Codex vs Claude Code搭配DeepSeek实测:速度差5.7倍,稳定性40vs100

搭配DeepSeek时,Claude Code在稳定性和速度上全面碾压Codex
一位开发者通过30次实测对比发现,搭配DeepSeek模型时,Claude Code稳定性满分(100分),而Codex仅40分;速度方面Claude Code快5.7倍。核心原因在于Claude Code原生支持第三方模型协议,而Codex使用OpenAI新版协议需额外转换,导致兼容性和性能双重下降。国内使用DeepSeek的开发者更推荐选择Claude Code。
背景:Codex真的碾压Claude Code吗?
最近社区铺天盖地都是「Codex碾压Claude Code」的声音,但这些结论是否经过严格测试验证?一位开发者决定亲自动手,用科学的方法做一次真实对比——当两款AI编程工具都搭配DeepSeek模型时,究竟谁的表现更胜一筹?
结果出乎很多人意料:Claude Code + DeepSeek的组合在稳定性和速度上全面领先Codex + DeepSeek,差距之大令人惊讶。
行业背景:当前AI编程工具市场正经历一场「底层模型解耦」的变革。早期工具与模型深度绑定(如Copilot绑定OpenAI、Claude Code绑定Anthropic),但随着DeepSeek等高性价比模型的崛起,开发者开始追求「自选底层模型」的灵活性。这催生了两种技术路线:一是工具原生支持多种第三方协议;二是通过中间代理层做协议转换。两种路线在稳定性和性能上的差异,正是本次测评揭示的核心矛盾。
测评方案设计:用AI测AI
这次测评的方法论值得关注。测试者使用VS Code Copilot配合OPAI 4.7来设计PK测评方案,再用Sonnet 4.6执行测评并生成报告,整个过程体现了「用AI测AI」的思路。

这种「AI套AI」的自动化评测范式正在兴起,其优势在于测试用例设计更系统、执行过程可重复、报告生成效率高。但也存在局限:AI设计的测试场景可能存在覆盖盲区,且30次样本在统计学上置信区间较宽。对于工程决策而言,这类测评更适合作为「快速筛选」依据,而非最终定论,建议结合自身真实业务场景做补充验证。
测评耗时约两个小时,消耗了约五块钱的DeepSeek API费用,总共跑了30次测试。这样的样本量虽然不算庞大,但对于工具级别的对比已经具有一定参考价值。DeepSeek凭借极低的API调用成本(相比GPT-4系列便宜约90%)和接近顶级模型的代码能力,迅速成为国内开发者的主流选择——约5元人民币跑完30次测试,直观体现了其成本优势,这也是国内开发者热衷于将其接入各类AI工具的核心驱动力。

测试结果:Codex与Claude Code差距惊人
响应速度对比:Claude Code快5.7倍
Codex + DeepSeek的响应速度比Claude Code + DeepSeek慢了5.7倍。对于日常编程场景来说,这意味着每次交互都要多等好几倍的时间,严重影响开发效率和使用体验。
稳定性对比:100分 vs 40分
更关键的是稳定性指标。Claude Code + DeepSeek获得了满分100分,而Codex + DeepSeek仅得到40分。
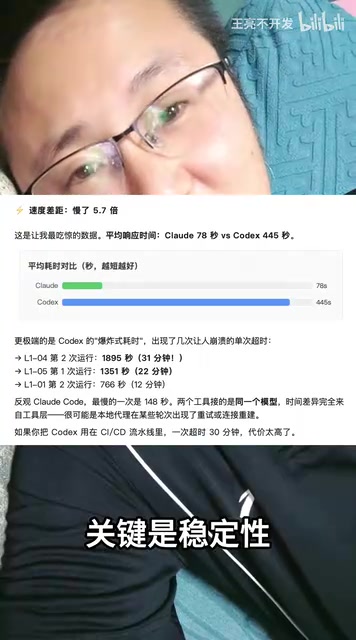
40分的稳定性意味着什么?简单来说就是「根本没法用」——你无法预期每次调用是否能得到正确的结果,这在实际开发中是不可接受的。
原因分析:第三方模型协议支持是关键
为什么同样搭配DeepSeek,两款工具的表现差距如此之大?核心原因在于对第三方模型的协议支持方式不同。

Claude Code:原生支持第三方模型协议
Claude Code原生支持第三方协议,用户只需简单配置即可接入DeepSeek等第三方模型,整个链路经过充分优化,通信稳定高效。
Codex:协议转换带来兼容性问题
Codex支持的是OpenAI新版协议,而DeepSeek目前还不支持该协议。理解这一问题需要了解协议演进背景:OpenAI的API经历了多次迭代,其最新版本引入了Responses API等新特性,与旧版Chat Completions API存在显著差异。DeepSeek等第三方模型通常优先兼容旧版Chat Completions协议(因其更稳定、文档更完善),对新版协议的支持存在滞后。
这意味着用户需要自行做协议转换(通常通过中间代理层实现)。当Codex调用新版协议而DeepSeek尚未完整实现时,中间代理层需要做字段映射、请求格式转换等操作,每一步都可能引入延迟或触发边缘case导致请求失败——这个额外的转换环节直接导致了速度和稳定性的双重下降,也正是40分稳定性的根本成因。
国内开发者实用选型建议
对于国内开发者来说,如果你的主力模型是DeepSeek,那么目前更推荐使用Claude Code作为AI编程工具。DeepSeek的V3和R1系列在多项编程基准测试中表现优异,尤其在中文代码注释、国内框架理解等场景有本土化优势,与Claude Code的原生协议支持相结合,能最大化发挥两者的优势。原因很简单:
- 原生协议支持:无需额外的协议转换层,配置简单
- 稳定性有保障:满分的稳定性意味着可以放心用于生产环境
- 速度优势明显:5.7倍的速度差距在日常使用中体感非常强烈
当然,这个结论有其适用范围——它仅针对搭配DeepSeek的场景。如果使用各自原生模型(Codex用GPT系列,Claude Code用Claude系列),结果可能完全不同。工具选择最终还是要根据自己的实际使用场景来决定。
总结
这次Codex与Claude Code的实测对比给我们的启示是:不要盲目跟风社区的「碾压」论调。工具的实际表现取决于具体使用场景和配置方式。在第三方模型接入这个维度上,Claude Code目前确实做得更好,而Codex在新版协议的兼容性问题解决之前,搭配DeepSeek的体验还有很大提升空间。
核心要点
- Claude Code + DeepSeek稳定性得分100分,Codex + DeepSeek仅40分,差距悬殊
- Codex + DeepSeek速度比Claude Code + DeepSeek慢5.7倍
- 核心原因是协议支持差异:Claude Code原生支持第三方协议,Codex需要额外协议转换(新版Responses API与DeepSeek当前兼容的Chat Completions协议存在代差)
- 国内使用DeepSeek模型的开发者更推荐选择Claude Code
- 测评基于30次测试,耗时两小时,消耗约5元DeepSeek API费用
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。