Codex缓存清理指南:.codex文件夹瘦身实战教程
系统介绍清理OpenAI Codex本地.codex文件夹的方法,包括删除对话和瘦身日志。
OpenAI Codex在使用过程中会在用户目录下的.codex文件夹中积累大量会话数据和日志,且官方未提供清理功能。本文介绍两种核心清理方法:一是使用社区Python工具通过Session ID精准删除指定对话(支持干运行预览),二是关闭Codex后直接删除logs.sqlite日志文件并重启自动重建,可将日志从17MB缩减至41KB。同时建议每一两个月做一次彻底归档。
随着 OpenAI Codex 的持续使用,用户根目录下的 .codex 文件夹会不断膨胀。官方至今没有提供删除对话的功能,导致这个文件夹越来越臃肿,日志文件甚至可能大到超出想象。本文将系统介绍如何利用社区工具和手动操作,对 .codex 文件夹进行彻底清理,涵盖对话删除和日志瘦身两大核心环节。
OpenAI Codex 是 OpenAI 推出的 AI 编程代理,集成在 VS Code 等开发环境中,能够根据自然语言指令自动完成代码编写、调试和重构等任务。与传统的代码补全工具不同,Codex 以"代理"模式运行——它会在独立的沙箱环境中执行多步操作,每次交互都会产生一个完整的会话(Session),包含用户指令、AI 推理过程、代码变更记录和执行日志。这些数据全部存储在用户主目录下的 .codex 文件夹中。该文件夹采用 SQLite 数据库和文件系统混合存储的架构,其中 rollout 记录了每次代理执行的完整轨迹,session index 则维护着所有会话的索引信息。由于 Codex 的每次操作都涉及大量的中间状态记录,这种设计虽然便于本地调试和回溯,但也意味着数据增长速度远超普通应用的缓存。
清理前的准备工作:备份不可省略
在进行任何清理操作之前,务必先备份你的 .codex 文件夹。数据操作存在风险,一旦出现问题,你可以将备份文件夹复制回原位,无缝恢复到操作前的状态。
具体准备步骤如下:
- 下载清理工具:前往 GitHub 下载社区成员 EA 制作的 Codex 对话删除工具(视频作者 DP 在 EA 授权基础上做了优化,建议使用 1.0 版本)。
- 验证 Python 环境:在命令行输入
python --version或python3 --version,确认本地已安装 Python(推荐 3.9+)。如果没有安装,可以借助 AI 引导完成安装,非常简单。 - 备份文件夹:将用户目录下的
.codex文件夹完整复制到其他位置,标注日期以便管理。
查询并删除指定Codex对话
查询所有本地对话
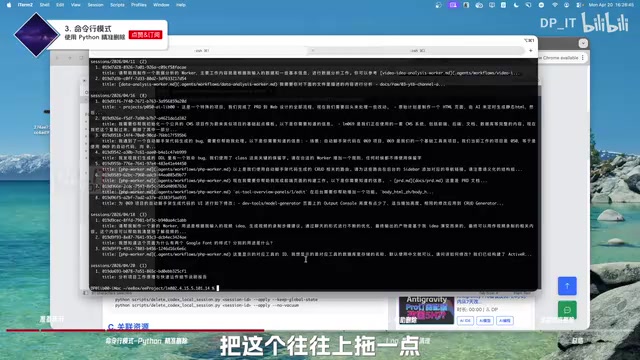
打开命令行工具,准备两个终端窗口。首先进入下载好的工具项目文件夹,然后执行查询命令。工具会列出你本地所有的 Codex 对话,按时间分组显示,每条对话包含 ID、标题 和 日期 等信息。
如果某些对话的标题显示为 worker 名称等不易辨认的内容,可以在命令后加上 --format title 等参数来完整显示标题信息。
删除预览与正式删除
确定要删除的对话后,复制其 Session ID,分两步操作:
- 删除预览(Dry Run):先执行预览命令,工具会生成一份报告,告诉你将要删除哪些文件、涉及哪些 SQLite 数据库记录、关联的 rollout 和 session index 等,但不会真正执行删除。
- 正式删除:确认预览结果无误后,执行删除命令。工具会输出 "Done" 并展示删除报告,包括具体删除了哪些内容以及对 SQLite 数据库的重置操作。
Dry Run(干运行/预演模式)是软件工程和系统运维中一种重要的安全实践。它的核心思想是:在真正执行具有破坏性或不可逆的操作之前,先模拟整个执行过程,输出将要发生的变更,但不实际修改任何数据。这种模式在许多知名工具中都有应用,例如 rsync 的 --dry-run 参数、Terraform 的 plan 命令、以及 npm 的 --dry-run 发布预览。社区工具采用这种两步式操作设计(先预览后执行),体现了防御性编程的理念,让用户在确认影响范围后再做最终决策,大幅降低了误操作的风险。
如果需要批量删除多条对话,只需重复上述流程,替换不同的 Session ID 即可。
替代方案:通过 Codex Scales 对话式删除
如果你觉得手动操作命令行太麻烦,还有一种更简便的方式——直接通过 Codex 的 Scales 功能,用自然语言告诉它"把某日期之前的对话全部删除"。工具会自动调用 Python 脚本完成操作。
Scales 是 Codex 提供的一种可扩展能力机制,允许用户通过配置文件定义自定义指令和工具链,让 AI 代理能够调用外部脚本或工具完成特定任务。其工作原理类似于 ChatGPT 的 Function Calling 或 MCP(Model Context Protocol)——用户用自然语言描述意图,AI 解析后将其映射为具体的工具调用。在对话删除场景中,Scales 会将"删除某日期之前的对话"这一自然语言指令,转化为对 Python 清理脚本的参数化调用。这种方式的优势在于降低了使用门槛,但由于 AI 在理解和转化指令时存在解释偏差的可能性(例如日期边界的判定、对话范围的理解),其执行结果可能与用户预期存在差异。
不过需要注意,这种方式由 AI 自主执行,存在一定的不确定性。相比之下,手动使用 Python 命令的方式指定性更强,能做到 100% 精准删除,因此更推荐在重要场景下使用命令行方式。
清理logs.sqlite日志文件:真正的体积大户
完成对话删除后,你可能会发现 .codex 文件夹的体积并没有显著缩小。这是因为真正占空间的是日志文件——logs.sqlite。
日志文件里存了什么?
用 SQLite 工具打开 logs.sqlite,可以看到它只有两张表。其中主要的一张表可能包含上万条记录(实测有 18 页、每页约 1000 条的规模),内容主要是 debug、info 等运行时状态日志。这些信息对日常使用没有实际价值,完全可以安全删除。
SQLite 是一种嵌入式关系型数据库引擎,无需独立的服务器进程,整个数据库就是一个单独的文件。它被广泛应用于浏览器(Chrome 的历史记录)、移动应用(iOS 和 Android 的系统数据库)以及桌面软件中。Codex 选择 SQLite 作为本地存储方案,是因为它零配置、高可靠、读写性能优秀,非常适合单用户场景下的结构化数据存储。但 SQLite 有一个特性需要注意:删除数据后,文件大小不会自动缩小,被删除的空间会被标记为"空闲页"供后续写入复用。如果需要真正回收磁盘空间,通常需要执行 VACUUM 命令来重建数据库文件。这也解释了为什么直接删除整个 logs.sqlite 文件比清空表内数据更为彻底。
软件系统的日志通常按严重程度分为多个级别,从低到高依次为:TRACE、DEBUG、INFO、WARN、ERROR、FATAL。其中 DEBUG 级别记录的是详细的程序运行状态信息,主要用于开发调试;INFO 级别记录的是正常运行的关键事件节点。Codex 的 logs.sqlite 中大量存储的正是 debug 和 info 级别的日志,这些日志在开发阶段对排查问题非常有价值,但对终端用户而言几乎没有实用意义。以实测数据为例,18000 多条日志记录累积到 17MB,平均每条记录约 1KB,这在日志系统中属于正常的单条大小(因为每条可能包含完整的请求/响应上下文、堆栈信息等)。在生产环境中,成熟的应用通常会配备日志轮转(Log Rotation)机制,按文件大小或时间周期自动归档旧日志并创建新文件。Codex 目前缺少这一机制,正是导致日志文件无限增长的根本原因。
具体清理步骤
操作步骤非常简单,但有一个关键前提:必须在 Codex 完全关闭的情况下进行,否则可能出现文件锁定等问题。当 SQLite 文件正在被某个进程使用时,会产生 WAL(Write-Ahead Logging)日志锁定机制,强行删除可能导致数据损坏或操作失败。
- 关闭 Codex 程序
- 直接删除
.codex文件夹中的logs.sqlite文件 - 重新打开 Codex(在 VSCode 中启动),程序会自动初始化并重建该文件
重建后的日志文件大小仅约 41KB,而操作前可能高达 1700 万字节(约 17MB)。实测数据显示,文件从 1700 万缩减到了 13 万,瘦身效果非常显著。
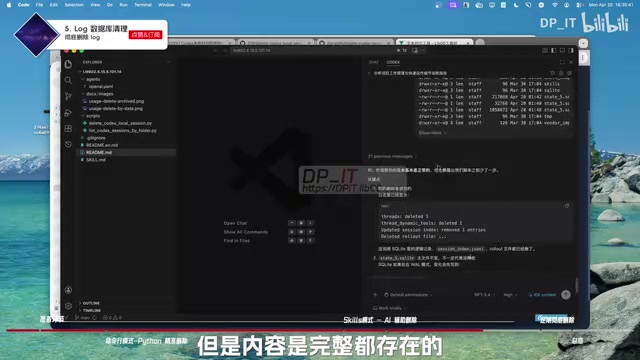
重建后第一次打开已有对话时可能会稍慢,但所有对话内容、消息记录都完整保留,第二次打开即恢复正常速度。
进阶建议:定期归档的最佳实践
在官方推出完整清理功能之前,这里分享一个值得借鉴的维护习惯:
每一到两个月,在项目完全结束、上下文不再需要的情况下,对
.codex文件夹做一次彻底归档。
具体做法:
- 将整个
.codex文件夹复制到归档目录,加上日期标号(如.codex_20250401) - 清空原
.codex文件夹,仅保留auth和config两个配置文件 - 重新打开 Codex,让程序自动完成初始化
这样就获得了一个全新的 Codex 运行环境,干净、高效。这种归档策略遵循的是"配置与数据分离"的设计原则。auth 文件存储了用户的 API 认证令牌和登录状态,config 文件则保存了用户的个性化设置(如模型偏好、代理行为参数等),这两者是 Codex 正常启动的最小必要条件。其余的会话数据、日志和缓存都属于可再生数据。这种方式类似于 Git 的 gc(垃圾回收)机制或 Docker 的 system prune 命令,通过周期性清理来防止工作环境的"熵增"。对于重度使用 AI 编程工具的开发者来说,养成这种环境卫生习惯尤为重要,因为 AI 代理产生的数据量远超传统开发工具。
总结:两步搞定Codex缓存清理
整个清理流程可以概括为两大核心操作:
- 对话清理:使用社区 Python 工具,通过 Session ID 精准删除指定对话及其关联数据
- 日志清理:关闭 Codex 后直接删除
logs.sqlite,重启程序自动重建
这套工具的设计理念值得称赞——足够简单,下载即用,一条命令完成操作;足够精准,指定对话即可完整删除所有关联数据。在官方尚未提供原生清理功能的当下,这无疑是每个 Codex 重度用户的必备技能。建议现在就检查一下自己的 .codex 文件夹大小,可能它已经膨胀到超出你的想象了。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。