Cube Studio深度解析:腾讯开源一站式MLOps平台实战指南

腾讯音乐开源的Cube Studio是覆盖MLOps全流程的云原生一站式AI平台
Cube Studio是腾讯音乐开源的云原生一站式AI平台,覆盖从数据标注、在线开发、任务编排、分布式训练到推理部署的MLOps全流程。它深度支持大模型SFT/RLHF训练范式,集成vLLM等主流推理框架,兼容近十种分布式训练框架,并全面适配国产昇腾生态,适合有私有化大模型和信创需求的企业。
概述
在AI工程化落地的浪潮中,如何高效管理从数据标注、模型训练到推理部署的全流程,一直是企业面临的核心挑战。腾讯音乐开源的 Cube Studio 正是为解决这一痛点而生——它是一个基于云原生架构的一站式机器学习/深度学习/大模型AI平台,覆盖了MLOps算法链路的全流程,目前在GitHub上已获得近5000颗Star。
本文将从架构设计、核心功能、生态兼容性等维度,对Cube Studio进行全面解析,帮助你判断它是否适合你的团队和业务场景。
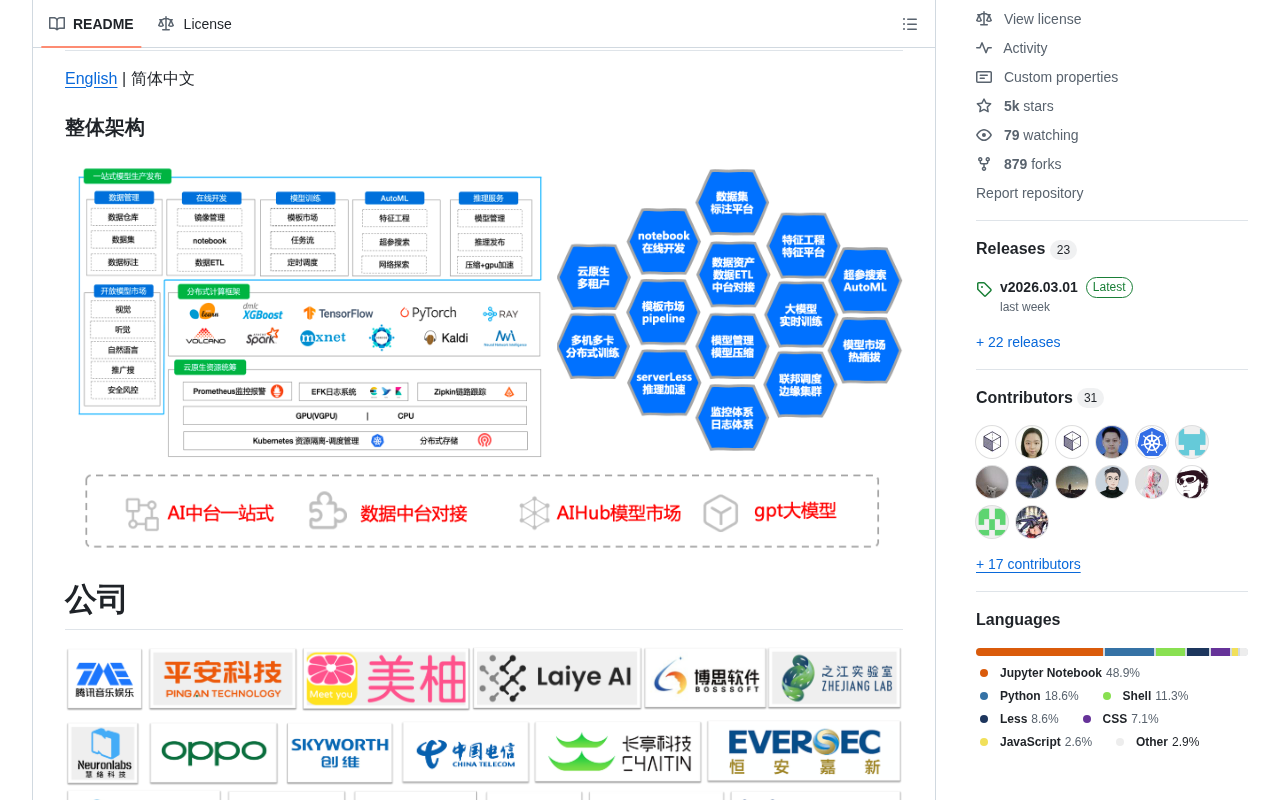
平台定位:MLOps全流程覆盖
Cube Studio的核心定位是一站式AI平台,这意味着它不只是一个训练框架或推理引擎,而是覆盖AI项目从0到1的完整生命周期。
要理解这一定位的价值,需要先了解MLOps的背景。MLOps(Machine Learning Operations)是将DevOps理念引入机器学习领域的工程实践体系,旨在解决模型从实验室到生产环境的"最后一公里"问题。传统AI开发中,数据科学家使用Jupyter Notebook完成实验,但模型上线后面临版本管理混乱、训练不可复现、数据管道断裂等问题。MLOps通过标准化的流水线、自动化的CI/CD机制和统一的元数据管理,将模型开发、训练、部署和监控串联为一个闭环。Google、Microsoft等公司在2020年前后开始大力推广MLOps概念,Gartner也将其列为关键技术趋势。
具体来说,Cube Studio涵盖以下关键环节:
- 数据标注:内置标注平台,支持自动化标注,大幅降低人工标注成本
- 在线开发:提供Notebook在线开发环境,开发者无需本地配置即可编写和调试代码
- 任务编排:支持拖拉拽式的任务流Pipeline编排,降低工作流构建门槛
- 模型训练:支持多机多卡分布式训练和超参搜索
- 推理部署:提供推理服务和VGPU虚拟化能力
- 边缘计算:将AI能力延伸到边缘侧
这种全链路覆盖的设计,让团队可以在一个统一的MLOps平台上完成所有AI相关工作,不用在多个工具之间来回切换——企业不再需要分别维护标注工具(如Label Studio)、实验管理工具(如MLflow)、调度系统(如Airflow)和部署平台(如Seldon),也避免了数据孤岛问题。
核心能力深度解读
大模型训练与微调
在大模型时代,Cube Studio紧跟技术趋势,提供了对DeepSeek等主流大模型的完整训练支持,包括:
- SFT微调(Supervised Fine-Tuning):在预训练模型基础上进行有监督微调,快速适配特定业务场景
- 奖励模型训练(Reward Model):为RLHF流程提供奖励模型的训练能力
- 强化学习训练(RLHF):完整支持基于人类反馈的强化学习训练流程
这三个环节构成了当前大模型对齐训练的标准范式,最早由OpenAI在InstructGPT论文中系统提出,后被广泛应用于ChatGPT、Claude等产品的训练过程。具体而言,SFT阶段使用人工编写的高质量指令-回答对对基座模型进行有监督微调,让模型学会遵循指令的基本能力;奖励模型阶段由人类标注员对模型生成的多个回答进行偏好排序,训练一个能自动评估回答质量的打分模型;RLHF阶段以奖励模型的评分作为奖励信号,通过PPO(Proximal Policy Optimization)等强化学习算法进一步优化语言模型的生成策略。这三个阶段环环相扣,每个阶段都需要不同的训练配置和计算资源,自行搭建完整管线通常需要数周的工程投入。
Cube Studio将它们整合在统一平台中,省去了自行搭建训练管线的大量工程工作,对于想要私有化部署和微调大模型的企业来说非常实用。
大模型推理服务
在推理侧,Cube Studio集成了当前最主流的大模型推理框架:
- vLLM:高性能LLM推理引擎,支持PagedAttention等先进技术,吞吐量表现优异
- Ollama:轻量级本地大模型运行框架,适合快速验证和小规模部署
- MindIE:华为昇腾生态的推理引擎,面向国产硬件场景
其中,vLLM是由UC Berkeley团队于2023年开源的推理引擎,其核心创新PagedAttention借鉴了操作系统虚拟内存的分页管理思想。在传统LLM推理中,KV Cache(键值缓存)的内存管理是最大瓶颈——每个请求的KV Cache需要预分配连续的GPU显存空间,由于生成文本长度不可预知,系统往往按最大长度预留内存,导致60%-80%的显存被浪费。PagedAttention将KV Cache切分为固定大小的"页"(Block),按需动态分配,不同请求的KV Cache页可以在物理显存中非连续存放,通过页表进行映射。这一设计将显存利用率提升至接近100%,使得相同硬件条件下的推理吞吐量提升2-4倍。此外,vLLM还支持Continuous Batching(连续批处理),允许新请求在不等待当前批次完成的情况下动态加入,进一步降低了请求排队延迟。
值得一提的是,平台支持多机推理,这对于部署超大规模模型(如数百亿参数级别)至关重要——单机显存无法容纳的模型可以通过多机协同完成推理,突破硬件瓶颈。
分布式训练框架生态
Cube Studio在分布式训练方面展现了极强的生态兼容性,支持的框架几乎覆盖了业界所有主流选择:
| 框架 | 适用场景 |
|---|---|
| PyTorch | 通用深度学习训练 |
| TensorFlow | 生产级深度学习 |
| MXNet | 灵活高效的深度学习 |
| DeepSpeed | 大模型高效训练 |
| PaddlePaddle | 百度生态 |
| ColossalAI | 大模型并行训练 |
| Horovod | 分布式训练通信 |
| Ray | 分布式计算与调度 |
| Volcano | Kubernetes批量调度 |
其中,DeepSpeed和ColossalAI是大模型时代最受关注的两个分布式训练框架。DeepSpeed由微软开发,其ZeRO(Zero Redundancy Optimizer)技术通过将优化器状态、梯度和模型参数分片到不同GPU上,将单卡显存需求降低数倍至数十倍,使得在消费级GPU上训练百亿参数模型成为可能。ColossalAI则由新加坡HPC-AI Tech团队开发,提供了更丰富的并行策略组合,包括数据并行、张量并行、流水线并行和序列并行的灵活混合。
这种广泛的框架支持意味着团队无需因平台限制而被迫更换技术栈。已有的训练代码可以较低成本迁移到Cube Studio上,迁移成本可控。
国产化与信创生态支持
在当前国产替代的大背景下,Cube Studio的一个重要亮点是全面适配国产硬件生态:
- 国产CPU/GPU:兼容国产处理器和图形处理器
- NPU昇腾生态:深度适配华为昇腾AI处理器,包括MindIE推理引擎的集成
- RDMA支持:支持远程直接内存访问,这对于多机分布式训练的通信效率至关重要
关于RDMA,这是一种允许计算机之间直接读写对方内存的网络通信技术,无需经过操作系统内核和CPU的介入。在大模型分布式训练场景中,多台机器之间需要频繁同步梯度数据,传统TCP/IP网络协议栈的每次数据传输都要经历用户态到内核态的多次拷贝和上下文切换,延迟通常在微秒到毫秒级别。而RDMA通过将网络协议栈卸载到专用网卡(如NVIDIA ConnectX系列InfiniBand网卡)上,实现了亚微秒级延迟和接近线速的带宽利用率。目前主流的RDMA实现包括InfiniBand(IB)、RoCE v2(基于以太网的RDMA)和iWARP三种。在千亿参数大模型训练中,节点间通信开销可能占总训练时间的30%-50%,RDMA的引入可以将通信开销降低一个数量级,是大规模分布式训练的基础设施标配。
对于需要满足信创合规要求的企业和机构来说,Cube Studio提供了一条从国际主流硬件平滑过渡到国产硬件的可行路径,不必从零搭建国产化AI基础设施。
算力管理与资源调度
Cube Studio不仅是一个AI开发平台,还具备算力租赁平台的能力。结合VGPU虚拟化技术,平台可以实现GPU资源的细粒度分配和共享,提升昂贵GPU资源的利用率。
VGPU(Virtual GPU)虚拟化技术是将一块物理GPU的计算资源和显存拆分为多个虚拟GPU实例的技术,使多个用户或任务可以共享同一块GPU。在AI平台场景中,VGPU的价值尤为突出:一块A100 80GB显卡的采购成本超过10万元,但许多开发调试任务实际只需要几GB显存和少量算力,如果为每个开发者独占分配整卡,资源浪费极为严重。NVIDIA官方提供了MIG(Multi-Instance GPU)和vGPU两种虚拟化方案,但前者仅支持A100/H100等高端卡且切分粒度有限,后者需要额外购买商业许可证。开源社区因此涌现了多种替代方案,如第四范式的VGPUScheduler(现为HAMi项目)等,通过在CUDA层进行拦截和资源限制,实现更灵活的GPU算力和显存切分。Cube Studio集成VGPU能力后,管理员可以将一块GPU按比例分配给不同任务,例如将一块80GB显存的A100拆分为多个虚拟实例,大幅提升集群整体GPU利用率。
在云原生架构的加持下,平台天然具备弹性伸缩能力,可以根据训练和推理任务的负载动态调整资源分配。对于GPU资源紧张的团队来说,这种精细化的算力管理能力直接关系到基础设施成本的控制。
附加能力:知识库与模型市场
除了核心的训练和推理能力,Cube Studio还提供了两个值得关注的附加功能:
- 私有知识库:支持构建企业私有知识库,结合大模型实现RAG(检索增强生成)等应用场景,让大模型能够基于企业内部数据进行问答
- AI模型市场:提供模型市场功能,便于团队内部的模型共享和复用,避免重复造轮子
其中,RAG(Retrieval-Augmented Generation,检索增强生成)是当前企业级大模型应用最主流的技术架构之一,由Meta AI在2020年首次提出。其核心思想是在大模型生成回答之前,先从外部知识库中检索与用户问题相关的文档片段,将这些片段作为上下文注入到提示词中,再由大模型基于检索到的信息生成回答。这种架构解决了大模型的两个核心痛点:一是知识时效性问题,预训练数据有截止日期,而RAG可以实时检索最新信息;二是幻觉问题,模型生成的内容有据可查,可追溯到具体的源文档。一个典型的RAG系统包含文档解析、文本分块(Chunking)、向量化(Embedding)、向量数据库存储(如Milvus、Chroma)、相似度检索和答案生成等环节。企业私有知识库是RAG最典型的应用场景——将内部文档、产品手册、技术规范等导入知识库,员工即可通过自然语言问答获取精准信息,同时确保敏感数据不外泄。
这两个功能虽然不是平台的核心卖点,但在实际企业落地中往往能带来不小的效率提升。
总结与展望
Cube Studio作为腾讯音乐开源的一站式AI平台,其最大价值在于将AI工程化的全流程整合在一个统一的云原生平台中。从数据标注到模型训练,从超参搜索到推理部署,从传统深度学习到大模型微调,平台的覆盖范围相当全面。
特别是在大模型时代,Cube Studio对DeepSeek等模型的SFT/RLHF训练支持,以及vLLM、Ollama等推理框架的集成,使其成为企业构建私有化大模型能力的有力工具。加上对国产昇腾生态的深度适配,该平台在信创场景下也具有较强的竞争力。
对于正在寻找开源AI平台解决方案的团队来说,Cube Studio值得深入评估——尤其是那些需要同时兼顾传统ML任务和大模型应用、且有国产化需求的企业。你可以从GitHub仓库开始,先在测试环境中跑通核心流程,再逐步评估是否适合生产环境落地。
核心要点
- Cube Studio是腾讯音乐开源的云原生一站式AI平台,覆盖数据标注、模型训练、推理部署等MLOps全流程
- 深度支持大模型训练范式,包括DeepSeek等模型的SFT微调、奖励模型和RLHF强化学习训练
- 集成vLLM、Ollama、MindIE等主流推理框架,支持多机多卡分布式推理
- 兼容PyTorch、DeepSpeed、ColossalAI等近十种分布式训练框架,生态兼容性极强
- 全面支持国产CPU/GPU/NPU昇腾生态和RDMA,满足信创场景需求
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。