Codex对话记录找回指南:API与订阅切换后的迁移方法

Codex切换订阅后对话"消失"是provider隔离机制所致,修改配置即可迁移找回。
OpenAI Codex在官方订阅与第三方API间切换后,对话看似消失,实为provider隔离机制将对话绑定到不同provider分区。迁移对话需关闭Codex后,同时修改sessions文件夹中JSON文件和state.db数据库中的model_provider字段。建议给第三方API设置固定provider名称以避免混乱,大量迁移可编写Python自动化脚本完成。
问题背景:切换订阅后对话为何消失了
使用 OpenAI Codex 的用户经常遇到一个令人困惑的问题:在官方订阅和第三方 API之间切换后,之前的聊天对话记录似乎凭空消失了。实际上对话并没有被删除,而是被隔离到了不同的 provider 分区中。
举个例子,假设你在第三方 API 模式下有对话 01 和 03,切换到官方订阅后只能看到对话 02,而 01 和 03 就"不见了"。反之亦然。这种现象的根源在于 Codex 的对话管理机制——对话是跟着 provider 走的。
理解了这个原理,我们就可以通过手动修改配置文件,将对话从一个 provider 迁移到另一个,从而找回"丢失"的对话记录。
核心原理:Provider决定对话归属
Provider隔离机制的技术背景
Provider 隔离是现代 AI 客户端应用中常见的多后端管理模式。当一个客户端需要同时支持多个 AI 服务来源时,开发者通常会引入"provider"抽象层,将认证信息、模型配置和会话数据绑定到特定的服务提供商标识符上。
这种设计模式在软件工程中称为"策略模式"(Strategy Pattern)——客户端通过统一接口与不同后端交互,每个 provider 就是一种可替换的"策略"。其好处是数据隔离清晰、切换安全,不同服务商的认证凭据和会话数据互不干扰;代价则是用户在不同 provider 之间切换时,会产生"数据消失"的困惑体验。Codex 的这一设计本质上是为了支持多服务商并存而做出的架构权衡,理解这一点是解决问题的关键前提。
配置文件结构解析
Codex 的配置主要由两个文件组成:auth.json 和 config.toml,它们位于用户目录下的 .codex 文件夹中。
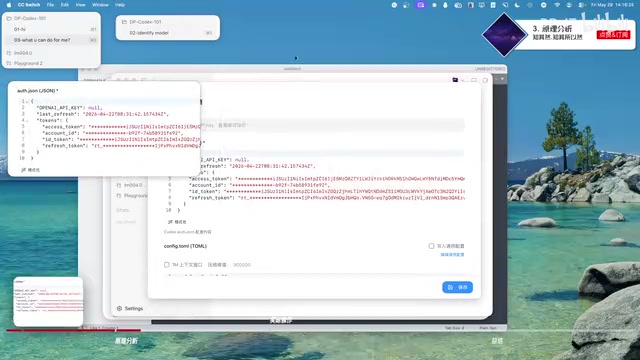
- auth.json:存储认证信息。官方订阅使用 access token / refresh token 机制,第三方 API 则使用 OpenAI API Key。这个文件格式固定,通常不需要手动编辑。
- config.toml:存储模型配置和项目设置。关键区别在于,使用第三方 API 时会多出一个
model_provider字段。
关于 access token / refresh token 机制:这是 OAuth 2.0 标准中的双令牌认证体系。access token 是短期有效的访问凭证(通常几小时到一天),用于实际的 API 请求鉴权;refresh token 是长期有效的刷新凭证,用于在 access token 过期后自动获取新的 access token,无需用户重新登录。这种机制在安全性和用户体验之间取得了平衡——即使 access token 泄露,攻击者的可用窗口也极为有限。
Provider的关键作用
在官方订阅的 config.toml 中,你只会看到模型名称、思考强度等基本设置。而接入第三方 API 后,配置中会出现 model_provider 字段,例如 dp-walking。
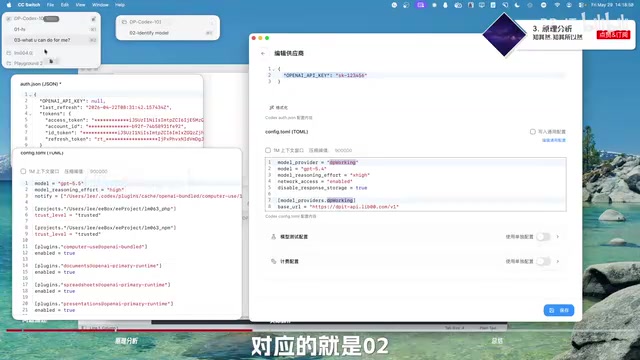
核心规则:对话列表与 provider 绑定。 官方订阅对应一个内部 provider(如 openai),第三方 API 对应你自定义的 provider 名称。只要 provider 不变,你看到的对话列表就不会变。
这也解释了为什么切换后对话会"消失"——它们只是属于另一个 provider,并没有被删除。一个实用的小技巧是:给自己的 provider 取一个固定的自定义名称(比如"小周-walking"),这样无论更换哪家第三方 API 服务商,只要保持 provider 名称一致,对话记录就能持续可见。
实操步骤:手动迁移对话记录
下面以"将官方订阅的对话 02 迁移到第三方 API"为例,演示完整的操作流程。
第一步:获取对话的 Session ID
在 Codex 中找到目标对话,右击选择「复制 Session ID」,将获得的 ID 保存到文本文件中备用。例如:02 - 7FC...(一串唯一标识符)。
Session ID 的设计原理:Session ID 通常是 UUID(通用唯一标识符)格式,由算法生成的128位随机数,以十六进制表示。UUID 的碰撞概率极低(约为 1/2¹²²),因此可以在不依赖中央服务器的情况下,在本地为每个会话生成全局唯一的标识符。这也是为什么 Codex 能够在离线状态下创建新对话——ID 生成不需要联网。
第二步:关闭 Codex 应用
必须先关闭 Codex,否则文件可能被锁定,无法正常编辑。这一步很容易被忽略,但至关重要。
这里涉及到操作系统的文件锁定机制。当应用程序正在读写某个文件时,操作系统会对该文件加锁,防止其他进程同时修改造成数据损坏。SQLite 数据库尤其如此——SQLite 使用文件级锁来保证事务的原子性和一致性(ACID 特性)。如果强行在应用运行时修改 state.db,轻则修改被覆盖,重则数据库文件损坏,导致所有会话记录丢失。
第三步:修改 Sessions 文件夹中的对话文件
打开用户目录下的 .codex 文件夹,找到 sessions 子文件夹。这里存放着所有对话的 JSON 文件,按日期组织目录结构。
通过之前复制的 Session ID 搜索对应文件(ID 就是文件名的一部分),用文本编辑器打开后,找到 model_provider 字段:
将 "model_provider": "openai"
改为 "model_provider": "dp-walking" // 替换为你的第三方 API provider 名称
保存文件。
第四步:修改 SQLite 数据库文件
在 .codex 文件夹中找到 state.db(SQLite 数据库文件),使用数据库管理工具打开。
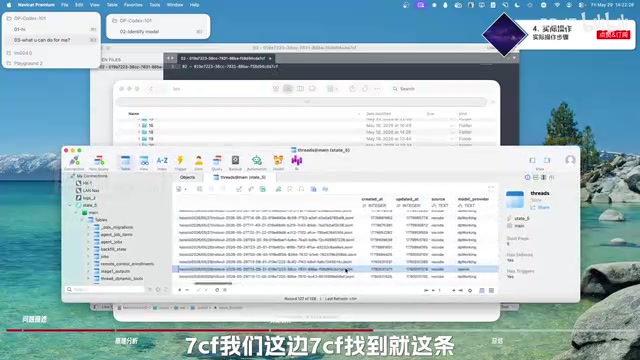
关于 SQLite 及推荐工具:SQLite 是一种轻量级的嵌入式关系型数据库,广泛用于桌面和移动应用的本地数据持久化。与需要独立服务进程的 PostgreSQL 或 MySQL 不同,SQLite 将整个数据库存储为单一文件(如 state.db),无需安装额外服务即可使用。Codex 使用 SQLite 存储会话元数据,配合 JSON 文件存储对话内容,是典型的"混合存储"架构——结构化索引数据放数据库,非结构化的对话内容放文件系统,兼顾查询效率和存储灵活性。推荐使用 DB Browser for SQLite(免费开源)或 TablePlus 等图形化工具进行编辑,操作更直观安全。
在数据库的表中找到最后一个表,通过 Session ID 定位到对应记录,将其中的 model_provider 字段同样从 openai 修改为目标 provider 名称。保存并关闭数据库。
注意:sessions 文件和数据库必须同时修改。 如果只改其中一个,可能会出现对话名称被覆盖等异常情况。实测发现,只修改数据库而不修改 session 文件时,系统可能会自动将 provider 纠正回原值。
这种"双写"设计在软件架构中称为冗余存储——同一份数据在两个地方都有记录,以提高读取性能或容错能力。Codex 可能用 SQLite 做快速索引查询,用 JSON 文件做完整数据存储。当两者不一致时,应用会以某一方为"权威来源"进行纠正,这就是为什么必须同步修改两处的原因。
第五步:切换到目标 API 并验证
使用 CCSwitch 等工具切换到第三方 API 配置(注意要切换到你实际使用的、包含正确认证信息的配置,而非演示用的 demo),然后启动 Codex。
此时你应该能在第三方 API 的对话列表中看到迁移过来的对话 02。同时切换回官方订阅验证,对话 02 应该已经从官方订阅的列表中消失,确认迁移成功。
进阶思路:用Codex编写自动化迁移工具
手动操作对于少量对话还可以接受,但如果你有大量对话需要迁移,逐个修改显然不现实。一个更高效的方案是让 Codex 帮你写一个 Python 自动化工具:
- 扫描阶段:程序读取 sessions 文件夹,列出所有已存在的 provider 及其对应的对话 ID
- 选择阶段:交互式询问用户要将对话移入哪个 provider
- 输入阶段:用户输入要迁移的对话 Session ID
- 执行阶段:程序自动完成 session 文件和数据库中
model_provider字段的同步修改
Python 实现的技术要点:Python 在文件系统操作和 SQLite 交互方面有成熟的标准库支持——os/pathlib 用于文件遍历,json 模块处理会话文件,sqlite3 模块直接操作数据库,无需安装任何第三方依赖。自动化工具的核心挑战在于保证操作原子性:session 文件和数据库的修改要么同时成功,要么同时回滚,避免出现数据不一致的中间状态。建议在执行修改前先备份原始文件,并使用 try/except 捕获异常,在出错时自动还原备份,确保迁移操作的安全性。
这个工具的核心逻辑就是自动化前面手动完成的两步修改操作。如果你感兴趣,可以将本文的原理总结成 prompt 交给 Codex,让它用 Python 实现这个迁移工具。
总结
Codex 在 API 和官方订阅之间切换导致的对话"丢失",本质上是 provider 隔离机制在起作用。理解了"对话跟着 provider 走"这个核心原理,迁移操作就变得清晰明了:找到对话文件和数据库记录,修改 model_provider 字段即可。
关键要点回顾:
- 两个文件(session JSON + state.db)必须同步修改
- 修改前务必关闭 Codex 应用
- 给自己的 provider 取固定名称可以避免很多麻烦
- 大量迁移建议编写自动化脚本
核心要点
- Codex对话记录按provider隔离,切换API和官方订阅后对话并未删除,只是归属不同provider
- 迁移对话需同时修改sessions文件夹中的JSON文件和state.db数据库中的model_provider字段
- 操作前必须关闭Codex应用,且两处修改必须同步进行,否则系统可能自动纠正回原值
- 给第三方API的provider设置固定自定义名称,可避免更换服务商时对话丢失
- 可利用Codex编写Python自动化工具批量完成对话迁移操作
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。