Coze工作流实战:AI一键生成产品宣传视频完整教程
前言
在短视频营销时代,产品宣传视频的需求量巨大,但传统制作流程耗时耗力。如果能通过AI智能体一键生成产品宣传视频,将极大提升效率。本文将详细拆解一个基于Coze工作流的产品宣传视频生成方案,整合阿里HappyHours(快乐码)视频模型与即梦图片生成能力,实现从产品图到完整宣传视频的全自动化流程。
Coze(扣子)是字节跳动推出的AI应用开发平台,允许用户通过可视化的工作流编排方式构建复杂的AI应用。其核心理念是将大模型能力、插件工具和逻辑控制节点以低代码方式串联,降低AI应用的开发门槛。工作流中的每个节点可以是大模型调用、API请求、逻辑判断或数据处理,节点之间通过变量传递数据,形成完整的自动化流水线。这种架构使得非技术人员也能构建出媲美专业开发的AI应用。
整个工作流仅需输入三个参数——产品名称、产品图片和视频时长,即可在约5分钟内生成一段连贯的产品宣传视频,支持任意时长,适用于任何产品品类。
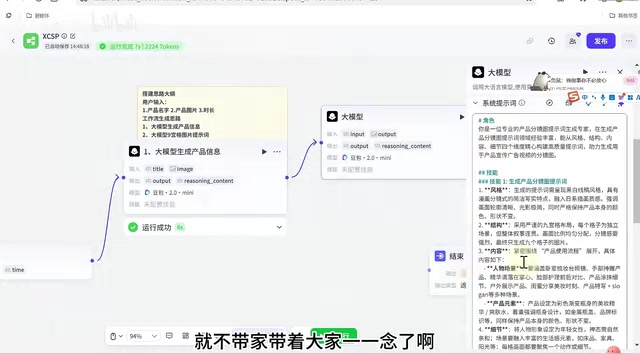
Coze工作流整体架构:12个节点的完整链路
这个Coze工作流一共包含12个节点,核心逻辑可以归纳为以下几个阶段:
- 用户输入:产品名称(title)、产品图片(image)、视频时长(time)
- 产品信息提取:大模型识别产品图片,生成产品描述
- 九宫格分镜提示词生成:大模型根据产品信息生成九宫格分镜描述
- 图片格式转换 + 九宫格图生成:调用即梦生成分镜参考图
- 视频提示词生成:大模型根据分镜图和时长生成视频prompt
- 视频生成 + 循环查询:调用HappyHours生成视频并轮询获取结果
- 结果处理与输出:去空处理后返回最终视频链接
这个设计的精妙之处在于,通过九宫格分镜图来保证视频的连贯性和画面转场质量,而不是直接用文字描述去生成视频,大幅提升了成片效果。九宫格分镜是一种将视频内容拆解为9个关键画面的创意方法,源自传统影视行业的分镜脚本(Storyboard)概念。在AI视频生成场景中,直接用纯文字描述往往导致画面跳跃、风格不统一。而通过先生成一张包含9个关键帧的参考图,再让视频模型基于这些视觉锚点生成内容,能有效约束画面风格一致性和叙事连贯性。这本质上是一种"视觉提示"策略,比纯文本提示能传递更丰富的构图、色彩和氛围信息。
第一阶段:产品信息提取与分镜生成
节点1:大模型提取产品信息
开始节点配置三个输入参数后,第一个大模型节点负责识别产品图片并提取关键信息。以下是关键配置要点:
- 模型选择:必须选择带图片理解功能的模型,推荐使用豆包2.0 Mini
- 输入配置:通过引用变量将产品名称传入文本输入,产品图片传入视觉理解接口
- 系统提示词:将大模型定义为"专业且极具创意的产品宣传专家",赋予其卖点提炼等技能
- 异常处理:设置300秒超时,配置重试一次并指定备选模型(如豆包2.0 Lite)
视觉理解(Vision Understanding)是多模态大模型的核心能力之一,指模型能够接收图片输入并理解其中的视觉内容。豆包2.0 Mini等支持视觉理解的模型,底层通常采用Vision Transformer(ViT)架构将图片编码为token序列,再与文本token一起送入语言模型进行联合推理。这使得模型能够描述图片内容、识别物体属性、理解空间关系等。在本工作流中,这一能力被用于自动提取产品的颜色、材质、款式等关键卖点信息,替代了人工撰写产品描述的环节。
用户提示词中需要使用{{变量名}}的语法引入参数,并标注说明(如"产品名字"、"产品图片"),帮助大模型理解输入含义。实测中,该节点约7秒即可完成产品信息提取,能准确识别出服装的花色、版型等细节。
节点2:生成九宫格分镜提示词
第二个大模型节点是整个Coze工作流的核心创意环节。它接收节点1输出的产品信息和原始产品图片,生成九宫格分镜的详细描述。
系统提示词将其定义为"专业的产品分析提示词生成专家",包含大量关于镜头语言、画面构图、转场设计的细节要求。这些提示词内容较长,但正是这些精细的指令保证了最终视频的专业质感。在传统影视制作中,分镜脚本通常由导演和分镜师协作完成,需要考虑景别(特写、中景、全景)、运镜方式(推拉摇移)、画面节奏等专业要素。这里通过精心设计的系统提示词,让大模型扮演了分镜师的角色,将这些专业知识编码进生成的分镜描述中。
第二阶段:即梦生图与格式处理
节点3-4:格式转换与即梦图片生成
在调用图片生成模型之前,需要先对参考图进行格式转换。这是因为即梦、GPT等生图模型要求输入图片为ArrayString(字符串数组)类型。教程中使用了"减硬小助手"插件的StringToList功能完成转换。ArrayString是一种将图片URL封装为JSON数组的数据结构(如["https://example.com/image.jpg"]),这种格式设计是为了支持多图输入场景,即使只有一张参考图也需要遵循这一规范。
图片生成节点使用即梦(Jimeng)的"根据提示词生成图片"功能,关键配置包括:
- API Key:每个用户需要使用自己的算力Key
- 提示词:引用节点2生成的九宫格分镜描述
- 参考图:引用节点3转换后的图片格式
- 模型版本:推荐使用图片4.0,效果较好
- 图片比例:建议选择1:1
即梦是字节跳动旗下的AI图片生成工具,基于自研的扩散模型(Diffusion Model)技术,支持文生图、图生图等多种模式。扩散模型的工作原理是先向图片逐步添加噪声直至变为纯噪声,再学习逆向去噪过程来生成新图片。即梦4.0版本在细节还原、风格一致性和中文语义理解方面有显著提升,特别适合需要保持产品外观准确性的商业场景。通过同时输入文本提示词和参考图片,模型能够在保持产品视觉特征的同时,按照分镜描述生成符合要求的画面构图。
生成的九宫格分镜图将作为后续视频生成的画面参考,确保视频中每个镜头的内容和转场都有据可依。
第三阶段:HappyHours视频生成与结果获取
节点5:视频提示词创作
第三个大模型节点负责将九宫格分镜图转化为AI视频生成的专业提示词。它接收视频时长和九宫格图片URL,输出精确到每一秒镜头语言的视频描述。
系统提示词中需要通过{{time}}变量引入时长参数,确保生成的提示词与目标时长匹配。引用成功后变量会显示为高亮绿色,这是一个重要的验证标志。视频提示词的质量直接决定了最终视频的表现力,好的视频提示词需要包含时间轴标注(如"0-2秒")、镜头运动描述(如"缓慢推进")、主体动作(如"模特转身展示")和环境氛围(如"柔和的自然光")等多维度信息。
节点6:HappyHours视频生成调用
调用阿里快乐码(HappyHours)视频生成插件,配置项包括:
- API Key:使用个人算力凭证
- 提示词:引用节点5的视频提示词
- 时长:引用开始节点的时间参数
- 参考图:引用节点3处理后的图片(ArrayString格式)
- 视频比例:手机端建议9:16
- 分辨率:720P用于测试,正式使用可提高
HappyHours是阿里巴巴推出的AI视频生成模型,支持通过文本提示词和参考图片生成高质量短视频。该模型采用异步生成架构——用户提交生成请求后获得一个任务ID,视频在云端渲染完成后通过ID查询获取结果。这种设计是因为视频生成涉及大量GPU计算资源,需要对数百帧画面进行逐帧渲染和时序一致性处理,单次生成可能需要数分钟,异步模式可以避免HTTP连接长时间占用和超时问题。模型支持自定义时长、分辨率和画面比例,适用于电商、社交媒体等多种场景。
节点7-8:循环查询与去空处理
视频生成通常需要5-6分钟,不能让程序一直阻塞等待。解决方案是使用无限循环节点配合定时器进行轮询:
- 通过任务ID查询视频生成状态
- 使用选择器判断URL是否为空
- 若为空(未完成),等待60秒后继续循环
- 若不为空(已完成),终止循环并输出结果
轮询(Polling)是处理异步任务的经典模式之一。在分布式系统中,处理耗时任务通常有三种方案:同步阻塞等待、WebSocket/SSE推送通知、以及客户端主动轮询。轮询的优势在于实现简单、无需维护长连接、对服务端压力可控。其代价是存在一定的延迟(最多等待一个轮询间隔)和少量无效请求。在Coze工作流中,60秒的轮询间隔是一个合理的平衡点——既不会产生过多无效请求,又能在视频生成完成后较快获取结果。
由于前几次查询返回的都是空值,最终需要使用"列表去空数据处理"节点过滤掉无效结果,只保留真实的视频链接。
实测效果与优化建议
整个Coze工作流实测运行时间约4分35秒,生成的10秒产品宣传视频在以下方面表现良好:
- 剧情连贯性:九宫格分镜设计保证了画面过渡自然
- 模特肢体语言:动作表现较为自然流畅
- 产品还原度:产品在视频中基本没有变形
不过也存在一些可优化的地方,比如视频结尾的文字可能出现瑕疵,可以通过在提示词中增加限制条件来改善。当前AI视频生成模型在文字渲染方面普遍存在短板,这是因为扩散模型对文字的像素级精确排列缺乏足够的约束能力,未来随着模型架构的改进(如引入专门的文字渲染模块),这一问题有望得到解决。
实用建议:
- 视频时长建议设置10-12秒,这是产品宣传视频的最佳时长区间(研究表明短视频平台用户的平均注意力窗口约为8-15秒,10-12秒既能完整展示产品卖点,又不会因过长导致用户划走)
- 变量命名必须使用英文,不能使用中文(这是Coze平台的技术限制,变量名在底层作为JSON键值使用,中文可能导致编码问题)
- 每个节点搭建完成后建议单独测试,便于排查问题
- 节点命名要清晰,方便后续维护和调试
总结
这个Coze工作流方案展示了当前AI工具链整合的强大能力:用大模型做创意策划,用即梦做分镜图,用HappyHours做视频生成,再用循环逻辑处理异步任务。整个流程无需编程基础,通过可视化拖拽即可完成搭建。这种"AI编排AI"的范式代表了当前AI应用开发的重要趋势——单一模型难以完成复杂任务,但通过工作流将多个专精模型串联,每个模型负责自己最擅长的环节,就能实现远超单模型能力的复杂应用。
对于电商卖家、内容创作者和营销团队来说,这是一个极具实用价值的AI视频自动化方案,能够显著降低产品宣传视频的制作成本和时间投入。传统的产品宣传视频制作需要经历脚本撰写、模特拍摄、后期剪辑等环节,周期通常为3-7天,成本数千至数万元。而通过本方案,整个流程压缩至5分钟内完成,边际成本仅为API调用费用,特别适合SKU数量庞大、需要批量生产视频素材的电商场景。
核心要点
相关推荐
NestJS + LangChain:前端转型AI全栈架构实战指南
前端工程师如何转型AI全栈?本文详解NestJS + LangChain技术组合,涵盖TypeScript基础、AI Agent开发、本地模型部署、全栈架构整合及跨语言能力迁移,助你从界面开发者进化为AI全栈架构师。
用Codex开发完整小程序:从零到上线的全流程实战
详细记录使用OpenAI Codex从零开发微信小程序的完整流程,涵盖图片工具箱七大功能开发、会员体系搭建、微信支付对接,以及AI辅助开发的工程管理技巧和提示词策略。
OpenAI Codex深度解析:让编程像飞翔一样的AI开发工具
OpenAI Codex深度解析:让编程像飞翔一样的AI开发工具
深度解析OpenAI Codex如何重新定义编程体验。从开发者真实反馈到Time to Fly项目实战,全面剖析Codex在代码生成、上下文理解等方面的核心优势,以及AI编程工具的竞争格局与未来趋势。