bug在HTML5游戏开发中并不罕见——浏览器默认会拦截方向键的滚动事件,需要在事件监听中显式调用preventDefault()来阻止默认行为。Codex在这一细节上的遗漏,暴露出模型在处理"浏览器环境特殊性"时的知识盲区。
Kiro生成结果:粒子重力艺术游戏
Kiro生成了一款"粒子重力艺术游戏",提供了重力模式、吸引模式和排斥模式三种玩法。粒子特效本身做得相当炫酷——在吸引模式下粒子跟随鼠标移动,排斥模式下粒子会远离鼠标位置。
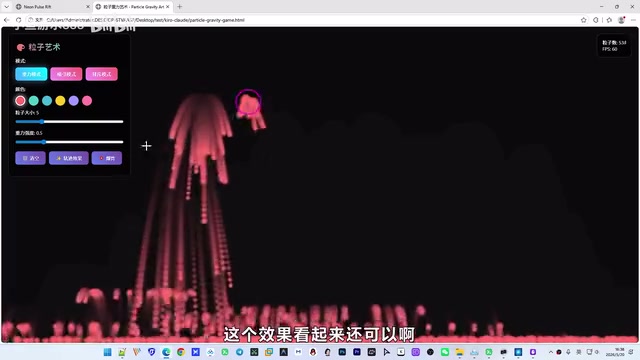
然而问题也很突出:UI设计非常粗糙,左侧布局不合理,而且最关键的是——这更像一个视觉演示Demo,而不是一个真正的"游戏"。没有得分机制、没有胜负判定、没有难度递进,可玩性几乎为零。
从游戏设计理论的角度来看,评估一个游戏是否完整,通常参考**核心游戏循环(Core Game Loop)**理论:玩家行为 → 即时反馈 → 奖励机制 → 难度递进 → 再次行为。这个循环的每一个环节都不可或缺——缺少奖励机制,玩家没有持续游玩的动力;缺少难度递进,体验会迅速变得单调。Kiro生成的粒子演示只完成了"玩家行为→即时反馈"这前两步,后续循环完全缺失,这正是它"好看不好玩"的根本原因。这反映出Kiro在理解"游戏"这个需求时,偏向了技术展示而忽略了交互设计和游戏性。
Coder生成结果:三角追击者射击游戏
Coder生成了一款名为"三角追击者"的射击游戏,表现明显优于前两者。玩家可以射击飘来的敌人方块,绿色方块吃掉后加分,界面左上角有计分系统,下方有血条显示,难度会随时间递进。
从游戏设计的完整度来看,Coder生成的作品具备了一个完整游戏应有的核心要素:操作反馈、得分机制、难度曲线、生命系统。对照核心游戏循环理论,"三角追击者"完整实现了从玩家操作到奖励反馈再到难度递进的全链路设计——这正是它在可玩性上碾压另外两款作品的关键所在。这说明Coder的极致模型在理解复杂需求和生成结构化代码方面,确实有过人之处。
综合评价与选择建议
通过这次AI编程工具实测对比,三款工具的排名非常清晰:
| 排名 | 工具 | 优势 | 不足 |
|---|---|---|---|
| 🥇 | Coder | 游戏完整度高,可玩性强,逻辑严密 | 需要终端操作,上手门槛较高 |
| 🥈 | Codex | 视觉效果好,框架搭建快 | 存在功能Bug,细节不够完善 |
| 🥉 | Kiro | 粒子特效炫酷 | UI粗糙,缺乏游戏可玩性 |
国产AI编程工具的真实水平
很多开发者对国产AI工具存在先入为主的偏见,认为"国产全是坑"。但从这次实测结果来看,Coder的极致模型完全可以和Augment打平手,甚至在某些场景下比付费的Cursor还要好用。这一结果并非偶然——近两年国内AI基础模型的训练数据规模、代码语料质量和RLHF对齐技术均已大幅追赶国际水平,部分垂直场景(如中文注释生成、国内主流框架适配)甚至形成了差异化优势。选择AI编程工具不应该看出身,而应该看实际效果。
不同场景下的工具选择策略
- 有开发经验、想做真实项目的用户:推荐Coder终端模式,配合WSL使用,代码生成能力上限最高
- 日常开发、追求效率的用户:Codex是不错的选择,生态成熟,上手快
- 业余用户、偶尔写点小工具:豆包的编程模式完全免费,足以应对简单的代码生成任务
写在最后
在AI编程工具的选择上,最重要的一条原则是:不要靠想象,要靠实践。每个人的项目类型、编程习惯、技术栈都不同,只有真正动手做几个项目,才能找到最适合自己的AI编程工具。2025年的AI编程领域变化极快,今天的排名可能三个月后就会被刷新——事实上,主流模型的迭代周期已经压缩到数月以内,今天的测试结论在下一个大版本发布后可能就需要重新验证。保持开放心态、持续尝试新工具,才是最优策略。
核心要点
- 通过相同关键词生成游戏的实测对比,Coder极致模型在代码完整度和可玩性上全面胜出
- Codex视觉效果不错但存在功能Bug,Kiro特效炫酷但缺乏实际可玩性
- 国产AI工具不应被偏见否定,Coder极致模型可与Augment媲美甚至优于付费Cursor
- 有开发经验者推荐Coder终端模式(配合WSL),业余用户可选择豆包免费编程模式
- 选择AI编程工具应以实际项目体验为准,不要凭想象判断;模型迭代极快,结论需持续更新
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。