Coze书单号工作流搭建教程:输入书名一键生成短视频
在Coze平台搭建AI工作流,自动生成书单号短视频素材。
本文介绍如何在Coze(扣子)平台搭建书单号AI自动化工作流。只需输入书名和作者,系统即可通过大模型提取书籍金句、生成配音、批量生成背景图、翻译文案并打包素材,最终输出完整的短视频内容。整个流程包含88个节点,但通过封装技术仅需手动搭建18个节点即可完成。
概述
书单号是当前抖音、小红书等短视频平台上非常热门的内容形式——通过推荐书籍配合精美画面和配音,既能输出有价值的内容,又能通过挂载购书链接实现变现。书单号的核心变现逻辑是「内容种草+购书链接」:在抖音平台,创作者可在视频中挂载抖音小店或第三方书店商品链接,按实际成交金额获得5%-20%的佣金;小红书则以图文笔记为主,通过品牌合作和带货实现收益。书单号账号通常需要每天更新1-3条视频才能维持算法推荐,这也是AI自动化工作流在此场景价值极高的根本原因。
但传统做法需要手动选书、摘录金句、录制配音、设计配图、剪辑成片,流程繁琐且耗时。本文将手把手教你在Coze(扣子)平台上搭建一个完整的书单号AI工作流——只需输入书名和作者,系统就能自动生成包含配音、背景图、字幕和音效的完整视频素材。
整个工作流实际包含约88个节点,但通过封装技术,你只需手动搭建18个节点即可完成全部配置。
Coze书单号工作流整体架构
关于Coze平台
Coze是字节跳动于2024年推出的AI应用开发平台,分为国内版(coze.cn)和国际版(coze.com)。它的核心定位是「无代码/低代码AI工作流搭建平台」,允许普通用户通过可视化拖拽方式将大语言模型、插件、知识库等能力组合成自动化流程。Coze的工作流功能类似于Zapier或Make(原Integromat)的自动化逻辑,但深度集成了AI能力,特别适合内容生产、数据处理等场景。平台提供免费版和个人进阶版,其中进阶版支持工作流导入/导出等高级功能——这在后续封装节点的使用环节至关重要。
核心流程
工作流的整体逻辑分为六个阶段:
- 输入阶段:书名、作者、封面图、账号昵称、图像API密钥
- 内容提取:通过大模型提取书籍经典语录
- 配音生成:开头配音 + 正文批量配音
- 背景图生成:根据文案生成分镜提示词,再批量生成配图
- 翻译处理:将中文文案翻译为英文(用于画面装饰)
- 素材打包:整合所有音频、视频、图片素材,输出最终成品
详细搭建步骤
第一步:创建工作流与配置开始节点
在浏览器地址栏输入 coze.cn,进入后在左侧找到「Coze编程」,点击资源库右上角添加工作流。
开始节点需要配置5个输入变量:
- 书名(String类型,必填)
- 作者(String类型)
- 封面(File/Image类型,注意不是String)
- 平台昵称(String类型,可设默认值)
- 图像API密钥(String类型,用于调用图片生成服务)
特别注意:封面变量一定要设置为Image类型,否则无法上传图片,只能填写链接。将图像API密钥作为运行时参数传入(而非硬编码在工作流中),既方便多人共用工作流模板,也能有效避免密钥泄露风险。
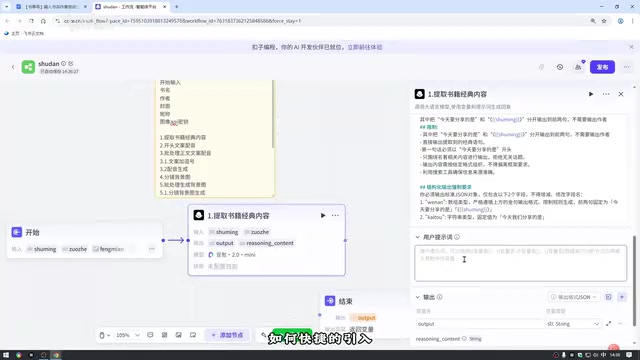
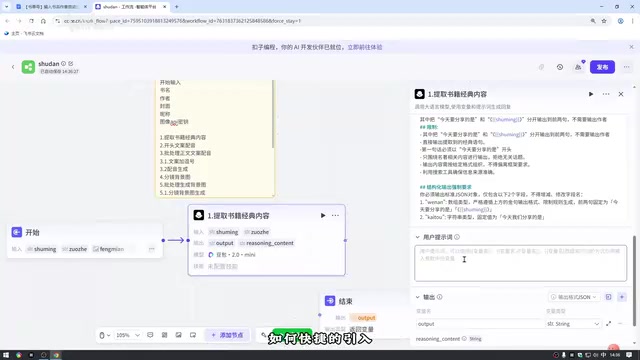
第二步:用大模型提取书籍经典内容
添加大模型节点,选择豆包2.0 Mini模型。豆包2.0 Mini是字节跳动豆包大模型系列的轻量化版本,在Coze平台上调用成本较低、响应速度较快,适合对输出质量要求适中但需要高频调用的场景。关键配置如下:
- 设置:将最大回复长度拉长,避免输出超时。「最大回复长度」参数直接影响模型能输出的token上限——若该值设置过低,模型会在输出中途被截断,导致JSON格式损坏或书摘内容不完整。
- 输入:引入开始节点的书名和作者
- 系统提示词:设定角色为书籍内容提取专家,要求结构化输出
- 用户提示词:必须引用输入变量(使用Shift+大括号快捷引入)
- 输出:配置「文案」(数组格式)和「开头」(String格式)两个输出字段
第三步:生成配音音频
开头配音:使用「语音合成」插件,输入为大模型输出的开头文案,选择有声阅读类音色。
正文批量配音:使用批处理节点(一次处理最多10个,建议调低避免报错)。
批处理节点的工作原理类似编程中的「并行for循环」——将一个数组拆分为多个独立任务,同时并发执行,最后将结果重新合并为数组输出。这与传统串行处理相比效率大幅提升,但也带来一个关键陷阱:批处理体内部的每个子任务是相互隔离的独立上下文,必须引用批处理体内当前迭代项的输出,而非外部节点的输出。
批处理体内包含:
- 文本处理(字符串拼接):在每句文案末尾加逗号,确保配音有自然停顿
- 语音合成:对加工后的文案进行配音
重要提醒:批处理体内引用数据时,一定要选择「批处理体输出的内容」,而非外部节点的输出。虽然内容看起来相同,但选错会导致所有子任务读取同一个固定值,生成结果全部一样。
第四步:批量生成分镜背景图
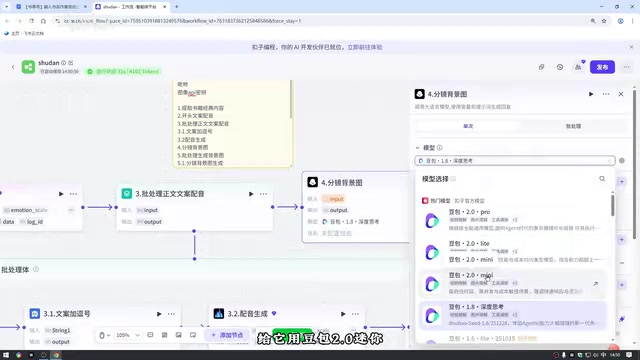
分两步完成:
- 生成提示词(大模型节点):根据文案数组生成7个贴近日常读书场景的配图描述,输出为数组格式
- 批量生图(批处理+图片生成插件):使用即梦API根据提示词生成图片,支持自定义尺寸(推荐4:3或9:16)
**即梦(Jimeng)**是字节跳动推出的AI图像和视频生成平台,其图片生成能力基于扩散模型(Diffusion Model)技术,支持通过文本提示词(Prompt)生成高质量图像。图片尺寸比例的选择直接影响最终视频在不同平台的展示效果:抖音全屏竖屏格式为9:16,小红书图文封面常用4:3或1:1。
第五步:文案翻译处理
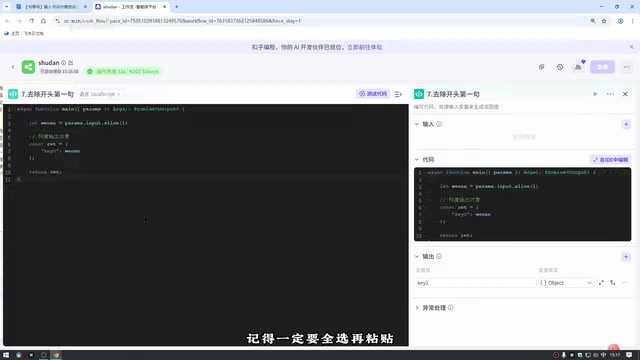
去除第一句话:通过代码节点去除文案数组的第一项(因为开头语已单独处理)。代码逻辑简单,输入数组输出去除首项后的新数组。
开头和书名翻译:大模型节点,关闭深度思考以提升速度。「深度思考」模式(类似OpenAI的o1系列推理模型)会让模型在回答前进行链式推理,虽然能提升复杂问题的准确性,但会显著增加响应时间——对翻译这类相对简单的任务而言得不偿失,关闭后可
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。