从零搭建AI数字人Agent:架构设计与全流程技术拆解
基于Agent、RAG、WebRTC和Docker四大技术栈搭建AI数字人系统的实战解析。
本文围绕一个完整的AI数字人Agent实战项目,解析其四大核心技术栈:Agent智能体负责意图理解与任务编排,RAG检索增强生成赋予数字人专业知识并有效降低大模型幻觉,WebRTC实现低延迟实时音视频交互,Docker容器化实现一键部署。文章详细梳理了从用户输入到虚拟形象驱动的完整数据流,为开发者提供了可落地的工程化搭建思路。
引言:AI数字人Agent开发正当时
数字人技术正在快速渗透到直播带货、虚拟客服、企业培训等多个场景。然而,对于大多数开发者来说,从零搭建一个完整的AI数字人系统仍然门槛不低——它涉及大模型Agent、RAG检索增强生成、WebRTC实时通信、前端渲染等多个技术栈的深度整合。
本文基于一个完整的AI数字人Agent实战项目,梳理其核心架构、技术选型与搭建思路,帮助你理解如何打造一个具备智能对话、知识检索和虚拟形象驱动能力的数字人系统。
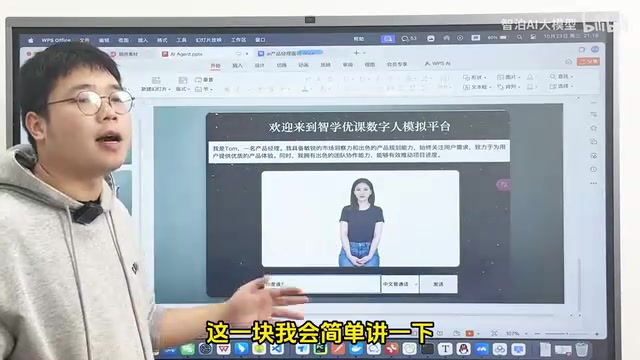
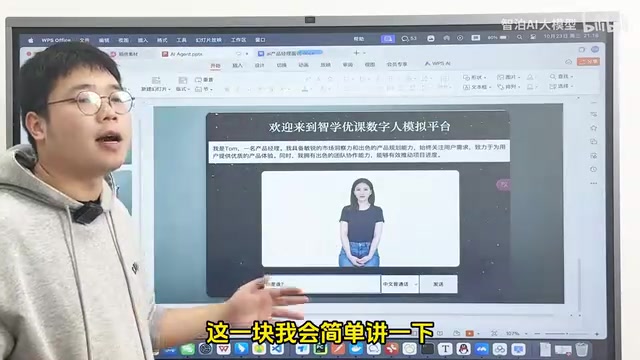
数字人模拟平台:项目整体概览
平台定位与设计理念
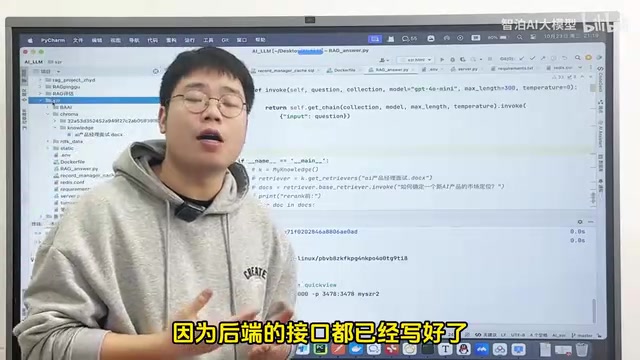
这个项目被定义为一个数字人模拟平台,而非单一的数字人应用。之所以称为"平台",是因为后端已经封装好了面向不同应用场景的接口——无论是直播带货、模拟面试,还是智能客服,都可以通过调用相应接口来实现。
对于有一定开发基础的同学来说,这个项目可以作为二次开发的起点。后端服务接口已经就绪,前端则保持了较高的灵活性,开发者可以根据自己的业务场景进行定制化开发。
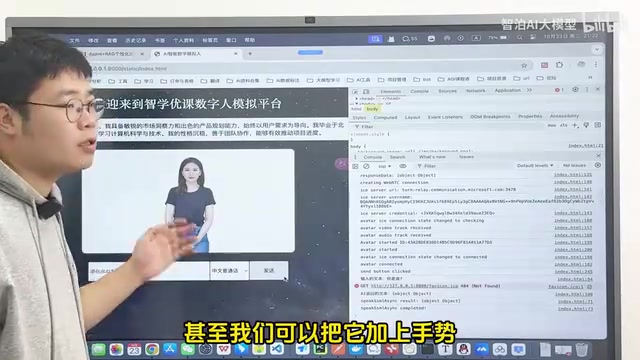
核心功能演示
在效果演示中,当用户向数字人提问"你是谁"时,系统会经过RAG检索流程,从知识库中提取相关信息,然后生成个性化的回复。数字人不仅能够以文字形式回答,还会通过虚拟形象进行语音播报,字幕同步显示在界面上。
虚拟形象支持通过企业级工具进行定制,包括2D/3D形象设计、手势动作等。出于隐私考虑,演示中使用的是平台原生的虚拟形象服务。
四大核心技术栈深度解析
整个AI数字人项目的技术架构可以拆解为四个核心模块,掌握这四个模块基本就能理解整个系统的运作方式。
Agent智能体:数字人的大脑
Agent是整个数字人的核心驱动。它负责理解用户意图、调度各个功能模块、生成最终回复。在这个项目中,Agent基于大语言模型(LLM)构建,具备多轮对话管理、意图识别和任务编排能力。
Agent(智能体)概念源自人工智能领域的经典理论,指能够自主感知环境、做出决策并执行动作的软件实体。在大模型时代,Agent的能力得到了质的飞跃——以LangChain、AutoGPT等框架为代表,现代AI Agent不再是简单的规则引擎,而是具备了推理、规划、工具调用和自我反思的能力。典型的Agent架构包括感知层(接收用户输入)、规划层(任务分解与策略选择)、执行层(调用外部工具或API)和记忆层(维护对话历史与上下文)。在数字人场景中,Agent需要同时协调语音识别、知识检索、语音合成等多个子系统,这对其任务编排能力提出了极高要求。
Agent的设计决定了数字人的"智商上限"——它不仅要能回答问题,还要能根据不同场景切换对话策略,比如在面试模拟场景中扮演面试官,在客服场景中提供专业解答。
RAG检索增强生成:让数字人拥有专业知识
RAG(Retrieval-Augmented Generation)是这个项目中最值得关注的技术亮点之一。项目中实现的RAG Answer模块大约有300行左右的工程化代码,这远超简单的Naive RAG或基础的Agentic RAG实现。
RAG由Meta(原Facebook)在2020年首次提出,其核心思想是将信息检索与文本生成相结合,解决大语言模型知识过时和幻觉(Hallucination)问题。所谓"幻觉",是指大模型在缺乏相关知识时,会自信地编造看似合理但实际错误的内容。RAG通过在生成前先检索相关文档,为模型提供事实依据,从而大幅降低幻觉发生的概率。
RAG的技术演进经历了三个阶段:Naive RAG(简单的检索+生成拼接)、Advanced RAG(引入查询重写、重排序、混合检索等优化策略)和Modular RAG(将RAG流程模块化,支持灵活编排)。工程化的RAG系统通常包含文档解析、文本分块(Chunking)、向量嵌入(Embedding)、向量数据库存储、语义检索、结果重排序(Reranking)和上下文压缩等环节。300行的工程化代码意味着该项目在分块策略、检索算法和Prompt工程等方面做了大量优化,远非调用一个API那么简单。
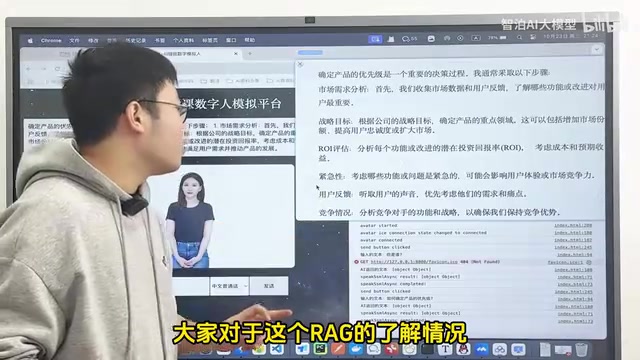
根据实际测试,这套RAG服务在不同类型的文件上都表现出色:
- 支持多种文件格式:PDF、Word文档、Markdown等
- 检索准确率高达90%以上:经过多轮测试验证
- 高度还原原文内容:对比RAG检索结果与原文档,关键语句几乎完全一致
- 具备泛化能力:不仅能精确匹配,还能对相关内容进行合理推理和扩展
以AI产品经理面试题为例,当用户询问"如何确定产品的优先级"时,RAG系统从知识库中精准检索到相关段落,生成的回答与原文档内容高度一致,同时又保持了回答的灵活性。
WebRTC实时通信:低延迟交互的关键
WebRTC是实现数字人实时交互的关键技术。它负责处理音视频流的传输,确保用户与数字人之间的对话能够实时、低延迟地进行。
WebRTC(Web Real-Time Communication)是由Google主导开发的开源项目,于2011年发布,已被W3C和IETF标准化。它允许浏览器之间直接进行点对点的音视频通信,无需安装插件。WebRTC的核心组件包括:MediaStream API(获取音视频流)、RTCPeerConnection(建立点对点连接、处理编解码和NAT穿透)和RTCDataChannel(传输任意数据)。其中,NAT穿透是WebRTC的一大技术难点——由于大多数设备位于路由器或防火墙之后,WebRTC需要借助STUN/TURN服务器来发现设备的公网地址并建立连接。
在数字人场景中,WebRTC面临的挑战尤为特殊——传统WebRTC主要处理双向实时通话,而数字人场景更偏向于服务端渲染推流模式,需要在服务端完成虚拟形象的实时渲染后,通过WebRTC将音视频流推送到客户端。端到端延迟通常需要控制在500毫秒以内,才能保证用户感受到自然流畅的交互体验。
在这个项目中,WebRTC服务端充当前端与后端之间的桥梁。它不仅要处理音频流(数字人的语音输出),还要管理视频流(虚拟形象的实时渲染),这对服务端的性能和稳定性提出了较高要求。
Docker容器化部署:一键启动所有服务
项目采用Docker进行容器化部署,这是现代微服务架构的标准实践。由于整个项目涉及多个服务组件(Agent服务、RAG服务、WebRTC服务、前端服务等),Docker Compose可以帮助开发者一键启动所有服务,大幅降低部署复杂度。
Docker是一种操作系统级别的虚拟化技术,通过容器(Container)将应用及其依赖环境打包在一起,实现"一次构建,到处运行"。与传统虚拟机相比,Docker容器共享宿主机的操作系统内核,启动速度更快(秒级 vs 分钟级),资源占用更少。Docker Compose则是Docker官方提供的多容器编排工具,通过一个YAML配置文件即可定义和管理多个服务容器的启动顺序、网络配置和数据卷挂载。在AI项目中,容器化部署尤为重要,因为不同服务可能依赖不同版本的Python、CUDA驱动或系统库,容器化可以彻底消除环境冲突问题。对于数字人这类多服务架构,Docker Compose还能自动处理服务间的网络通信和健康检查,确保Agent服务、RAG服务、WebRTC服务等按正确顺序启动并保持稳定运行。
考虑到项目文件较大,代码仓库托管在远程服务器上,需要通过特定渠道获取完整代码包。
AI数字人系统的技术架构与数据流
从架构层面来看,整个数字人系统的数据流大致如下:
- 用户输入 → 前端通过WebRTC捕获语音或文字输入
- 意图理解 → Agent接收输入,进行意图识别和任务规划
- 知识检索 → 如需外部知识,Agent调用RAG模块检索相关文档
- 回复生成 → LLM基于检索结果和对话上下文生成回复文本
- 语音合成 → 文本转语音(TTS)生成数字人的语音输出
- 形象驱动 → 虚拟形象根据语音内容同步口型和动作
- 实时传输 → 通过WebRTC将音视频流推送到前端
其中,语音合成(Text-to-Speech, TTS)技术经历了从拼接合成、参数合成到神经网络合成的演进。当前主流的神经网络TTS方案包括Tacotron系列、FastSpeech系列以及最新的VITS、Bark等端到端模型。在数字人场景中,TTS不仅要求语音自然流畅,还需要支持情感表达、语速控制和多语言切换。更关键的是,TTS的生成速度直接影响端到端延迟——流式TTS技术允许模型在生成部分音频后即开始播放,而非等待整段文本处理完毕,这对于实时交互场景至关重要。
虚拟形象驱动技术(Avatar Animation)则是数字人系统中最直观的表现层。其核心挑战在于口型同步(Lip Sync)和表情动作生成。主流方案分为两类:基于规则的驱动(将音素映射到预定义的口型动画)和基于深度学习的驱动(如Audio2Face、SadTalker等模型,直接从音频生成面部动画)。2D数字人通常基于Live2D等技术,通过少量参数控制面部变形;3D数字人则依赖骨骼动画和Blendshape技术,表现力更强但计算成本也更高。企业级数字人平台通常还支持手势动作库、身体姿态控制和场景切换等高级功能。
这个流程看似清晰,但每个环节都有大量的工程细节需要处理,比如如何优化RAG的检索精度、如何降低端到端延迟、如何保证虚拟形象的口型同步等。
哪些开发者适合学习这个项目?
这个AI数字人项目适合以下几类开发者:
- 想要系统学习AI Agent开发的同学:项目涵盖了Agent、RAG、部署等完整链路
- 对数字人技术感兴趣的开发者:可以了解数字人背后的技术全貌
- 有垂直领域应用需求的团队:可以基于项目进行二次开发,快速搭建行业数字人
- 想要提升全栈能力的AI工程师:项目涉及前后端、音视频、大模型等多个技术领域
总结:从学习到落地的实践路径
AI数字人已经不再是遥不可及的技术,通过合理的架构设计和成熟的工具链,个人开发者也能搭建出具备智能对话、知识检索和虚拟形象驱动能力的数字人系统。这个项目的核心价值在于它提供了一个可落地、可扩展的工程化方案,而非停留在概念层面。
对于想要深入学习的同学,建议按照 Agent → RAG → WebRTC → Docker部署的顺序逐步攻克,每个模块都值得深入研究。数字人技术的未来充满想象空间,而现在正是入场的好时机。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。