Cube Studio:腾讯开源一站式AI平台,覆盖大模型训练到推理全流程
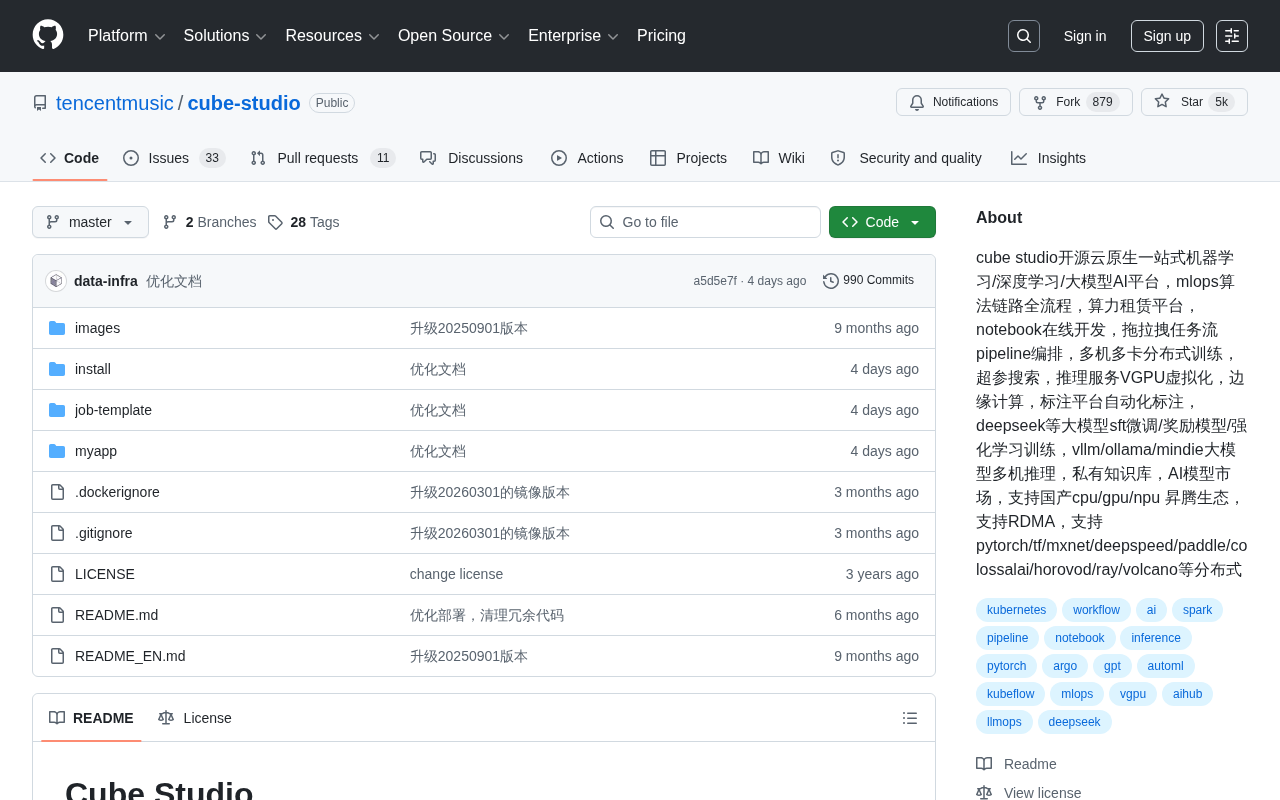
腾讯音乐开源的云原生一站式AI平台,覆盖MLOps全流程并支持国产化硬件。
Cube Studio是腾讯音乐开源的基于云原生架构的一站式AI平台,覆盖数据标注、模型训练到推理部署的MLOps全流程。它支持十余种分布式训练框架和VGPU虚拟化,内置大模型RLHF全链路训练与vLLM等推理引擎,并全面适配华为昇腾等国产硬件生态,在功能完整度和国产化支持方面优于Kubeflow、MLflow等竞品。
项目概览
在AI工程化落地的浪潮中,如何高效管理从数据标注、模型训练到推理部署的全流程,一直是企业面临的核心挑战。腾讯音乐开源的 Cube Studio 正是为解决这一痛点而生——它是一个基于云原生架构的一站式机器学习/深度学习/大模型AI平台,覆盖了MLOps算法链路的全流程。
MLOps(Machine Learning Operations)是将DevOps的理念引入机器学习领域的实践方法论,旨在解决模型从实验室到生产环境的"最后一公里"问题。传统ML开发中,数据科学家在Jupyter Notebook中完成的实验往往难以直接部署为生产服务,模型版本管理混乱、训练环境不可复现、部署流程手动且易出错。MLOps通过自动化CI/CD流水线、模型版本控制、特征存储、模型监控等机制,将ML生命周期标准化。云原生架构则以容器化(Docker)、容器编排(Kubernetes)、微服务和声明式API为核心,提供了弹性、可移植、可观测的基础设施层,天然适合承载MLOps工作负载。
目前该项目在GitHub上已获得近 5000 Stars、877 Forks,采用Python开发,社区活跃度持续攀升。从项目定位来看,Cube Studio不仅仅是一个训练平台,更是一个涵盖算力管理、开发环境、任务编排、分布式训练、推理服务、边缘计算和数据标注的综合性AI基础设施。
Notebook在线开发与Pipeline任务编排
Cube Studio提供了基于Web的Notebook在线开发环境,开发者无需配置本地环境即可直接编写和调试代码。更重要的是,平台支持拖拉拽式的任务流Pipeline编排,用户可以通过可视化界面将数据处理、特征工程、模型训练、评估等步骤串联成完整的工作流。
ML Pipeline的概念源自数据工程中的DAG(有向无环图)调度思想。每个Pipeline由多个Step组成,Step之间存在数据依赖关系,调度器根据DAG拓扑顺序执行任务。在Kubernetes生态中,Argo Workflows和Tekton是两个主流的Pipeline引擎,它们将每个Step封装为Pod运行,通过Artifact传递中间结果。拖拉拽式的可视化编排本质上是将DAG的定义从YAML/代码转化为图形界面操作,降低了用户理解和使用Pipeline的认知成本。这种模式在Apache Airflow等数据工程工具中已被验证有效,Cube Studio将其引入ML场景并与GPU资源调度深度集成。
这种低代码化的编排方式大幅降低了MLOps的使用门槛,让算法工程师能够专注于模型本身而非基础设施搭建。对比手动编写调度脚本的传统方式,Pipeline可视化编排在协作效率和可维护性上都有质的提升。
多机多卡分布式训练能力
分布式训练能力是Cube Studio的核心竞争力之一。平台支持极为丰富的分布式训练框架生态,包括:
- PyTorch / TensorFlow / MXNet:主流深度学习框架全覆盖
- DeepSpeed / ColossalAI:大模型训练加速框架
- Horovod / PaddlePaddle:跨框架分布式训练
- Ray / Volcano:弹性调度与批量计算
多机多卡分布式训练的核心挑战在于梯度同步的通信开销。主流的并行策略包括数据并行(Data Parallelism)、模型并行(Model Parallelism/Tensor Parallelism)和流水线并行(Pipeline Parallelism)。数据并行中每张卡持有完整模型副本,训练不同数据分片后通过AllReduce操作同步梯度;模型并行则将模型参数切分到不同设备上。DeepSpeed的ZeRO优化器通过将优化器状态、梯度和参数分片到不同设备,显著降低了单卡显存占用,使得在有限硬件上训练百亿参数模型成为可能。
同时平台支持RDMA高速网络互联,这对于多机多卡训练场景下的通信效率至关重要。RDMA(Remote Direct Memory Access)技术允许网卡直接访问远程主机内存,绕过CPU和操作系统内核,将网络延迟从微秒级降至亚微秒级,带宽可达100-400Gbps(如InfiniBand HDR/NDR),这对于大模型训练中频繁的梯度通信至关重要。配合超参搜索功能,用户可以自动化地探索最优模型配置,显著提升训练效率。
大模型训练与微调全流程
在大模型时代,Cube Studio紧跟技术前沿,提供了完整的大模型训练链路支持:
- SFT监督微调:支持DeepSeek、LLaMA等主流大模型的指令微调
- 奖励模型训练:RLHF流程中的关键环节
- 强化学习训练:完整的对齐训练Pipeline
RLHF(Reinforcement Learning from Human Feedback)是当前大模型对齐的主流技术路线,由OpenAI在InstructGPT论文中系统化提出。完整的RLHF流程包含三个阶段:第一阶段是SFT(Supervised Fine-Tuning),使用人工编写的高质量指令-回复对对预训练模型进行监督微调,使模型学会遵循指令的基本能力;第二阶段训练奖励模型(Reward Model),收集同一提示下多个模型回复的人类偏好排序数据,训练一个能预测人类偏好分数的模型;第三阶段使用PPO(Proximal Policy Optimization)等强化学习算法,以奖励模型的输出作为奖励信号,优化语言模型的生成策略。近期DPO(Direct Preference Optimization)等方法尝试跳过奖励模型直接从偏好数据优化,但RLHF仍是工业界的主流选择。
这意味着企业可以在Cube Studio上完成从预训练模型到定制化大模型的全流程,无需拼凑多个工具链。相比单独使用LLaMA-Factory等微调工具,Cube Studio的优势在于将微调与数据管理、资源调度、模型部署打通,形成闭环。
推理服务部署与VGPU虚拟化
在模型部署侧,Cube Studio支持vLLM、Ollama、MindIE等主流大模型推理引擎,并且支持多机推理,能够应对大规模并发请求场景。
大模型推理面临的核心瓶颈是KV Cache的显存管理问题。在自回归生成过程中,每个token的生成都需要访问之前所有token的Key-Value缓存,随着序列长度增加,KV Cache占用的显存线性增长。vLLM提出的PagedAttention机制借鉴了操作系统虚拟内存的分页思想,将KV Cache划分为固定大小的块(Block),通过块表(Block Table)进行非连续内存管理,解决了传统实现中因预分配连续内存导致的显存碎片和浪费问题。这使得vLLM的吞吐量相比HuggingFace Transformers提升2-24倍。Ollama则专注于本地化部署的易用性,提供类Docker的模型管理体验。MindIE是华为昇腾生态的推理引擎,针对Ascend NPU的架构特点进行了深度优化。
特别值得关注的是平台的VGPU虚拟化能力。通过GPU虚拟化技术,多个推理任务可以共享同一块物理GPU,极大提升了GPU利用率。GPU虚拟化技术解决的是GPU资源利用率低下的问题——在实际生产环境中,许多推理任务和开发调试场景并不需要整块GPU的全部算力和显存,但传统调度方式只能以整卡为最小分配单位,导致大量算力闲置。VGPU技术通过在驱动层或运行时层进行拦截,实现对GPU算力和显存的细粒度切分。NVIDIA的MPS(Multi-Process Service)和MIG(Multi-Instance GPU)是硬件厂商提供的原生方案,而开源社区的方案(如HAMi/vGPU-scheduler)则通过Kubernetes Device Plugin机制,在调度层面实现GPU的逻辑切分和配额管理。这使得一块A100 80GB显存的GPU可以同时服务多个小型推理任务,将GPU利用率从典型的30%提升至70%以上。
对于算力成本高昂的企业而言,这一特性具有显著的经济价值。平台同时定位为算力租赁平台,具备完善的资源管理和计费能力。
国产化生态与昇腾NPU适配
在信创和国产化替代的大背景下,Cube Studio的一大亮点是全面支持国产CPU/GPU/NPU,特别是华为昇腾生态的深度适配。这使得平台能够在国产化硬件环境中稳定运行,满足政企客户的合规需求。
华为昇腾(Ascend)是目前国产AI芯片生态最为完整的方案。其硬件产品线包括训练芯片Ascend 910系列和推理芯片Ascend 310系列,配套的软件栈包括底层驱动CANN(Compute Architecture for Neural Networks)、深度学习框架MindSpore、以及模型开发工具MindStudio。昇腾的达芬奇架构采用3D Cube计算单元,专为矩阵运算优化。在适配层面,PyTorch通过torch_npu插件可以在昇腾硬件上运行,但算子覆盖率和性能调优仍需持续投入。除华为外,寒武纪(MLU)、海光(DCU)、燧原科技(GCU)等国产芯片也在快速发展,但生态成熟度与昇腾仍有差距。信创(信息技术应用创新)政策要求关键行业逐步实现核心技术自主可控,这为国产AI芯片和适配平台创造了巨大的市场需求。
这一特性在同类开源项目中较为少见。无论是Kubeflow还是MLflow,目前对国产硬件的支持都相当有限,而Cube Studio在这方面的投入体现了项目团队对国内市场需求的深刻理解。
数据标注与边缘计算支持
平台还集成了自动化标注平台,将数据标注环节纳入统一管理。结合AI辅助标注能力,可以大幅提升标注效率和质量。
此外,边缘计算支持使得训练好的模型能够部署到边缘设备,覆盖IoT、工业质检、智能安防等场景。从数据标注到边缘部署的全链路打通,减少了企业在不同工具间切换的成本。
云原生技术架构优势
Cube Studio基于云原生架构设计,天然具备以下优势:
- 弹性伸缩:基于Kubernetes的资源调度,按需分配计算资源
- 多租户隔离:支持多团队、多项目的资源隔离和权限管理
- 可观测性:完善的日志、监控和告警体系
- 可扩展性:模块化设计,支持自定义组件接入
平台还提供了AI模型市场和私有知识库功能,前者方便团队内部的模型共享和复用,后者则支持基于RAG的企业知识问答场景。RAG(Retrieval-Augmented Generation,检索增强生成)是解决大模型"幻觉"问题和知识时效性问题的主流技术方案。其核心思路是在生成回答前,先从外部知识库中检索与用户问题相关的文档片段,将检索结果作为上下文注入到大模型的提示词中,引导模型基于真实信息生成回答。典型的RAG系统包含文档解析、文本分块(Chunking)、向量化(Embedding)、向量数据库存储(如Milvus、Chroma)、相似度检索和答案生成等环节。企业私有知识库通过RAG技术,可以让大模型在不暴露训练数据的前提下,准确回答基于内部文档的专业问题,这在客服、法务、技术支持等场景中具有极高的应用价值。
与Kubeflow、MLflow等竞品对比
与Kubeflow、MLflow等国际开源MLOps平台相比,Cube Studio的差异化优势主要体现在:
| 对比维度 | Cube Studio | Kubeflow | MLflow |
|---|---|---|---|
| 大模型支持 | 内置RLHF全流程、多推理引擎 | 需额外集成 | 不涉及 |
| 国产硬件适配 | 昇腾NPU深度支持 | 基本不支持 | 不涉及 |
| 功能完整度 | 标注到推理全链路 | 训练为主 | 实验管理为主 |
| 中文生态 | 文档社区中文为主 | 英文为主 | 英文为主 |
该平台适合中大型企业的AI团队,特别是需要管理多种模型训练任务、追求GPU资源高效利用、有国产化合规要求的组织。
总结
Cube Studio作为腾讯音乐开源的AI基础设施平台,展现了国内企业在MLOps领域的工程实力。它不仅覆盖了传统机器学习的全流程,更在大模型训练、推理和国产化适配方面走在了前列。
对于正在构建或升级AI平台的团队而言,Cube Studio是一个值得深入评估的开源选项。尤其是在大模型落地需求日益增长、国产化替代加速推进的当下,一个能同时满足这两方面需求的开源平台,具备相当的实用价值。
核心要点
- Cube Studio是腾讯音乐开源的云原生一站式AI平台,覆盖从数据标注、模型训练到推理部署的MLOps全流程
- 支持PyTorch、DeepSpeed、ColossalAI等十余种分布式训练框架,具备RDMA高速网络和VGPU虚拟化能力
- 内置大模型SFT微调、奖励模型、强化学习训练全链路,集成vLLM/Ollama等主流推理引擎
- 全面支持国产CPU/GPU/NPU及华为昇腾生态,满足信创合规需求
- 项目已获近5000 GitHub Stars,提供可视化Pipeline编排、AI模型市场、私有知识库等企业级功能
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。