ComfyUI工作流制作AI视频:从脚本到成片完整教程
ComfyUI节点式工作流实现AI视频从脚本到成片的自动化制作
本文拆解了ComfyUI制作AI视频的完整技术流程:首先通过集成LLM节点生成结构化分镜脚本,再利用图像生成模型配合ControlNet和IPAdapter生成一致性关键帧,然后借助SVD、AnimateDiff或Wan2.1等视频扩散模型从首尾帧合成视频片段,最后拼接配音完成成片。这种基于关键帧引导的方式在画面过渡、角色一致性和场景连贯性上优于纯文本生成视频。
前言:AI视频制作正在走向工作流化
随着AI视频生成技术的快速迭代,ComfyUI作为一款开源的节点式工作流工具,正在成为AI视频创作者的核心生产力平台。近期B站上涌现了大量ComfyUI视频制作的教程内容,其中不少展示了从脚本生成到视频合成的完整工作流。本文将基于这些公开信息,拆解ComfyUI制作AI视频的技术流程,并客观分析其实际应用价值。
ComfyUI视频工作流的核心流程
第一步:用AI生成视频脚本与分镜
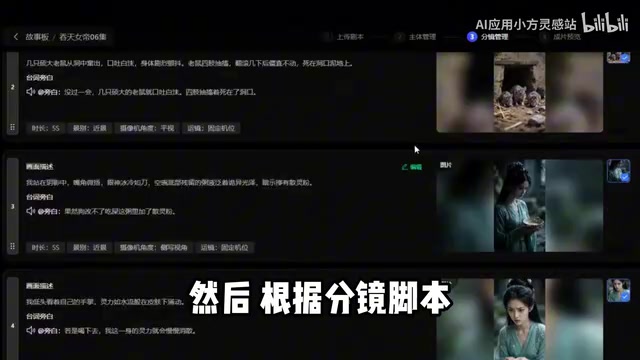
整个ComfyUI工作流的起点并非直接生成画面,而是从文案策划开始。通过在ComfyUI工作流中集成大语言模型(LLM)节点,用户只需输入一个选题方向,AI就能自动生成视频脚本大纲。
在ComfyUI工作流中集成LLM节点,通常通过调用本地部署的Ollama模型(如Llama 3、Qwen2.5)或远程API(OpenAI、Claude、DeepSeek)实现。这一集成的技术基础是LLM的结构化输出能力——通过精心设计的系统提示词(System Prompt),可以让模型按照固定JSON Schema输出分镜脚本,再由下游节点解析并分发到对应的图像生成流程。提示词工程(Prompt Engineering)在此环节至关重要:一个优质的分镜提示词需要同时满足图像生成模型的语法规范(如Stable Diffusion偏好的标签式描述)和视频叙事的逻辑连贯性。业内已有研究者专门训练用于"文本到提示词"转换的微调模型,以弥合自然语言描述与图像模型输入格式之间的语义鸿沟。
在此基础上,进一步输入指令可以让AI生成完整的分镜脚本,包含以下关键要素:
- 每个镜头的画面描述
- 镜头运动方式(推、拉、摇、移等)
- 配音文案
- 画面细节与风格指定
这一步的本质是利用LLM的文本生成能力,将模糊的创意构思转化为结构化的制作蓝图,大幅降低了前期策划的门槛。
第二步:生成分镜关键帧图片
有了分镜脚本后,下一个关键环节是为每个镜头生成首帧图和尾帧图。ComfyUI工作流会根据分镜脚本自动生成精准的图像提示词(Prompt),用户将这些提示词输入到图生图模块中,即可生成对应的画面。
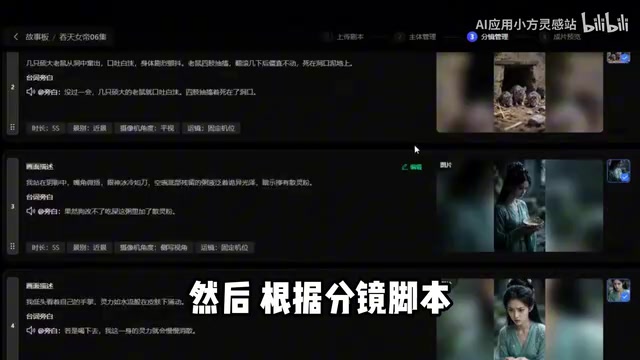
这里有两个技术要点值得关注:
- 首帧和尾帧的一致性控制:通过ControlNet、IPAdapter等技术手段,确保同一场景中角色形象和画面风格的统一
- 提示词的精准度:AI生成的提示词需要包含足够的细节描述,才能让图像生成模型准确还原分镜意图
ControlNet与IPAdapter的技术原理值得深入了解。ControlNet是2023年由斯坦福研究者Lvmin Zhang提出的条件控制网络,其核心思想是在原有扩散模型的U-Net结构旁并联一个可训练的"控制分支",接受额外的结构信息输入(如边缘图、深度图、姿态骨架),从而在保持生成自由度的同时约束画面的空间结构。IPAdapter(Image Prompt Adapter)则将参考图像的CLIP视觉特征注入到注意力层,使生成图像在风格和外观上向参考图靠拢,无需重新训练模型。两者结合使用时,ControlNet负责控制"结构",IPAdapter负责控制"外观",是当前AI视频制作中维持角色一致性的主流技术组合。
第三步:从关键帧合成AI视频片段
拥有首尾帧图片后,将分镜脚本和图片一起交给ComfyUI工作流中的视频生成模块,即可自动合成完整的视频片段。目前主流的技术路线包括基于SVD(Stable Video Diffusion)、AnimateDiff或Wan2.1等模型进行帧间插值和视频生成。
这三类技术路线各有侧重:SVD将图像扩散模型在时间维度上展开,通过对视频帧序列进行联合去噪实现视频生成,与现有图像生成生态兼容性好;AnimateDiff通过在图像生成模型中插入运动模块(Motion Module)学习帧间运动规律,支持与LoRA等微调技术结合,灵活性较高;以Wan2.1、Kling、Sora为代表的原生视频扩散Transformer架构则采用DiT(Diffusion Transformer)替代U-Net,在时空注意力机制上进行统一建模,生成质量和运动流畅度更优,但对算力要求也更高。SVD和AnimateDiff更适合本地部署和工作流集成,原生视频模型则代表了技术演进的主流方向。

从实际展示的效果来看,这种基于首尾帧引导的AI视频生成方式,相比纯文本生成视频有明显优势:
- 画面过渡更自然:有了明确的起止画面,中间帧的生成更加可控
- 角色形象更统一:通过首尾帧锚定角色外观,减少了AI视频中常见的角色变形问题
- 场景连贯性更强:每个片段都有明确的视觉参照,避免了"凭空生成"的违和感
第四步:视频拼接与后期处理
所有AI视频片段生成完成后,最后一步是将它们导入剪辑软件进行拼接、配音和调整。整个流程据称可以在半小时内完成一条成品视频。
ComfyUI制作AI视频的技术优劣分析
ComfyUI的核心优势
ComfyUI由开发者comfyanonymous于2023年初发布,其核心设计理念来源于计算机图形学领域长期使用的节点式编辑范式——类似Blender的Shader Editor或Nuke的合成流程。每个"节点"代表一个独立的计算单元(如模型加载、采样器、图像解码),节点之间通过有向边传递张量数据,整个图结构本质上是一个有向无环图(DAG)。这种架构允许用户精确控制每一步的数据流向,复用已有节点组合,并通过保存JSON格式的工作流文件实现跨设备共享。目前ComfyUI的GitHub仓库已积累超过5万星标,围绕其构建的自定义节点生态(Custom Nodes)已超过数千个,覆盖从视频生成到3D资产处理的广泛场景。
ComfyUI之所以成为AI视频制作的热门工具,核心原因正在于此——与Stable Diffusion WebUI等工具相比,ComfyUI允许用户将多个AI模型和处理步骤串联成自动化流水线,实现"一键式
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。