LangChain AI Agent实战:流式输出+并行工具调用完整教程
使用LangChain构建具备并行工具调用和流式输出的AI Agent聊天应用
本文详细介绍了基于LangChain和FastAPI构建AI Agent聊天应用的完整后端实现。系统采用ReAct范式,支持工具调用、asyncio.gather并行执行、SSE流式输出和结构化响应。重点讲解了token流式传输机制、异步队列通信、并行工具调用的实现,以及Agent Scratchpad消息排序等关键技术细节。
项目概览:我们要构建什么?
本文将带你深入了解如何使用 LangChain 构建一个完整的 AI Agent 聊天应用。这个应用不是简单的问答机器人,而是一个具备工具调用、并行执行、流式输出和结构化响应能力的智能对话系统。
LangChain 是目前最流行的 LLM 应用开发框架之一,其 Agent 模块基于 ReAct(Reasoning + Acting)范式构建——模型在每一步先推理(Thought),再决定行动(Action),最后观察结果(Observation),循环迭代直到得出最终答案。这种架构让 LLM 从单纯的文本生成器变成了能够使用外部工具的自主决策系统,是当前构建智能助手类应用的主流方案。
用户可以向这个 Agent 提出各种复杂问题,比如查询天气、搜索新闻、进行数学计算,Agent 会自动选择合适的工具并行处理,然后以流式方式返回结构化的结果。整个项目分为 FastAPI 后端和前端界面两部分,本文重点聚焦后端 API 的实现逻辑。
项目环境搭建
依赖管理与环境配置
项目使用 uv 作为 Python 包管理工具,搭建流程非常简洁:
# 安装 uv(Mac)
brew install uv
# 安装 Python 并创建虚拟环境
uv python install
uv venv
source .venv/bin/activate
# 安装所有依赖
uv sync
环境变量方面,需要配置三个 API Key:OpenAI API Key、LangChain API Key 和 SerpAPI API Key。将 .env.example 复制为 .env 文件并填入对应的密钥即可。
启动 FastAPI 服务
进入项目的 09-capstone/api 目录后,运行以下命令启动 FastAPI 服务:
uv run uvicorn main:app --reload
服务启动后可通过 localhost:8000/docs 访问 API 文档,其中包含一个核心的 /invoke POST 端点。
API 核心架构:流式响应机制
Token Generator 的工作原理
API 的核心在于 token_generator 函数,它负责将 Agent 产生的每个 token 进行后处理并以流的形式返回给前端。整个流式响应通过 FastAPI 的 StreamingResponse 对象实现,媒体类型设置为 text/event-stream。
text/event-stream 是 Server-Sent Events(SSE)协议的 MIME 类型。SSE 是一种服务器向客户端单向推送数据的 HTTP 标准,相比 WebSocket 更轻量,无需握手协议,天然支持断线重连。在 AI 聊天场景中,SSE 是流式输出 token 的主流方案——每生成一个 token 就立即推送,用户无需等待完整响应,体验更接近真实对话。ChatGPT、Claude 等主流 AI 产品的流式输出均基于此协议实现。
在 token 流中,系统插入了特殊的控制标记来帮助前端区分不同类型的内容:
- 步骤开始/结束标记:标识一个工具调用步骤的边界
- 步骤名称标记:标识当前使用的工具名称
- 参数流:工具调用的具体参数,逐 token 流式传输
- 最终答案标记:当前端检测到
final_answer步骤名时,切换为常规聊天输出模式
async def token_generator():
async for token in streamer.aiter():
if is_end_of_step(token):
yield end_of_step_token
elif tool_calls := get_tool_calls(token):
if tool_name:
yield f"{start_step}{tool_name}{end_step_name}"
elif function_args:
yield function_args # 直接流式传输参数
异步执行与队列通信
整个 API 采用异步架构。Agent 的执行通过 asyncio.create_task 创建异步任务,token 通过 QueueCallbackHandler 的队列机制在 Agent 执行和流式输出之间传递。
Callback Handler 是 LangChain 提供的钩子系统,允许开发者在模型生成、工具调用等关键节点注入自定义逻辑。QueueCallbackHandler 利用 asyncio.Queue 实现了生产者-消费者模式:Agent 执行线程作为生产者将 token 放入队列,token_generator 作为消费者从队列取出并通过 SSE 推送给客户端。这种解耦设计让 Agent 的执行逻辑与输出传输逻辑完全分离,互不阻塞——即使 Agent 正在等待某个工具的返回结果,已生成的 token 也能持续流向前端。
Agent 执行引擎深度解析
异步工具定义与 Coroutine
项目中所有工具都被定义为异步函数(async def),这是一个关键的设计决策。对于 SerpAPI 这样涉及网络请求的工具,异步是必要的——在等待 API 响应时,程序可以去处理其他任务。而对于 final_answer 或计算器工具,虽然不严格需要异步,但统一使用异步定义可以简化代码:
# 统一使用 tool.coroutine 而非混合 tool.func 和 tool.coroutine
name_to_tool_func = {
tool.name: tool.coroutine for tool in tools
}
当工具定义为 async 时,LangChain 的 StructuredTool 会将函数放在 coroutine 属性而非 func 属性中。这意味着所有工具调用都需要 await,但代码一致性大大提高。值得一提的是,StructuredTool 同时依赖 Pydantic 来定义工具的输入参数结构——通过 Pydantic BaseModel 描述每个参数的类型和含义,LLM 才能准确知道调用工具时应该传入什么格式的参数,从而大幅减少工具调用错误。
用 asyncio.gather 实现并行工具调用
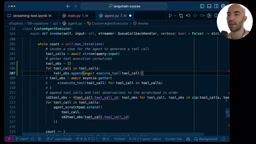
并行工具调用是这个项目相比基础 Agent 的重要升级。核心实现依赖 asyncio.gather:
# 顺序执行(慢)
for tool_call in tool_calls:
result = await execute_tool(tool_call)
# 并行执行(快)
tool_obs = await asyncio.gather(
*[execute_tool(tc) for tc in tool_calls]
)
需要理解的是,Python 的 asyncio 是基于单线程事件循环的协程并发模型,asyncio.gather 并非真正的 CPU 并行,而是 I/O 并发——当一个协程在等待网络响应时,事件循环切换执行其他协程。对于 SerpAPI 这类网络密集型任务,这种方式能将多个串行等待变为重叠等待,总耗时接近单次最慢请求的时间,而非所有请求时间之和。当 Agent 需要同时查询多个城市的天气或搜索多个关键词时,并行执行能显著缩短响应时间。
Agent Scratchpad 的消息排序陷阱
在并行工具调用场景下,有一个容易被忽视的关键细节:Agent Scratchpad 中消息的排列顺序。
Agent Scratchpad 是 LLM 在多轮工具调用中维护推理上下文的消息列表。OpenAI 的 Tool Calling 协议要求消息严格遵循 assistant message → tool message 的配对顺序,且每个 tool message 必须通过 tool_call_id 与对应的 assistant message 中的工具调用请求精确匹配。如果简单地将所有 AI Message 和 Tool Message 分别追加,会导致如下错误顺序:
❌ AI Message (call_id=A) → AI Message (call_id=B) → Tool Message (call_id=A) → Tool Message (call_id=B)
这种顺序违反了 OpenAI API 的消息格式规范,会导致 Agent 在下一轮迭代时挂起或返回错误。正确的做法是确保每个 AI Message 紧跟其对应的 Tool Message:
✅ AI Message (call_id=A) → Tool Message (call_id=A) → AI Message (call_id=B) → Tool Message (call_id=B)
项目通过将 tool_call_id 映射到对应的 tool observation,然后按顺序交替排列来解决这个问题。
SerpAPI 异步工具的构建
从同步到异步的改造
LangChain 内置的 SerpAPI 工
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。