ComfyUI本地生成AI漫剧:图像到成片完整制作流程

详解100%本地生成AI漫剧的完整制作流程与实战技巧
B站UP主「程序员萝卜」以漫威英雄采访短片为例,拆解了仅需4060Ti显卡即可完成的本地AI漫剧制作全流程。核心工具包括LTX 2.3视频模型(首尾帧模式生成视频)、KLEIN图像编辑模型(快速生成关键帧图像)和QWEN TTS语音模型(生成角色语音)。教程强调图像编辑是基石,提示词需简洁精准,同一角色台词应一次性生成以保证音色一致。
引言:AI漫剧制作的现实与理想
很多人对AI漫剧制作存在一个误解——以为只需要一个简单的提示词,AI就能自动生成完整的分镜脚本和成品视频。但现实是,不管是开源模型还是闭源模型,目前都做不到这一点。B站UP主「程序员萝卜」在第268期教程中,以一个漫威英雄采访短片为例,详细拆解了100%本地生成AI漫剧的完整流程,所用硬件仅需4060Ti显卡。
这期教程的核心价值在于:它不是夸夸其谈的理论,而是一个经过实践验证的、可复现的制作方案。整个流程涉及LTX 2.3视频模型、KLEIN图像编辑模型和QWEN TTS语音模型三大核心工具。
图像准备:AI漫剧制作的基石
为什么图像是关键
在LTX首尾帧模式下,所有关键性动作都需要预先用图像来表达。这意味着你不能指望纯靠提示词让模型自动生成复杂动作——比如绿巨人把女孩抱起来、钢铁侠和女孩对拳等动作,都必须预先制作好对应的图像。
技术背景:LTX首尾帧模式 LTX(Latent Text-to-video eXtension)是一类基于扩散模型的视频生成架构。首尾帧模式(First-Last Frame Conditioning)是指在生成视频时,同时提供起始帧和结束帧作为约束条件,让模型在两帧之间进行运动插值和内容填充。这种方式本质上是将视频生成问题转化为"受约束的时序插值"问题,相比纯文本驱动的视频生成,大幅降低了模型需要"自由发挥"的空间,因此人物一致性和画面稳定性显著提升。代价是创作者必须预先设计好关键帧图像,制作门槛从"写提示词"上升到"会图像编辑"。
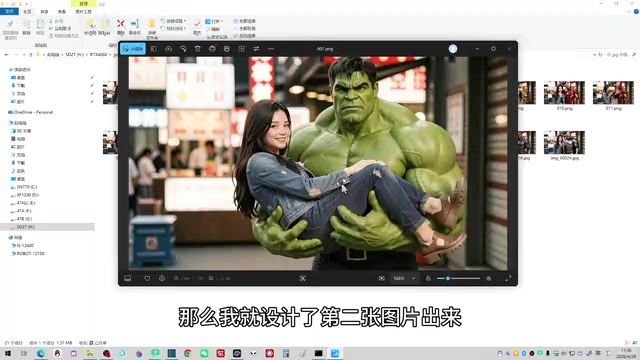
以这个漫威英雄采访短片为例,一个英雄的20秒访问片段需要5张图片。制作流程如下:
- 生成原始图片:先生成女孩的基础图片
- 合成角色图片:使用KLEIN模型生成女孩与各英雄的合影
- 设计动作图片:为每个关键动作单独生成图片(如抱起、摸胸肌等)
- 图像修正:用KLEIN单图编辑修正细节(如给钢铁侠加上金属手套)
KLEIN模型图像编辑实战技巧
图像编辑使用的是第230期教程中介绍的KLEIN单图编辑功能。KLEIN是一种指令驱动的图像编辑模型,属于InstructPix2Pix范式的进化版本,其核心能力是根据自然语言指令对已有图像进行局部或全局修改,无需用户手动绘制蒙版(Mask)。与传统的Inpainting方法相比,KLEIN能理解语义级别的编辑意图,例如"给角色加上金属手套"或"将两个人物合成到同一场景中"。这个模型的优势是速度极快,13秒即可完成一次编辑,得益于其轻量化的推理架构设计,使其在消费级显卡上也能快速迭代出图。但需要注意的是,不是每张生成的图都能直接使用,需要反复"刷图"直到获得满意的结果。
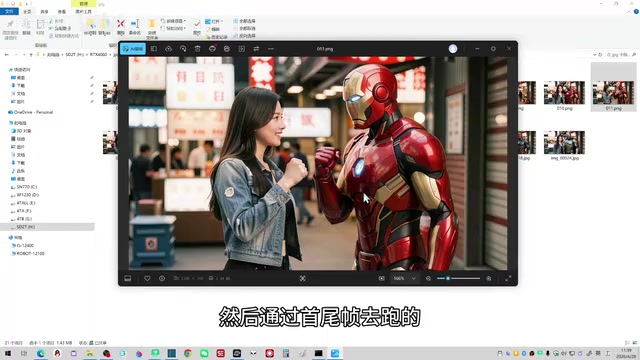
这里有一个重要的认知:想做好AI视频,必须掌握基本的图像编辑能力。那些完全不学图像编辑就想靠视频模型直接出片的想法,在目前的技术条件下基本不可能实现。
LTX首尾帧模式详解:优势与局限
核心优势
- 速度快:4060Ti显卡即可流畅运行
- 长视频支持:通过首尾帧衔接可以生成较长的连续视频
- 人物一致性好:首尾帧模式下的人物一致性远优于单纯的图生视频
不可忽视的局限
- 衔接处微卡顿:每个首尾帧之间的衔接处会有轻微卡顿,这是先天缺陷
- 提示词响应差:由于首尾帧已经确定了画面的大部分运动状态,提示词的影响力有限
- 运镜受限:运镜效果需要通过首尾帧图片来实现,而非提示词控制
提示词的正确写法
提示词要简洁但精准。例如"女人笑着说话,漫威英雄死侍从右边走进画面"——其中"走进画面"这几个字至关重要。如果不写,模型可能会用突然切镜头或转场的方式把人物放到画面中,看起来非常不自然。
不要写太复杂的提示词,写了复杂的它也实现不了。那些拿着复杂分镜脚本去跑LTX首尾帧的方案,最终能跑出来的概率非常低。
语音生成与合成:用QWEN TTS让角色开口说话
QWEN TTS语音生成策略
语音部分使用的是第257期教程中的QWEN TTS模型。QWEN TTS是阿里巴巴通义千问系列的文本转语音模型,属于大语言模型驱动的神经网络TTS(Text-to-Speech)系统。与传统TTS不同,基于LLM的TTS能够理解语境、情感和语调,生成更自然的语音,其声音特征(音色、语速、情感倾向)由提示词中的描述性文字控制。
这里有一个关键技巧:同一角色的所有台词应该一次性生成,而不是分段生成。
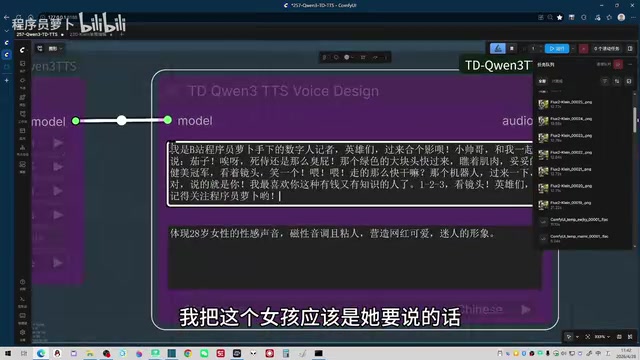
原因在于技术层面:同一次推理过程中,模型会维持相对稳定的隐空间表示(Latent Representation),从而保证音色的一致性;而多次独立推理则可能因随机种子和上下文差异导致音色漂移(Voice Drift)。比如女孩的所有台词(开场白、采访问题、结束语)全部写在一个流程中一次性生成,最终得到36秒的完整语音。
而三个漫威英雄因为是不同角色,需要分别用不同的流程生成,通过调整提示词中的声音描述(如"中年男性的声音,欧美口音,挑逗的声音
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。