Codex安全使用指南:权限管理的五个关键原则

OpenAI Codex安全使用需遵循权限最小化原则,按任务匹配权限等级。
本文系统阐述了OpenAI Codex的安全使用方法。Codex已从代码建议者升级为能直接执行命令的工具,因此需通过工作区、权限模式(默认/自动审查/完全访问)和审批机制三大支柱构建安全边界。文章将操作风险分为五级,提出"先读不改、改前列计划、改动要收敛、改完要验证、交代风险"五个口诀,强调权限应与任务匹配而非一味放大。
OpenAI Codex 安全使用指南:权限边界与风险管控
OpenAI Codex 不是普通的聊天工具——它能读文件、改文件、跑命令,甚至在你授权后操作浏览器或电脑。与早期仅能生成代码片段的语言模型不同,现代 Codex 采用了「工具调用」(Tool Use)架构,能够通过沙箱环境直接执行 shell 命令、读写文件系统、调用浏览器 API。这种从「建议者」到「执行者」的角色转变,意味着一条 rm 命令就可能让你半年的资料归零。Codex 越强大,权限边界就越需要先讲清楚。
本文的核心观点不是说「完全访问权限」永远不能用,而是:在你刚开始用、任务范围还没想清楚、也不知道怎么回滚的时候,不要上来就把边界放开。
Codex安全边界的三大支柱
Codex 的安全边界不是来自「相信它永远正确」,而是来自三件事:工作区、权限模式、审批。
- 工作区决定它主要看哪里
- 权限模式决定它在这个范围内能自主做什么
- 审批决定它什么时候需要停下来问你
三者配合,才能构建一个真正可控的使用环境。这三个维度共同构成了「人机协作循环」(Human-in-the-Loop)的完整闭环——缺少任何一环,都会让 AI 的执行行为变得不可预期。
工作区设置:先圈定战场
每次开始任务前,先确认打开的是不是当前任务真正需要的文件夹。**不要一上来就打开整个桌面、下载目录,或者一个塞了几十个项目的大目录。**目录越大,上下文越杂,误操作风险越高,Token 也更容易浪费。
最简单的做法是先发一句话给它,让它说出现在能看到哪些文件,暂时不要修改。

你要让 Codex 处理的是这个项目,不是你的整个电脑。这一步看似简单,却是防止误操作最有效的第一道防线。工作区的边界划定,本质上是在实践「最小权限原则」(Principle of Least Privilege)——只给 AI 访问完成当前任务所必需的最小资源范围。
权限模式详解:理解三个档位
如果你用的是 Codex APP,权限选择里最常见的是三个选项:
| 权限模式 | 适用场景 | 风险等级 |
|---|---|---|
| 默认权限 | 大多数日常任务 | 低 |
| 自动审查 | 熟悉流程后减少手动确认 | 中 |
| 完全访问权限 | 非常确定任务需要且知道怎么回滚 | 高 |
这三种模式背后,对应的是「人机协作循环」不同深度的介入方式——类似机器人流程自动化(RPA)领域中「有人值守」与「无人值守」模式的区别:
默认权限适合大多数日常任务。Codex 可以在当前工作区里读文件、改文件、跑一些常规本地命令,但如果它要联网、写到工作区外或者做更敏感的动作,就会停下来问你。每个敏感动作前强制暂停,是这一模式的核心安全机制。
自动审查不是把权限边界直接放大,它更像是把一部分审批交给自动 reviewer 判断,引入了基于规则或模型的自动审批层,减少人工干预频次。适合比较熟悉流程、希望减少手动确认的人。刚开始用的时候不建议一上来就依赖它。
完全访问权限则将整个执行链路交给 AI 自主决策,边界放得很开。这个选项不要当默认选择,尤其不要在一个大目录里为了一个小任务直接打开它。

简单记忆:默认权限是新手模式,自动审查是日常模式,完全访问权限才是高风险模式。
审批机制:它是刹车,不是麻烦
审批的作用是让 Codex 在做需要额外确认的动作前先停一下——比如访问网络、写到工作区外,或者执行更敏感的命令。
看到审批请求时,不要机械点同意,先看三件事:
- 它要运行什么命令?
- 这个命令会影响哪里?
- 这个权限是不是当前任务真的需要?
如果看不懂,就直接问它解释这个动作。它解释不清楚,你就不要急着放行。审批机制的本质,是在 AI 自主执行与人工监督之间设置的「检查点」(Checkpoint),每一次确认都是你对执行链路的一次主动介入。
风险分级管理:从只读到高危
实际使用时,可以把操作风险分成几档来管理:
最低风险:只读操作
解释项目、找功能位置、分析报错、做 review——这类任务一般可以先让它看,不让它改。
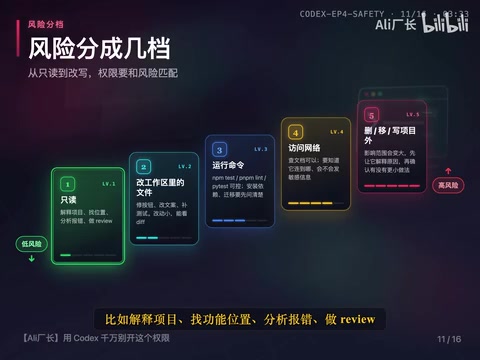
中等风险:修改当前工作区
修一个按钮状态、改一段文案、补一个测试。重点是改动范围要小,改完要能看 diff。
较高风险:运行命令
npm test、pnpm link、pytest 这类检查命令通常比较可控。但安装依赖、迁移数据库、启动外部服务就要先问清楚目的和影响。
需要额外确认:网络访问
查官方文档、下载依赖、调用外部 API 都可能用到网络。网络不是不能开,但要知道它准备连到哪里、为什么要连、会不会发送敏感信息。一旦 AI 被授权网络访问,其行为的可观测性会显著下降,这也是为什么网络权限需要单独确认的原因。
最高风险:删除与敏感操作
删除文件、移动大量文件、写项目外目录、处理带有敏感信息的内容。这也是为什么完全访问权限不能随手开——一旦边界放得太大,删除、覆盖、移动这类动作的影响范围也会变大。遇到这类动作,先让它解释原因,再确认有没有更小的做法。
安全使用Codex的五个口诀
安全使用 Codex 可以养成五个习惯,对着 Codex 说就行:
- 先读不改 —— 先让它了解项目,不急着动手
- 改前列计划 —— 修改前先输出修改方案
- 改动要收敛 —— 控制每次改动的范围
- 改完要验证 —— 检查 diff,确认结果
- 最后交代风险 —— 让它说明可能的副作用

这五句话不是为了限制 Codex 的能力,而是让它每一步都有依据、有边界、有验证。这套流程在工程实践中对应的是「防御性编程」(Defensive Programming)思想在人机协作场景下的延伸——不假设 AI 永远正确,而是通过结构化流程主动降低出错概率。
敏感信息与大任务的处理策略
敏感信息不要随便传。 API Key、密码、私钥、生产数据库连接、客户数据——这些都不要直接发给 Codex。当敏感信息被传入 AI 上下文后,存在多个潜在风险面:日志留存、模型训练数据混入,以及若 AI 被授权网络访问时可能的外发行为。业界通行做法是使用环境变量隔离(.env 文件配合 .gitignore)以及密钥管理服务(如 AWS Secrets Manager、HashiCorp Vault),这些实践同样适用于 AI 工具的使用场景。项目里如果有环境变量文件(如 .env),也要知道里面可能有敏感信息。能用假数据就用假数据,能只描述问题就先描述问题。
如果任务真的比较大——比如重构一块核心逻辑、改支付流程、迁移数据库——最好先开分支。Git 的分支机制本质上是一种低成本的「检查点」系统:在 AI 执行大规模修改前创建新分支,意味着即使操作出错,也可以通过 git reset 或 git revert 将代码库恢复到任意历史状态,而不会影响主分支。不会 Git 也没关系,至少先备份关键文件,或者先让 Codex 做只读分析和修改计划,不要一上来就全自动执行。
总结:权限与任务匹配才是关键
你只需要记住一个判断原则:权限不是开得越大越好,而是要和任务匹配。
- 查问题 → 用只读
- 小修改 → 用默认权限
- 要连网、装依赖、涉及项目外内容 → 先确认目的和影响
- 完全访问权限 → 不要当日常默认项
你敢把任务交给 Codex,不是因为它永远不会犯错,而是因为你知道它在哪里工作、能做什么、什么时候会停下来问你。边界清楚了,完全访问权限也就不会被随手打开。
核心要点
- Codex的安全边界由工作区、权限模式和审批三大支柱构成,缺一不可
- 权限分为默认、自动审查和完全访问三个档位,对应「人机协作循环」不同深度的介入方式,新手应从默认权限开始
- 操作风险可分为只读、修改工作区、运行命令、网络访问和删除/敏感操作五个等级,逐级管控
- 安全使用的五个口诀:先读不改、改前列计划、改动要收敛、改完要验证、最后交代风险
- 敏感信息(API Key、密码、私钥等)不要直接传给Codex,应使用环境变量隔离;大任务应先开Git分支或备份再执行
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。