Codex额度总不够用?AnySearch Skill帮你省下大量Token
AnySearch Skill可为Codex节省约27%搜索额度并提升信息质量
Codex在执行搜索任务时,Agent直接解析网页会将大量冗余HTML内容带入上下文,造成Token严重浪费。AnySearch Skill通过将搜索外包给专业基础设施,以干净的Markdown格式返回结构化结果,实测可节省约27%额度消耗,同时搜索质量和信息覆盖范围显著提升,安装仅需一条命令。
问题:Codex搜索太烧额度
如果你正在使用 Codex,却发现额度总是莫名其妙地飞速消耗,问题很可能出在搜索环节上。
Codex 在执行任务时,不可避免地需要上网搜索各种信息——查阅技术文档、做用户调研、爬取 GitHub 仓库,甚至搜集 AI 资讯。但搜索操作其实是一个巨大的 Token 黑洞:Agent 每打开一个网页,都可能把大量与正文无关的网页代码、广告信息、导航栏等冗余内容一股脑带进上下文。搜索轮次一多,你的额度就迅速见底了。
为什么网页内容会消耗这么多Token? Token 是大语言模型处理文本的基本计量单位,Codex 等 AI 编程工具按 Token 用量计费,包括输入和输出两部分。上下文窗口(Context Window)是模型在单次对话中能"看到"的最大 Token 数量。当 Agent 自行打开网页时,一个普通网页的原始 HTML 往往包含数万个 Token 的冗余内容——CSS 样式表、JavaScript 代码、广告脚本、导航菜单等,这些与任务完全无关的内容会大量占用上下文窗口,既推高计费成本,又可能将真正有用的信息"挤出"窗口之外,导致模型遗忘关键上下文。
这不是你 Prompt 写得不好,而是底层搜索机制本身的效率问题。幸运的是,有一个专门解决这个痛点的工具——AnySearch Skill。
AnySearch Skill 是什么?它如何帮 Codex 省 Token?
AnySearch 是一个专为 Codex 设计的 Skill(技能插件),核心思路非常简单:把搜索这件最重的活从 Agent 身上卸下来,交给专业的搜索基础设施去完成。
工作原理
要理解 AnySearch 的价值,首先需要了解 Codex 的 Agent 架构。AI Agent(智能体)是一种能够自主规划、调用工具并执行多步骤任务的 AI 系统,与传统单轮问答有本质区别。Codex 底层依赖 Function Calling(函数调用)机制——模型在推理过程中可以声明"我需要调用某个工具",系统随即执行并将结果返回给模型继续推理。Skill 本质上就是向 Agent 注册一个新的可调用工具,这种插件化架构使得 Agent 的能力可以按需扩展,无需修改模型本身。
传统模式下,Codex Agent 自己打开网页、解析 HTML、提取信息,整个过程中大量无关内容被塞进上下文窗口,既浪费 Token 又降低回答质量。
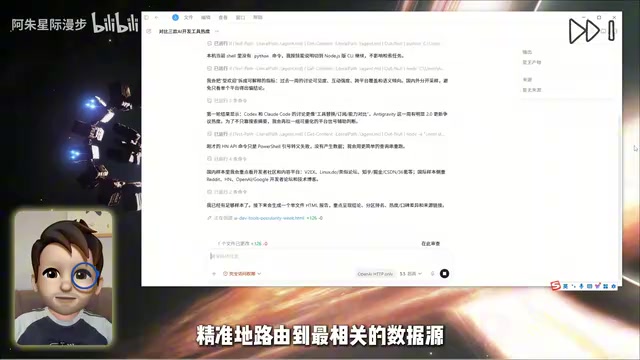
安装 AnySearch Skill 后,Agent 在需要搜索时会自动调用 AnySearch 的 API。AnySearch 在后台完成所有搜索工作——从海量信息渠道中精准路由到最相关的数据源,然后将结果以干净的 Markdown 格式传回给 Agent。
为什么返回 Markdown 而不是 HTML? 专业搜索基础设施与普通浏览器访问的核心差异在于数据清洗和结构化能力。AnySearch 会预先去除 HTML 标签、广告和导航等噪声,只保留正文语义内容;同时具备智能路由能力,能根据查询意图判断应访问技术文档站、社交媒体还是代码仓库等不同数据源。Markdown 是对 LLM 极为友好的结构化文本格式,相同信息量下 Token 消耗远低于 HTML,且语义结构清晰,模型能更高效地提取关键信息。这种"搜索即服务"模式,本质上是将信息获取的计算成本从昂贵的 LLM Token 转移到更廉价的专用搜索算力上。
Agent 接收到的是已经过滤和结构化的信息,而不是原始的网页垃圾。
安装方式
安装过程非常「AI 原生」:
- 前往 AnySearch 官网,复制 Skill 的安装命令
- 将命令粘贴发送给 Codex
- Codex 自动完成安装
之后在对话中引用这个 Skill,Codex 就能自动调用它进行搜索。
实测对比:AnySearch 到底能省多少额度?
为了验证 AnySearch 的实际效果,作者设计了一个颇有难度的测试任务:对比过去一周 Codex、Cloud Code 和 AntiGravity 这三款主流 AI 开发工具,在国内外社交媒体和论坛中哪个更受欢迎,并用一个简洁美观的 HTML 网页呈现结果。
使用 AnySearch 的结果
测试前额度为 98%。AnySearch 收到请求后,从海量信息渠道中精准定位到最相关的数据源,最终呈现的结果非常丰富:
- 结论清晰:直接给出 Codex 综合排名第一的判断
- 量化数据充足:追踪了 NPM 下载量、Reddit 评论数和 Hacker News 帖子数等多维度指标
- 定性分析到位:基于搜索结果提供了深入的分析
- 搜索覆盖广泛:从安装源到国内外社区论坛、官网都有涉及
这些指标为什么有参考价值? 在评估开发者工具的市场接受度时,技术社区通常依赖几个公认的量化指标。NPM 下载量是衡量 JavaScript/TypeScript 生态工具采用率的黄金标准,其数据公开透明且难以造假。Reddit 的技术子版块是英语开发者社区最活跃的讨论场所,评论数能反映真实的用户讨论深度。Hacker News 则是硅谷科技圈的核心信息聚合平台,由 Y Combinator 运营,用户群体以早期技术采用者和创业者为主,一个工具能在 HN 首页获得高分往往意味着在核心技术圈引发了真实关注。这三个维度结合国内社交媒体数据,构成了相对完整的技术工具热度评估框架。
最终消耗:18 个点(基于 5 小时额度计算)。
不使用 AnySearch 的结果
用完全相同的 Prompt,在不启用 AnySearch 的条件下再跑一次:
- 整体呈现上信息明显缩略
- 搜索源大幅减少
- 消耗额度却多出了 5 个点,达到 23 个点
这就是低效搜索带来的隐性成本:花了更多的 Token,却得到了更少、更差的信息。差距约为 27% 的额度浪费,而且搜索质量还明显下降。
为什么 Codex 用户值得安装 AnySearch?
从这次实测中,可以提炼出 AnySearch 的几个核心价值:
1. 显著降低 Token 消耗
通过将搜索工作外包给专业的搜索基础设施,避免了 Agent 直接解析网页带来的大量冗余 Token 消耗。实测节省约 27% 的额度。
2. 提升搜索质量
AnySearch 能够从更多、更精准的数据源获取信息,覆盖范围远超 Agent 自行搜索的能力。无论是量化数据还是定性分析,结果都更加丰富。
3. 零学习成本
安装只需一条命令,使用只需在对话中引用 Skill 名称。完全符合 AI 原生的交互方式,没有额外的配置负担。
4. 适用场景广泛
AnySearch 不仅适用于技术开发场景,从专业维度到日常生活的各个领域都能覆盖。无论是市场调研、竞品分析还是信息搜集,都能发挥作用。
总结
对于 Codex 重度用户来说,AnySearch Skill 解决的是一个非常实际的问题:搜索是 Agent 工作流中最消耗资源却最容易被忽视的环节。与其让 Agent 笨拙地打开一个个网页、吞下大量无关内容,不如把这件事交给专业工具来做。省下来的不只是额度,更是每次任务的信息质量和响应效率。
如果你经常用 Codex 做需要联网搜索的任务,这个 Skill 值得第一时间装上。
核心要点
- Codex在执行搜索任务时会将大量无关网页内容带入上下文,导致Token消耗严重
- AnySearch Skill通过API调用专业搜索基础设施,将结果以Markdown格式返回Agent,大幅减少冗余信息
- 实测对比显示使用AnySearch可节省约27%的额度消耗,同时搜索质量和信息覆盖范围显著提升
- 安装过程极其简单,只需复制官网命令发送给Codex即可自动完成,使用时在对话中引用即可
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。