Cube Studio深度解析:腾讯开源一站式云原生AI平台
腾讯音乐开源的云原生一站式MLOps AI平台Cube Studio全面解析
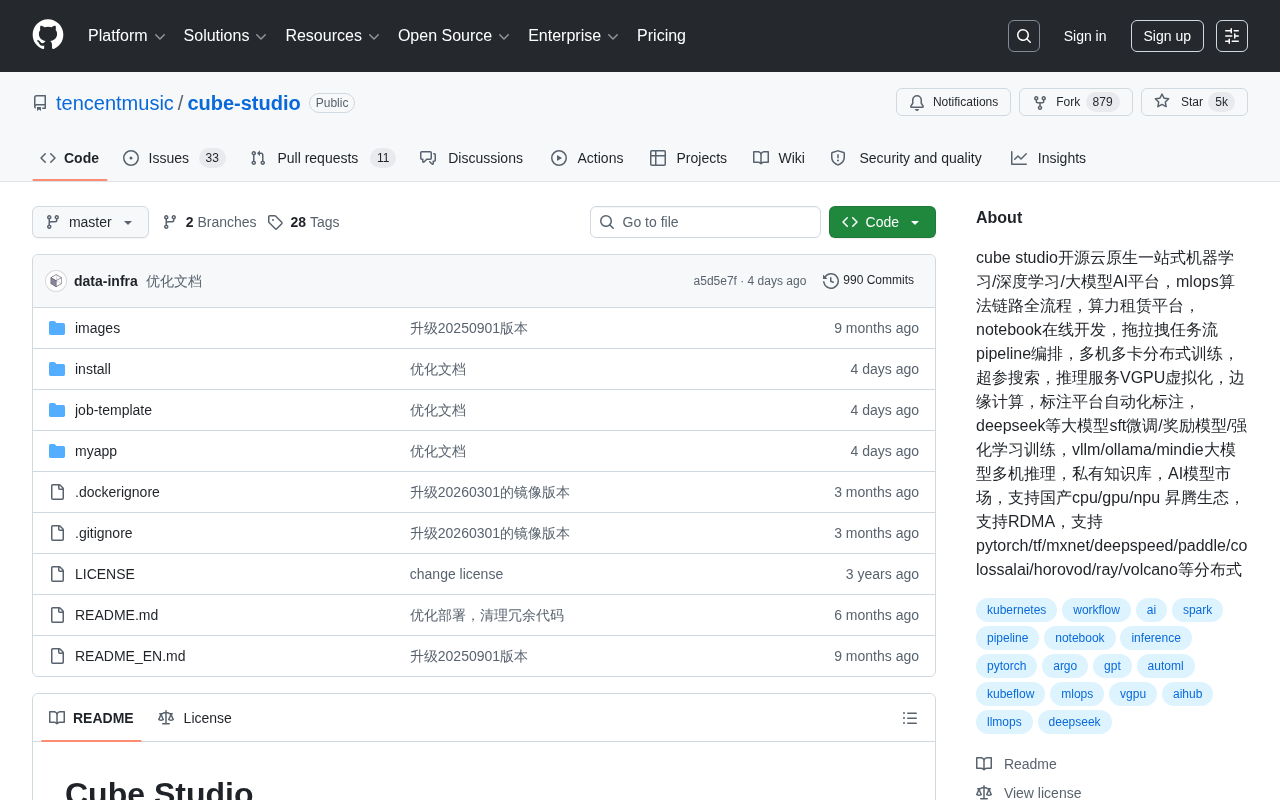
Cube Studio是腾讯音乐开源的云原生AI平台,覆盖数据标注、Notebook开发、分布式训练、大模型微调(SFT/RLHF)、推理部署及私有知识库(RAG)等MLOps全流程。平台支持主流深度学习框架和DeepSpeed等分布式训练工具,集成vLLM等推理引擎和VGPU虚拟化技术,并适配华为昇腾NPU等国产化硬件生态,是面向中大型团队的企业级AI基础设施方案。
概述
Cube Studio 是腾讯音乐(Tencent Music)开源的云原生一站式机器学习/深度学习/大模型 AI 平台,目前在 GitHub 上已获得近 5000 Star。该项目覆盖了从数据标注、模型训练到推理部署的 MLOps 全流程,同时支持国产化硬件生态,是目前国内开源社区中功能最为全面的 AI 平台之一。
MLOps(Machine Learning Operations)是将 DevOps 理念引入机器学习领域的工程实践体系,旨在解决模型从实验室到生产环境的"最后一公里"问题。传统的 AI 开发流程中,数据处理、模型训练、评估验证、部署上线往往使用不同的工具和平台,导致环节之间存在大量人工衔接和环境不一致的问题。MLOps 通过标准化流水线、自动化测试、持续集成/持续部署(CI/CD)等手段,将这些环节串联成可复现、可追溯的端到端工作流。Gartner 等分析机构多次指出,缺乏 MLOps 能力是企业 AI 项目从 PoC 走向规模化落地的最大瓶颈之一。
对于正在寻找企业级 AI 基础设施解决方案的团队来说,Cube Studio 提供了一个值得深入了解的选择。
Notebook 在线开发与任务流编排
Cube Studio 内置了 Notebook 在线开发环境,算法工程师无需配置本地环境即可直接编写和调试代码。Notebook 在线开发环境(通常基于 JupyterHub 或类似技术)是数据科学领域的标准交互式开发工具,它允许用户在浏览器中编写代码、运行实验并即时查看结果,代码、文档和可视化输出可以在同一个文档中混合呈现。在云原生场景下,Notebook 环境运行在 Kubernetes 集群中的容器内,用户无需在本地安装 CUDA 驱动、深度学习框架等复杂依赖,平台会自动分配 GPU 资源并挂载预配置的镜像环境,极大降低了"环境配置地狱"的问题。
更关键的是,平台提供了拖拉拽式的任务流 Pipeline 编排能力,用户可以通过可视化界面将数据处理、特征工程、模型训练、评估等环节串联成完整的工作流。这种编排本质上是将 MLOps 流程抽象为有向无环图(DAG),每个节点代表一个独立的计算任务(如数据清洗、特征提取、模型训练),节点之间的边定义了数据依赖和执行顺序。这种模式借鉴了 Apache Airflow、Kubeflow Pipelines 等成熟的工作流引擎设计理念,相比纯代码定义的流水线,可视化编排让非基础设施背景的算法工程师也能理解和管理复杂的多步骤训练流程,同时平台可以自动处理任务调度、失败重试、资源分配等底层逻辑。
这种低代码化的编排方式大幅降低了 MLOps 流程的搭建门槛,即使没有基础设施背景的算法人员也能快速构建端到端的训练链路。
分布式训练与超参搜索
在模型训练层面,Cube Studio 的支持范围相当广泛。平台原生支持多机多卡分布式训练,兼容的框架涵盖了主流的 PyTorch、TensorFlow、MXNet,以及近年来在大模型训练中广泛使用的 DeepSpeed、ColossalAI、Horovod 等。此外还支持 PaddlePaddle、Ray、Volcano 等分布式调度框架。
分布式训练是大规模模型训练的核心技术,其基本思路是将计算任务分散到多台机器的多块 GPU 上并行执行。PyTorch 的 DistributedDataParallel(DDP)和 TensorFlow 的 MirroredStrategy 是最基础的数据并行方案。DeepSpeed 由微软开发,以 ZeRO(Zero Redundancy Optimizer)技术著称,能够将优化器状态、梯度和参数分片存储在不同 GPU 上,大幅降低显存占用,使得在有限硬件上训练百亿甚至千亿参数模型成为可能。ColossalAI 由 HPC-AI Tech 团队开发,提供了张量并行、流水线并行、序列并行等多维度并行策略。Horovod 最初由 Uber 开源,采用 Ring-AllReduce 通信模式,以其简洁的 API 和框架无关性著称。Ray 则是一个通用的分布式计算框架,其子项目 Ray Train 专注于分布式训练场景。Volcano 是 CNCF 旗下的批量调度系统,专为 Kubernetes 上的高性能计算和 AI 训练任务设计。
超参搜索(Hyperparameter Search)功能的集成也是一大亮点。超参数是在模型训练开始前需要人为设定的参数,如学习率、批量大小、网络层数、正则化系数等,它们直接影响模型的收敛速度和最终性能。传统的手动调参依赖工程师的经验和直觉,效率低下且难以找到全局最优解。自动化超参搜索技术包括网格搜索(Grid Search)、随机搜索(Random Search)、贝叶斯优化(Bayesian Optimization)以及基于早停策略的 Hyperband 等方法。在 Kubernetes 生态中,Katib 是最常用的超参搜索组件,它能够自动创建多组不同超参配置的训练任务并行运行,根据目标指标(如验证集准确率)自动筛选最优配置。用户可以在平台内直接进行自动化超参调优,告别手动调参的低效循环,显著提升模型迭代效率。
大模型训练与微调能力
在大模型时代,Cube Studio 紧跟技术趋势,提供了对 DeepSeek 等大模型的 SFT 微调、奖励模型训练(Reward Model)以及强化学习训练(RLHF) 的完整支持。
SFT(Supervised Fine-Tuning,监督微调)是大模型定制化的第一步,通过在特定领域的标注数据上继续训练预训练模型,使其具备特定任务的能力。奖励模型(Reward Model)训练是 RLHF 流程的关键中间环节:首先收集人类对模型不同输出的偏好排序数据,然后训练一个奖励模型来学习人类的偏好判断标准。RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)则利用训练好的奖励模型作为奖励信号,通过 PPO(Proximal Policy Optimization)等强化学习算法进一步优化语言模型,使其输出更符合人类期望。这条从 SFT 到 Reward Model 再到 RLHF 的技术链条,正是 ChatGPT、DeepSeek 等对话大模型背后的核心训练范式。近期 DeepSeek 还引入了 GRPO(Group Relative Policy Optimization)等创新方法,进一步推动了强化学习训练技术的演进。
企业可以基于开源大模型,在自有数据上完成从监督微调到对齐训练的全流程。对于希望在私有化环境中训练和定制大模型的团队而言,这套能力链条具有很高的实用价值,能够有效保障数据安全和模型可控性。
推理服务与 VGPU 虚拟化
模型训练完成后,Cube Studio 提供了完善的推理服务部署能力。平台集成了 vLLM、Ollama、MindIE 等主流大模型推理引擎,支持多机推理部署,能够应对高并发的线上推理场景。
vLLM 是由加州大学伯克利分校团队开发的高性能大模型推理引擎,其核心创新是 PagedAttention 技术,借鉴了操作系统虚拟内存的分页管理思想来管理 KV Cache,相比传统实现可将推理吞吐量提升 2-4 倍。Ollama 则定位为轻量级的本地大模型运行工具,以极简的用户体验著称,适合快速部署和测试场景。MindIE(Mind Inference Engine)是华为昇腾生态的推理引擎,专为昇腾 NPU 硬件优化,在国产化部署场景中具有不可替代的地位。多机推理(也称张量并行推理或流水线并行推理)则是应对超大模型(如数百亿参数)单卡显存不足问题的关键技术,通过将模型参数分布在多块 GPU 上协同完成推理计算。
特别值得关注的是 VGPU 虚拟化功能。在 GPU 资源紧张的现实环境下,通过虚拟化技术将单张物理 GPU 切分为多个虚拟 GPU,可以显著提升资源利用率,降低算力成本。VGPU 虚拟化技术的核心思想是在物理 GPU 和应用程序之间增加一个虚拟化层,将单张物理 GPU 的算力和显存按需切分给多个容器或虚拟机使用。在 Kubernetes 生态中,常见的 VGPU 方案包括 NVIDIA 官方的 MIG(Multi-Instance GPU,仅 A100/H100 等高端卡支持)、NVIDIA vGPU 商业方案,以及国内开源的 HAMi(原 vGPU-scheduler)等项目。这些方案通过 API 拦截、时间片轮转或硬件级隔离等不同技术路径实现资源切分。在实际生产环境中,GPU 利用率低下是一个普遍问题——许多开发和推理任务仅使用了 GPU 10%-30% 的算力,VGPU 虚拟化可以将这些碎片化的算力聚合利用,据行业实践数据,GPU 整体利用率可从 30% 提升至 70% 以上。
配合平台的算力租赁功能,Cube Studio 实际上可以充当企业内部的 GPU 算力管理和调度中心。
标注平台与私有知识库
Cube Studio 还内置了自动化标注平台,将数据标注这一通常需要外部工具完成的环节纳入了统一平台。同时,平台提供了私有知识库功能,结合大模型推理能力,可以快速搭建企业级的 RAG(检索增强生成)应用。
RAG(Retrieval-Augmented Generation,检索增强生成)是当前企业级大模型应用的主流架构模式。其核心思路是在大模型生成回答之前,先从外部知识库中检索与用户问题相关的文档片段,将这些片段作为上下文注入到提示词(Prompt)中,再由大模型基于这些参考信息生成回答。相比纯粹依赖模型参数中的知识,RAG 能够有效解决大模型的知识时效性问题和幻觉(Hallucination)问题,同时避免了为每个特定领域都进行昂贵的模型微调。一个完整的 RAG 系统通常包括文档解析、文本分块、向量化(Embedding)、向量数据库存储、相似度检索和大模型生成等环节。Cube Studio 将私有知识库与推理引擎集成在同一平台上,简化了 RAG 应用的搭建流程。
此外,AI 模型市场的设计让团队内部的模型资产得以沉淀和复用,有效避免重复造轮子的问题。
国产化生态支持
在信创和国产化替代的大背景下,Cube Studio 的国产化支持是其重要的差异化优势。平台明确支持国产 CPU、GPU 以及华为昇腾 NPU 生态,同时支持 RDMA 高速网络,确保在国产硬件环境下也能实现高效的分布式训练通信。
华为昇腾(Ascend)NPU 是目前国产 AI 芯片中生态最为成熟的方案之一,其旗舰产品 Ascend 910B 在大模型训练场景中已被多家企业采用。昇腾生态包括底层硬件、CANN(Compute Architecture for Neural Networks)算子库、MindSpore 框架以及 MindIE 推理引擎等完整技术栈。RDMA(Remote Direct Memory Access,远程直接内存访问)是高性能计算和分布式训练中的关键网络技术,它允许网卡直接访问远程机器的内存,绕过操作系统内核和 CPU 的参与,将网络通信延迟从微秒级降低到亚微秒级。在大模型分布式训练中,节点间需要频繁同步梯度数据,RDMA 网络(通常基于 InfiniBand 或 RoCE v2 协议)可以将通信开销降低一个数量级,是实现高效多机训练的基础设施前提。
这对于金融、政务、运营商等对国产化有硬性要求的行业用户来说,Cube Studio 提供了一个经过实际验证的技术选型方案。
云原生技术架构解析
Cube Studio 基于云原生架构构建,底层依托 Kubernetes 进行容器编排和资源管理。Kubernetes(简称 K8s)最初由 Google 开源,已成为容器编排的事实标准。在 AI 平台场景中,Kubernetes 的价值远不止于容器管理:它提供了统一的资源抽象层,使得 CPU、GPU、NPU 等异构计算资源可以通过 Device Plugin 机制被统一调度;其 Namespace 和 ResourceQuota 机制天然支持多租户资源隔离和配额管理;Operator 模式则允许平台开发者将复杂的分布式训练任务(如 PyTorchJob、TFJob)封装为 Kubernetes 原生资源,由自定义控制器自动管理任务的生命周期。
这种架构选择带来了几个显著优势:
- 弹性伸缩:训练和推理资源可以根据负载动态调整。Kubernetes 的 Horizontal Pod Autoscaler(HPA)和 Cluster Autoscaler 机制为推理服务的弹性伸缩提供了原生支持,可以根据请求量自动扩缩推理实例数量,在保证服务质量的同时优化资源成本。
- 多租户隔离:支持企业内多团队共享同一平台,通过 Namespace 和资源配额实现团队间的资源隔离与公平调度。
- 标准化部署:基于容器的交付方式降低了环境一致性问题,确保训练环境和生产环境的高度一致。
- 边缘计算支持:云原生架构天然适配边缘场景的模型部署,借助 KubeEdge 等边缘计算框架,可以将训练好的模型无缝推送到边缘节点运行。
社区活跃度与项目成熟度
截至目前,Cube Studio 在 GitHub 上拥有 4983 个 Star 和 877 个 Fork,项目以 Python 为主要开发语言。从社区活跃度来看,项目保持着持续更新,功能覆盖面也在不断扩展。
作为腾讯音乐内部实践沉淀后开源的项目,Cube Studio 的功能设计带有明显的生产环境导向——它不是一个实验性的 Demo,而是经过大规模业务验证的工程化平台。
总结
在 AI 基础设施领域,Cube Studio 的定位非常清晰:做一个覆盖 MLOps 全流程、适配大模型时代需求、支持国产化生态的一站式云原生 AI 平台。从 Notebook 开发到分布式训练,从大模型微调到推理部署,从数据标注到知识库构建,它试图用一个平台解决 AI 工程化的所有核心问题。
功能全面也意味着部署和运维的复杂度较高,企业在选型时需要评估自身团队的技术能力和实际需求。但对于有一定基础设施能力、希望构建统一 AI 平台的中大型团队来说,Cube Studio 无疑是一个极具竞争力的开源选择。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。