Codex与Cloud Code实战指南:AI编程智能体入门到精通
从大模型到智能体:AI编程工具的本质跃迁
很多人在使用ChatGPT时,可能只停留在"对话问答"的层面——问一个问题,得到一个回答。但如果你还停留在这个阶段,那你对AI编程工具的理解可能已经落后了。
当前AI编程领域正在经历一场关键转变:从单纯的大模型工具,进化到具备执行能力的AI编程智能体。这个区别至关重要。大模型就像一个只有大脑的人,它能思考、能分析,但无法真正帮你动手做事。而Codex、Cloud Code这类智能体工具,则相当于给大脑装上了手脚和工具——不仅能想,还能做。
从技术架构上看,大语言模型(LLM)的本质是一个基于Transformer架构的文本生成系统。Transformer由Google在2017年的里程碑论文《Attention Is All You Need》中提出,其核心创新——自注意力机制(Self-Attention)——使模型能够并行处理序列中任意位置之间的依赖关系,彻底取代了此前RNN/LSTM的顺序处理方式,为后来GPT、Claude等大模型的诞生奠定了架构基础。LLM通过海量语料训练获得了强大的语言理解和生成能力,但其运行范式是"输入-输出"的单轮或多轮对话。而AI智能体(Agent)在LLM基础上引入了工具调用(Tool Use)、环境感知(Environment Perception)和行动规划(Action Planning)等关键能力。智能体架构通常包含一个推理循环:感知当前状态→制定计划→调用工具执行→观察结果→调整策略,这种"ReAct"(Reasoning + Acting)范式使AI从被动应答转变为主动执行。ReAct范式由Princeton和Google在2022年联合提出,其核心洞察是:将大模型的链式推理(Chain-of-Thought)能力与外部工具调用交织进行,让模型在每一步推理后都能采取实际行动并观察结果,从而形成一个动态的"思考-行动-观察"闭环,这正是当前AI编程智能体的核心工作模式。
简单来说,传统大模型只能给你一段代码让你自己粘贴,而AI编程智能体可以直接帮你修改文件、运行测试、提交代码,完成从构思到落地的全流程。
Codex与Cloud Code:第一梯队的两大AI编程智能体
在众多AI编程工具中,OpenAI的Codex和Anthropic的Cloud Code目前处于绝对的第一梯队。这两款工具是当前程序员群体中使用最广泛的AI编程智能体,在代码生成质量和任务执行能力上远超其他同类产品。
为什么Codex和Cloud Code能脱颖而出?
原因在于它们不仅具备强大的代码理解和生成能力,更关键的是它们能够:
- 直接操作代码仓库:读取、修改、创建文件,而非仅仅输出代码片段
- 理解项目上下文:能够把握整个项目的架构和依赖关系
- 执行多步骤任务:从需求分析到代码实现,再到测试验证,形成完整闭环
- 与开发环境深度集成:无缝嵌入现有的开发工作流
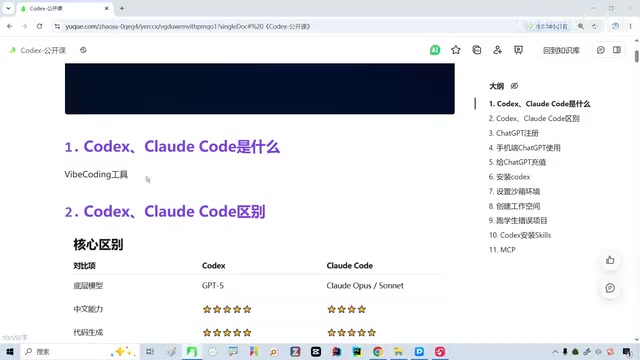
Codex与Cloud Code的定位差异
虽然Codex和Cloud Code同属第一梯队,但它们各有侧重,尤其在运行架构上代表了两种截然不同的设计哲学:
OpenAI的Codex最初于2021年发布,是在GPT-3基础上用GitHub上数十亿行公开代码进行微调的专用模型,也是GitHub Copilot的底层引擎。2025年,OpenAI推出了全新的Codex智能体版本,它运行在ChatGPT内部的云端沙箱环境中,能够克隆用户的代码仓库、在隔离容器中执行代码、运行测试套件,并以Pull Request的形式提交修改。云端沙箱通过容器化技术(如Docker)在完全隔离的环境中执行代码,确保用户代码不会影响宿主系统,同时提供了标准化的运行环境,避免了"在我机器上能跑"的经典问题。其底层依赖的codex-1模型是在o3基础上针对软件工程任务进行强化学习优化的版本。
Claude Code则是Anthropic推出的命令行AI编程智能体,直接运行在开发者的终端环境中。与Codex的云端沙箱模式不同,Claude Code采用本地优先的架构,能够直接访问开发者机器上的文件系统、Git仓库和开发工具链。这种本地优先的设计意味着所有计算和文件操作都保留在开发者本机,对于涉及敏感代码、知识产权保护或合规要求严格的企业场景更具吸引力,但也要求开发者对权限管理更加谨慎。其底层依赖Claude系列模型,尤其是Claude 3.5 Sonnet和Claude 4系列,这些模型在长上下文窗口(支持高达200K token)和代码推理方面表现突出。Anthropic独创的Constitutional AI(宪法AI)训练方法也使Claude在遵循复杂指令和安全约束方面具有独特优势。Constitutional AI通过让AI根据一组预定义的原则(即"宪法")来自我评估和修正输出,并使用RLAIF(基于AI反馈的强化学习)替代传统的RLHF(基于人类反馈的强化学习)进行微调,使模型在遵循复杂多层指令时表现更加稳定——在AI编程场景中,这体现为更好地遵守代码规范约束、安全边界和用户指定的架构风格。
| 对比维度 | Codex | Cloud Code |
|---|---|---|
| 底层模型 | OpenAI GPT系列(codex-1基于o3优化) | Anthropic Claude(3.5 Sonnet / Claude 4) |
| 运行方式 | 云端沙箱环境 | 本地终端命令行 |
| 核心优势 | 通用代码生成、多语言支持、云端隔离执行 | 代码推理、长上下文理解、本地环境深度集成 |
| 适用场景 | 快速原型开发、多语言项目、CI/CD集成 | 复杂逻辑分析、大型代码库、本地开发流程 |
对于开发者而言,选择哪一个更多取决于具体使用场景和成本考量——哪个效果好、哪个成本低,就用哪个。实际工作中,不少开发者会同时使用两者,根据任务特点灵活切换。
非程序员也能用:AI编程智能体的核心价值
一个非常重要的观点是:AI编程智能体不仅仅是程序员的工具,而是每个人都应该掌握的基础能力。
这听起来可能有些夸张,但逻辑很清晰:
对于非编程人员
即使你不会Java、不会Python,甚至完全不懂代码,AI编程智能体依然对你有巨大价值。你可以用自然语言描述需求,让AI帮你生成脚本、处理数据、搭建简单的应用。最基础的,至少配一个ChatGPT用来日常查询和辅助工作,这已经是提升效率的显著手段。
比如运营人员可以让AI自动生成数据分析脚本,产品经理可以快速搭建原型验证想法,这些过去需要排期等开发的工作,现在自己就能完成。这种转变的本质是编程门槛的民主化——自然语言正在成为一种新的编程语言,而AI智能体则充当了从人类意图到机器指令之间的翻译器。这一趋势与计算机科学的长期演进方向一脉相承:从机器码到汇编语言,从汇编到C/Java等高级语言,从高级语言到Python等脚本语言,每一次抽象层级的提升都大幅降低了编程的准入门槛,而自然语言编程可能是这条路径上最具革命性的一步。
对于编程人员
如果你是专业开发者,那这些工具更是不可或缺。它们能够将你从重复性的编码工作中解放出来,让你专注于架构设计和业务逻辑等更高层次的思考。代码审查、Bug修复、单元测试编写——这些耗时的任务都可以交给智能体来完成。据多项行业调研显示,使用AI编程智能体的开发者在日常编码任务上的效率提升普遍在30%-50%之间,而在样板代码生成和文档编写等任务上,效率提升甚至可以达到数倍。值得注意的是,这种效率提升并不意味着开发者可以放松对代码质量的把控——AI生成的代码仍然需要人工审查,尤其是在安全敏感、性能关键或业务逻辑复杂的场景中。优秀的开发者正在从"代码编写者"转变为"AI输出的审查者和架构师",这种角色转变要求开发者具备更强的系统设计能力和代码评审能力。
国内外AI编程模型的差距与发展趋势
关于国内外AI模型的差距,一个相对客观的判断是:目前国外模型确实领先一小步,但这个差距正在快速缩小。
从实际使用体验来看,OpenAI和Anthropic的模型在代码生成质量、复杂逻辑推理等方面仍然占据优势。但国内的大模型也在快速迭代,尤其在中文场景和特定垂直领域已经展现出不俗的实力。
值得特别关注的是,DeepSeek推出的DeepSeek-Coder系列在多个代码基准测试(如HumanEval、MBPP)上达到了接近GPT-4的水平,且采用了混合专家(MoE)架构大幅降低了推理成本。MoE的核心思想是将模型参数分成多个"专家"子网络,每次推理时通过门控机制只激活其中一小部分专家来处理输入,而非像传统密集模型那样激活所有参数。这使得模型可以拥有极大的总参数量以提升能力上限,同时保持较低的单次推理计算成本——DeepSeek-V2/V3正是将MoE与多头潜在注意力(MLA)等创新结合,在代码生成等任务上实现了性能与成本的最优平衡,这也是其能够以极低价格提供API服务的技术基础。
阿里的通义千问(Qwen)系列同样在代码生成任务上表现优异,Qwen2.5-Coder在部分评测中甚至超越了同参数量级的国外模型。这些模型的开源策略也加速了国内AI编程生态的发展,使得更多开发者和企业能够基于这些模型构建自己的编程辅助工具。百度的文心一言则在中文编程场景和企业级应用中持续深耕,形成了差异化的竞争优势。
这里值得补充的是,衡量AI编程模型能力的基准测试本身也在快速演进。除了前述的HumanEval(OpenAI发布的164道Python编程题,使用pass@k指标衡量)和MBPP(Google发布的974道入门级Python任务)之外,社区还发展出了更贴近实际开发场景的评测集:SWE-bench评估模型解决真实GitHub Issue的能力,LiveCodeBench使用最新竞赛编程题防止训练数据泄露问题。这些更具挑战性的评测正在成为衡量AI编程智能体实战能力的新标准,也使得各家模型的真实差距更加透明。
长远来看,AI编程工具的选择将越来越不取决于"国内还是国外",而是取决于性价比和场景适配度。当各家模型能力趋于接近时,成本和易用性将成为决定性因素。
实践建议:从零开始使用AI编程智能体
对于想要入门AI编程智能体的读者,以下是一条经过验证的学习路径:
- 先从ChatGPT开始:熟悉与AI对话式编程的基本模式,学会用自然语言精确描述需求
- 尝试Codex或Cloud Code:选择一个深入使用,理解智能体与普通对话的本质区别。Codex适合偏好图形界面和云端工作流的用户,Claude Code则更适合习惯命令行操作的开发者
- 从小项目练手:不要一上来就做大型项目,先用AI完成一些小脚本、小工具,比如自动化文件整理、数据格式转换等
- 学会Prompt工程:好的提示词是获得高质量输出的关键,这是一项需要刻意练习的技能。Prompt工程远不止是"写好提示词"这么简单,它实际上是一套与AI系统高效协作的方法论。核心技巧包括:Few-shot Prompting(提供少量示例引导输出格式,让模型通过类比学习理解你期望的输入输出模式)、Chain-of-Thought(要求AI逐步推理而非直接给出答案,研究表明这种方式能显著提升模型在数学和逻辑推理任务上的准确率)、角色设定(为AI指定专家身份以激活特定领域知识,例如"你是一位有10年经验的后端架构师")、以及约束声明(明确输出的语言、格式、长度等限制条件)。在AI编程智能体场景中,还需要学会如何描述项目架构、指定代码风格规范、以及如何将复杂需求拆解为智能体可执行的子任务。一个实用的进阶技巧是为常用场景编写可复用的Prompt模板,并建立个人的Prompt库,随着使用经验的积累不断优化迭代
- 保持工具中立:不要绑定在某一个工具上,保持对新工具的敏感度和学习能力。AI编程工具的迭代速度极快,今天的最优选择可能在几个月后就被新工具超越。建议定期关注主流AI编程工具的更新动态,参与开发者社区的讨论,并在实际项目中对比不同工具的表现
AI编程智能体的时代已经到来,无论你是什么背景,现在开始学习都不算晚。关键是迈出第一步,在实践中不断积累经验。当你真正体验过让AI帮你从零搭建一个小工具的全过程,你就会理解为什么说这是每个人都该掌握的能力。
核心要点
核心要点
相关推荐

Google WebMCP是什么?AI Agent直接调用网页功能的新标准详解
深入解析Google WebMCP(Web Model Context Protocol)的工作原理、技术实现与应用场景。了解WebMCP如何让AI Agent直接调用网页工具,告别脆弱的DOM解析和屏幕抓取方式。
AI杀不死古法编程:为什么基本功仍是程序员的护城河
AI编程工具让Vibe Coding成为潮流,但氛围编程真能替代扎实的基本功吗?深度分析为什么底层原理、系统思维和知识体系仍是程序员的核心竞争力,以及如何在AI时代守住你的技术护城河。
ZeroStack:16MB内存的Rust极简编程Agent深度体验
深度评测ZeroStack这款仅占16MB内存的Rust编程Agent,分析其文件读写、多模型接入、权限控制等核心功能,探讨适用场景与局限性,帮你判断是否值得使用。