CrewAI+FastAPI搭建多Agent协作应用实战指南
基于CrewAI框架搭建多Agent协作系统并封装为FastAPI服务的实战指南
本文详细介绍了如何使用CrewAI框架构建多Agent协作系统,解析了Agent、Task、Process、Crew四个核心概念,并通过研究报告生成的实战案例,展示了从定义Agent角色到FastAPI服务封装的完整流程。项目支持GPT、国产大模型(One API转发)和本地Ollama三种模型接入方式,实测对比显示GPT-4o-mini效果最佳,本地7B模型表现不足。
前言
在AI Agent开发领域,如何让多个具有不同角色和技能的Agent协同工作,一直是一个核心课题。多Agent系统(Multi-Agent System, MAS)是人工智能领域的经典研究方向,其核心思想是将复杂问题分解为多个子任务,由具有不同专长的智能体协同完成。在大语言模型兴起之前,MAS主要应用于机器人控制、分布式计算等领域。随着GPT-4等强大LLM的出现,基于LLM的Agent获得了自然语言理解、推理和工具调用能力,使得构建真正意义上的"智能"多Agent系统成为可能。CrewAI、AutoGen、LangGraph等框架正是这一趋势下的产物,而CrewAI正是为解决这一问题而生的框架——它允许开发者定义多个Agent,为它们分配不同的角色、目标和任务,最终通过协作完成复杂的工作流程。
本文将基于一个完整的实战案例,详细介绍如何使用CrewAI搭建多Agent协作系统,并结合FastAPI将其封装为可对外提供的API服务。整个方案支持GPT、国产大模型(通义千问)以及本地开源模型(Ollama)三种接入模式,具有很强的实用性和可扩展性。
CrewAI核心概念解析
要用好CrewAI,首先需要理解它的四个核心概念:Agent、Task、Process和Crew。
Agent:团队中的角色
Agent是CrewAI中的自主可控单元,可以类比为团队中的一名成员。每个Agent拥有三个关键属性:
- 角色(Role):Agent在团队中的功能定位,如"数据研究员"或"报告分析师"
- 目标(Goal):Agent需要实现的具体目标
- 背景故事(Backstory):为Agent提供上下文信息,帮助它更好地理解自己的定位
在底层实现上,这三个属性会被拼接成系统提示词(System Prompt)注入到大模型的对话上下文中,从而"塑造"Agent的行为风格和专业倾向。这也是为什么背景故事的质量会直接影响Agent的输出效果——越详细、越具体的角色设定,往往能让模型产生更符合预期的输出。
Task:具体的任务单元
Task是分配给Agent的具体工作,包含任务描述、期望输出、分配的Agent以及可用工具列表等属性。一个关键特性是,Task支持上下文传递——前一个Task的输出可以作为下一个Task的输入,这为构建链式工作流提供了基础。
Process:任务协调机制
Process负责协调Agent执行任务,类似于项目经理的角色。CrewAI提供两种执行机制:
- 顺序流程(Sequential):任务按照预定顺序依次执行,前一个任务的输出作为后一个任务的上下文
- 分层流程(Hierarchical):指定一个管理者Agent负责监督任务分配和执行,根据各Agent的能力动态分配任务
分层流程在底层借鉴了经典的"规划-执行"(Plan-and-Execute)Agent架构思想:管理者Agent首先对整体目标进行任务分解和规划,再将子任务动态分配给最合适的执行者Agent,最后汇总结果。这种模式特别适合任务边界不清晰、需要动态调整执行策略的复杂场景。
Crew:协作的整体
一个Crew代表一组协作完成任务的Agent集合,它将Agent列表、Task列表和Process策略组合在一起,定义了整体的工作流程。
开发环境与大模型配置
三种大模型接入方案
本项目支持三种大模型接入方式,开发者可根据实际需求灵活选择:
方案一:GPT大模型(代理方式)
通过API代理访问OpenAI的GPT系列模型,如GPT-4o-mini。这种方式响应速度快,效果稳定,适合对输出质量要求较高的场景。
方案二:国产大模型(One API转发)
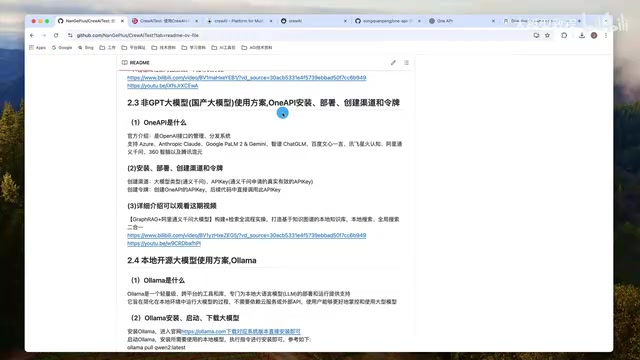
One API是一个开源的OpenAI接口管理与分发系统,其核心原理是将各大模型厂商的API统一适配为OpenAI格式的接口规范。由于OpenAI的API已成为行业事实标准,大多数AI开发框架(包括CrewAI)都原生支持OpenAI接口,因此通过One API这一中间层,开发者无需修改任何业务代码即可接入通义千问、文心一言、智谱GLM等国产模型。这种适配层设计在工程实践中极具价值,尤其适合需要多模型对比测试或在不同供应商之间灵活切换的场景。部署方式也很简单——从GitHub下载对应系统的编译包,执行即可启动服务,默认运行在3000端口。
方案三:本地开源模型(Ollama)
Ollama通过对GGUF(GPT-Generated Unified Format)等量化模型格式的支持,使得在消费级硬件上运行大模型成为可能。量化技术将模型权重从FP32/FP16压缩为INT4/INT8等低精度格式,可将内存占用降低50%-75%,代价是轻微的精度损失。以Llama 3.1 7B为例,量化后仅需约4-5GB显存即可运行。Ollama还内置了与OpenAI兼容的REST API(默认端口11434),这使得CrewAI等框架可以直接通过设置OPENAI_BASE_URL环境变量无缝接入本地模型,无需额外的适配代码。Ollama是一个轻量级跨平台工具,安装后通过简单的命令行即可下载和启动模型,无需依赖外部API,适合对数据隐私有要求的场景。
环境搭建要点
开发环境需要Anaconda(提供Python虚拟环境管理)和PyCharm(集成开发环境)。项目使用Python 3.11版本,核心依赖包括crewai、crewai-tools、fastapi等。
实战案例:研究报告生成系统
案例架构设计
本案例基于CrewAI官方入门示例进行扩展,核心功能是:用户输入一个主题(Topic),系统自动完成信息研究和报告撰写两个阶段的工作。
系统定义了两个Agent:
| Agent | 角色 | 职责 |
|---|---|---|
| 研究员 | 高级数据研究员 | 探索主题的前沿发展,找出10个最相关的要点 |
| 报告分析师 | 报告撰写专家 | 将研究结果扩展为完整的分析报告 |
对应的两个Task按顺序执行:研究任务的输出作为报告任务的输入上下文,形成完整的工作链。
Crew核心代码解析
Crew的实现封装在一个类中,通过装饰器模式定义Agent和Task。CrewAI使用Python装饰器(Decorator)模式来定义Agent和Task,这是一种典型的声明式编程风格。@agent、@task、@crew等装饰器本质上是对方法进行元编程标记,框架在运行时通过反射机制自动收集这些标记的方法,构建Agent列表和Task执行图。这种设计模式的优势在于代码结构清晰、职责分明,同时框架可以在幕后处理依赖注入、执行顺序管理等复杂逻辑,开发者只需专注于业务逻辑的定义。类似的模式也广泛应用于FastAPI的路由定义、pytest的测试发现等场景。
@agent
def research(self) -> Agent:
# 从agents.yaml加载配置,创建研究员Agent
return Agent(config=self.agents_config['research'], verbose=True)
@agent
def reporting_analyst(self) -> Agent:
# 创建报告分析师Agent
return Agent(config=self.agents_config['reporting_analyst'], verbose=True)
@task
def research_task(self) -> Task:
return Task(config=self.tasks_config['research_task'])
@crew
def crew(self) -> Crew:
# 将Agent和Task组合,使用顺序执行流程
return Crew(agents=self.agents, tasks=self.tasks, process=Process.sequential)
Agent和Task的具体参数通过YAML配置文件管理,包括角色描述、目标、背景故事、任务描述和期望输出等,实现了配置与代码的分离。
FastAPI服务封装
将CrewAI封装为API服务是本案例的一大亮点。核心逻辑如下:
- 服务启动时:根据配置的模型类型(OpenAI/One API/Ollama)初始化环境变量
- 接收POST请求:解析用户传入的Topic参数
- 执行Crew:调用
crew().kickoff(inputs={'topic': topic})启动多Agent协作 - 返回结果:支持流式和非流式两种响应方式
模型切换通过配置标志位实现,无需修改业务代码:
# 通过model_type标志切换大模型
if model_type == 'oneapi':
# 使用One API转发到国产模型
elif model_type == 'ollama':
# 使用本地Ollama模型
else:
# 默认使用OpenAI GPT模型
这种设计让开发者可以在不同大模型之间自由切换,而不需要改动任何业务逻辑代码。
三种模型效果对比
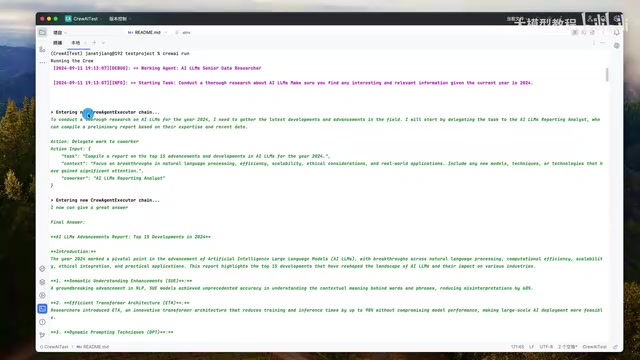
在相同的任务(研究AI/LLMs领域前沿发展)下,三种模型的表现差异明显:
| 模型 | 速度 | 输出质量 | 任务遵循度 |
|---|---|---|---|
| GPT-4o-mini | 最快 | 优秀,内容详实 | 严格按要求输出10条 |
| 通义千问Max | 较快 | 良好 | 输出了15条(超出要求) |
| Llama 3.1 (7B) | 较慢 | 一般 | 仅输出3条,效果不理想 |
这一实测结果揭示了大模型的一个核心能力维度——指令遵循(Instruction Following)。研究表明,模型的指令遵循能力与参数规模呈正相关,但并非线性关系。经过RLHF(基于人类反馈的强化学习)或DPO(直接偏好优化)对齐训练的模型,即使参数量相对较小,也能表现出较强的指令遵循能力。7B参数的本地模型在复杂的多步骤指令场景下表现不佳,主要原因是其上下文理解能力和指令分解能力相对有限。从实测结果来看,GPT-4o-mini在速度和质量上表现最佳;通义千问Max整体可用但在指令遵循上稍有偏差;本地7B模型受限于参数规模和硬件资源,效果明显不足。如果使用本地模型,建议选择参数量在13B以上的版本,或尝试专门针对指令遵循优化的Qwen2等在中文场景表现更好的模型。
总结与建议
CrewAI为多Agent协作提供了一套清晰的抽象框架,配合FastAPI可以快速构建可部署的AI服务。在实际项目中,有几点值得注意:
- 模型选择至关重要:Agent的表现高度依赖底层大模型的能力,务必在正式使用前做充分的评估测试
- 配置与代码分离:利用YAML配置文件管理Agent和Task的参数,便于后续维护和调整
- 灵活的模型切换:通过One API等中间层统一接口,可以方便地在不同模型间切换对比
- Pipeline扩展:对于更复杂的场景,可以利用CrewAI的Pipeline功能将多个Crew串联或并行执行,构建更复杂的工作流
掌握了CrewAI的核心概念和FastAPI的服务封装方法后,你可以在此基础上扩展更多的Agent角色和任务类型,打造适合自身业务场景的多Agent协作应用。
核心要点
- CrewAI通过Agent、Task、Process、Crew四个核心概念构建多智能体协作系统,支持顺序和分层两种任务执行机制
- 项目支持GPT、国产大模型(通过One API转发)和本地开源模型(Ollama)三种接入方式,通过配置标志位实现无缝切换
- 结合FastAPI将CrewAI封装为API服务,支持流式和非流式响应,可对外提供标准化的HTTP接口
- 实测对比显示GPT-4o-mini效果最佳,通义千问Max可用但指令遵循稍有偏差,本地7B小模型受限于RLHF对齐程度和参数规模,效果明显不足
- 采用YAML配置文件管理Agent角色和Task参数,实现配置与代码分离,便于维护和扩展
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。