Codex vs Claude Code:账单差10倍的真相与选型指南
同样一道编程任务,Codex收费15美元,Claude Code收费155美元——账单差了整整10倍。但翻开官方价目表,GPT-5.5输出每百万Token 30美元,OPUS 4反而只要25美元。单价上Codex一点不便宜,甚至还略贵。那这10倍差价到底去哪了?
一位深耕AI编程两年、两款工具天天换着用的B站UP主,把这笔账彻底算透了。核心结论是:差价不在单价,而在用量。
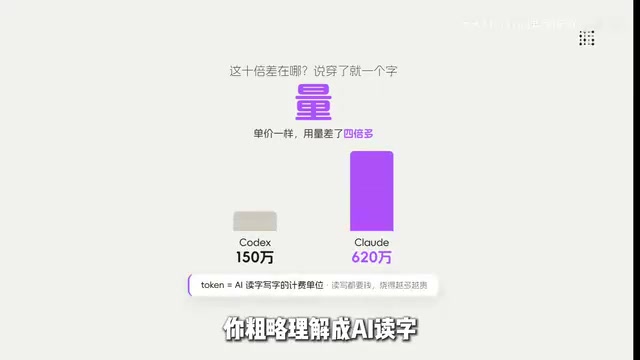
同样的任务,Token消耗差4倍
根据实测数据,同一类复杂编程任务,Codex大约消耗150万Token,而Claude Code要烧掉620万Token。
这里有必要解释一下Token的计费机制。Token是大语言模型处理文本的最小单位,但它并不等同于一个汉字或一个英文单词。对于英文,一个Token大约是0.75个单词(即4个字符左右);对于中文,一个汉字通常被编码为1.5到2个Token。更关键的是,模型的计费分为"输入Token"和"输出Token"两部分,输出Token的单价通常是输入的3-5倍,因为生成文本比读取文本需要更多的计算资源。以GPT-5.5为例,输出每百万Token 30美元意味着模型每多"说"一个字,开发者的账单就多跳一格。这也解释了为什么后面提到的Claude Code"边干边汇报"的风格会导致成本飙升——输出端的冗余直接命中了最贵的计费区间。
那为什么Claude Code要多烧4倍Token?原因归结为三件事:
1. 输出冗长:边干活边汇报
GPT-5.5写代码的风格是"闷头干活"——直接甩你一段能跑的代码。而OPUS 4写之前先解释、反问你需求,写完还跟你讲为什么这么写。一个闷头干活,一个边干边汇报,后者的输出Token自然翻倍。
2. 上下文管理粗放:不摘要、不清理
Claude Code每读一个文件、每跑一条命令,都把整段原文塞进上下文,不做摘要,也不主动清理。如果中途读了一份上万行的日志,这份日志会在后面每一轮对话里持续占位、持续计费。包袱越背越重,Token消耗滚雪球式增长。
要理解这个问题的严重性,需要了解"上下文窗口"(Context Window)的工作原理。上下文窗口是指模型单次对话能"记住"的最大Token数量,当前主流模型已从早期的4K、8K扩展到128K甚至200K Token。但窗口越大并不意味着应该塞满——每一轮对话中,所有历史消息都会被重新发送给模型,这意味着上下文中的每一段文字在每一轮都会被重复计费。Codex采用的策略类似于"滑动窗口+摘要压缩",会将早期对话内容压缩为简短摘要,从而控制每轮实际发送的Token量。而Claude Code的做法更接近"全量保留",虽然保证了信息完整性,但也导致了Token消耗的雪球效应。这种差异本质上是信息保真度与成本效率之间的工程权衡。
3. 反复验证:宁可多查也不放过
遇到同一个bug,Claude Code会主动多翻几个相关文件、查好几遍、反复跟自己确认没搞错。这些"再查一遍"的动作,全都在烧Token。

多花的钱到底买到了什么?
看到这里,你可能觉得答案很明显——选Codex,便宜还干净利落。但把上面三件事倒过来看,味道完全变了。
Claude Code多烧的那4倍Token,买的是两个字:彻底。
正因为它读得全、查得细、想得多,在对比测试中,Claude Code抓到过一个Codex漏掉的隐藏bug——叫静态条件竞争(race condition),平时根本测不出来,上线才冒头,属于最难缠的那类bug。
条件竞争是并发编程中最经典也最棘手的bug类型之一。当两个或多个线程/进程同时访问共享资源,且最终结果取决于它们执行的先后顺序时,就会产生竞争条件。之所以说它"平时测不出来,上线才冒头",是因为在开发环境中,代码通常在单线程或低并发下运行,竞争条件的触发概率极低;但在生产环境的高并发场景下,微妙的时序差异会让这类bug频繁爆发,轻则数据错乱,重则系统崩溃。历史上著名的Therac-25放射治疗机事故就与竞争条件有关,导致了多名患者因辐射过量而死亡。这类bug之所以难以被常规代码审查发现,是因为它不存在于任何一行代码中,而是隐藏在多段代码的交互时序里。Claude Code能捕获到这类问题,正是因为它会交叉验证多个相关文件之间的逻辑关系,而非只看单个函数的正确性。
还有一组盲评实验:把两边写的代码盖住名字让人比较,67%的人觉得Claude Code写的代码更干净,觉得Codex更干净的只有25%。
这里的盲评实验(Blind Evaluation)是软件工程和AI领域常用的评估方法,其核心原则是消除品牌偏见。具体做法是将两个模型生成的代码去除所有标识信息,随机编号后交给评审者打分,评审维度通常包括代码可读性、命名规范、错误处理完整性、架构合理性等。67%对25%的偏好差距在统计学上具有显著意义,说明Claude Code在代码质量维度确实存在可感知的优势。但值得注意的是,"代码更干净"和"更适合生产使用"之间还有距离——干净的代码如果开发效率低3倍,在快速迭代的业务场景中未必是最优选择。
但有趣的是,在500多人的开发者调查中,65%的人日常主力照样用Codex。
听着矛盾?其实一点都不矛盾。省Token和写好代码,压根不是两回事,而是同一个取舍的两面:
- Codex把钱省在少说废话
- Claude Code把钱花在多查一遍
没有谁占便宜,是各花各的钱、各办各的事。
按场景算账:Codex与Claude Code实用选型框架
所以核心问题不是"谁更好",而是按你的场景算账。
适合选Codex的场景
- 日常迭代:功能开发、原型验证、快速出活
- 预算敏感:个人开发者、小团队、学习练手
- 任务明确:需求清晰,不需要AI反复确认
适合选Claude Code的场景
- 复杂工程:生产级代码、多模块联动
- 容错要求高:金融、医疗等对bug零容忍的领域
- 疑难排查:需要深度分析、交叉验证的调试任务

省Token实战技巧:账单降两到四成的方法
除了选对工具,日常编码习惯也能显著影响Token消耗。以下是一套经过验证的"省Token三件套":
- 精简上下文:不要一次性把整个项目丢给AI,只给它需要的文件和片段。这一点在使用Claude Code时尤为重要——前面提到它不会主动做摘要压缩,所以你喂进去多少,它就会一直背着多少。
- 明确指令:需求写清楚,减少AI反问和试探的轮次。一条模糊的指令可能触发3-5轮澄清对话,而一条结构化的指令(包含输入格式、输出要求、边界条件)往往一轮就能拿到满意结果。
- 及时清理对话:长对话及时开新会话,避免历史消息持续占用Token。根据上下文窗口的计费机制,一段20轮的对话到后期,每一轮的Token消耗可能是第一轮的5-10倍。
这些看似简单的习惯,累积下来能让月度AI编程账单下降20%-40%。
从"听推荐"到"会算账":建立自己的AI工具评估能力

这套分析最有价值的,不是告诉你选A还是选B,而是提供了一套可复用的判断框架。
这一点在当前AI编程工具快速迭代的行业背景下尤为重要。2024-2025年是AI编程工具爆发式增长的时期,除了Codex(OpenAI)和Claude Code(Anthropic)之外,市场上还有GitHub Copilot、Cursor、Windsurf、Amazon CodeWhisperer等多款产品。这些工具大致分为两类:一类是"补全型",嵌入IDE中提供实时代码建议;另一类是"代理型"(Agentic),能够自主执行多步骤编程任务,包括读取文件、运行测试、修复错误等。Codex和Claude Code都属于后者,这也是它们Token消耗远高于传统补全工具的原因——代理型工具每完成一个任务可能需要数十轮内部推理循环。据Gartner预测,到2028年,75%的企业软件工程师将使用AI编程助手,而2023年初这一比例不到10%。在这个快速膨胀的市场中,理解成本结构而非仅看功能演示,正在成为开发者和技术管理者的核心能力。
掌握这套思路后,你能获得三个能力:
- 任何编程任务都能快速匹配工具:日常活该用谁、关键活该上谁,不再凭感觉
- 过滤噪音的能力:以后看到"某工具碾压某工具"的评测,能立刻判断对方是真把账算明白了,还是只看了单价拍脑袋
- 从被动到主动:管理AI编程工具的方式,从"听别人推荐"变成"我自己会算这笔账"
正如那句总结的心法:
别问哪个更好,问你这活该花谁的钱。
把这句话记住,AI编程工具对你就从一笔糊涂账,变成一笔算得清的账。
写在最后
两款工具各有所长,没有全能王。Codex胜在效率和成本控制,Claude Code胜在深度和代码质量。最聪明的做法不是二选一,而是分场景使用——日常迭代用Codex控制成本,关键模块用Claude Code确保质量。
这套方法论不仅适用于当前的Codex和Claude Code,未来任何新的AI编程工具出现时,你都可以用同样的框架去评估:看单价、算用量、对场景、比产出。工具会迭代,但算账的能力是通用的。
相关推荐

AITS实测:API+Web+App自动化测试一站式搞定
深度实测AITS智能测试平台,覆盖API接口自动化、Web自动化、App真机云测及性能压测全链路。详解智能驾驶舱、断言规则复用、脚本自动生成等核心功能,帮助测试团队告别重复劳动,提升测试效率。

Codex vs Claude Code vs Cursor:AI编程工具怎么选
深度对比Codex、Claude Code和Cursor三大AI编程工具的价格、稳定性与能力差异。Codex擅长前端UI开发,Claude Code后端逻辑更强,Cursor老牌稳定。帮你根据开发方向选出最适合的AI编程助手。
Hermes Jarvis深度解析:语音驱动的AI全能助手
深度解析Hermes Jarvis语音AI助手的核心功能与五层架构设计。从语音开发应用、系统级操控到多模型集成,全面了解这款将科幻变为现实的智能体助手的能力、局限与未来潜力。