Cube Studio:腾讯开源云原生AI平台全面解析

Cube Studio是腾讯音乐开源的云原生一站式AI平台,覆盖MLOps全流程及大模型训练推理。
Cube Studio是腾讯音乐开源的云原生AI平台(近5000 Star),基于Kubernetes构建,覆盖从数据标注、Notebook开发、Pipeline编排、分布式训练到推理部署的MLOps全流程。平台支持DeepSpeed、vLLM等主流框架,提供大模型SFT微调、RLHF训练及RAG应用能力,并适配华为昇腾等国产硬件生态,适合有AI工程化和国产化需求的企业团队。
项目概述
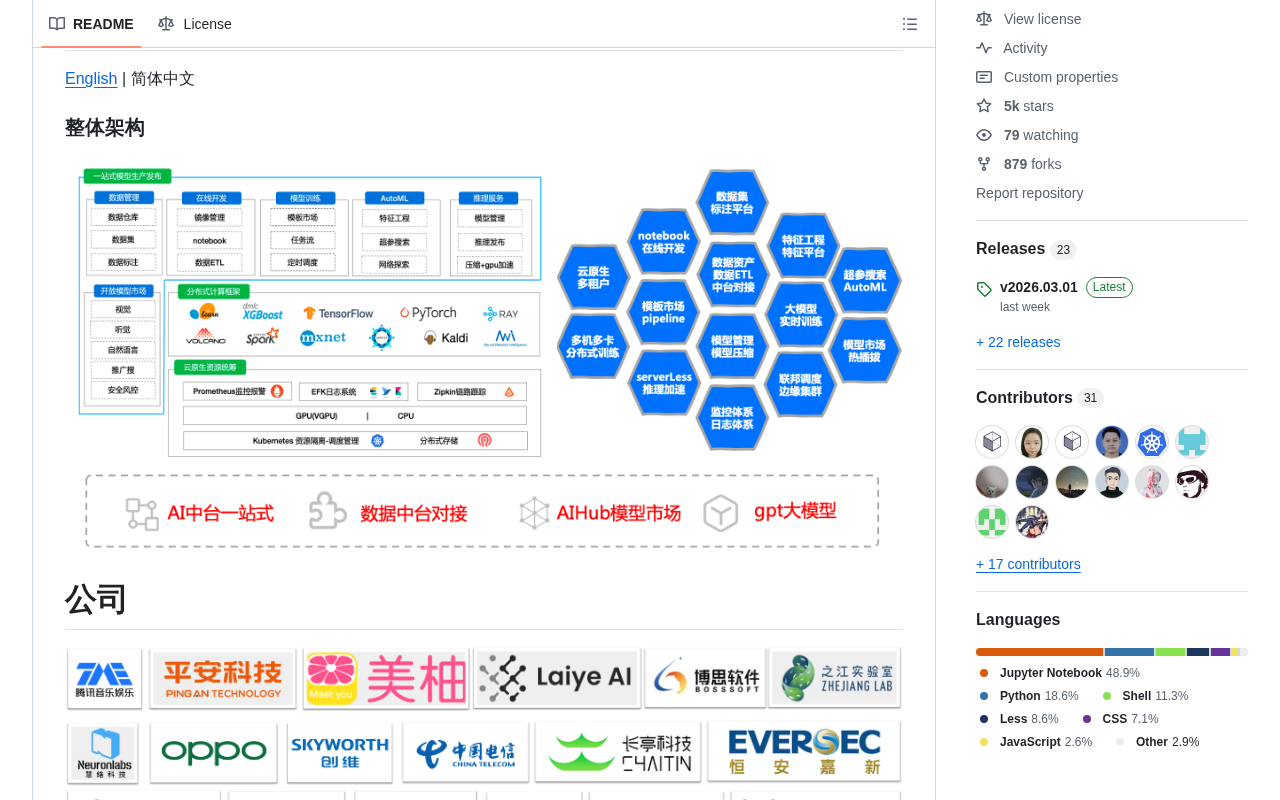
Cube Studio 是腾讯音乐(Tencent Music)开源的云原生一站式机器学习/深度学习/大模型AI平台,目前在GitHub上已获得近5000颗Star。项目以Python为主要开发语言,打造覆盖MLOps全流程的综合性平台——从数据标注、模型训练到推理部署,实现端到端的AI工程化能力。
MLOps(Machine Learning Operations)是将DevOps理念应用于机器学习领域的工程实践,旨在解决模型从实验室到生产环境的"最后一公里"问题。传统ML开发中,数据科学家在Jupyter Notebook中完成的实验往往难以直接部署上线,模型版本管理混乱、训练不可复现、部署流程手动化等问题普遍存在。MLOps通过标准化数据管理、自动化训练流水线、模型版本控制、持续集成/持续部署(CI/CD)、模型监控与反馈等环节,将机器学习工程化为可重复、可追溯、可规模化的系统工程。Cube Studio正是这一理念的完整实践。
在大模型时代,企业对AI基础设施的需求日益复杂。Cube Studio为中小企业和开发团队提供了功能完备、开箱即用的AI平台解决方案,帮助团队快速构建自己的AI研发体系。
Notebook在线开发与Pipeline编排
Cube Studio提供了Notebook在线开发环境,开发者无需配置本地环境即可直接进行算法开发和调试。更值得关注的是其拖拉拽式的任务流Pipeline编排能力——用户通过可视化界面将数据处理、特征工程、模型训练、模型评估等步骤串联成完整工作流,大幅降低MLOps实施门槛。
这种设计理念与Kubeflow Pipelines类似,但Cube Studio在此基础上做了更多本土化和易用性优化,非专业运维人员也能快速构建复杂的AI工作流。Kubeflow Pipelines是Google开源的基于Kubernetes的ML工作流编排系统,是云原生ML平台的事实标准之一。它允许用户将ML工作流定义为有向无环图(DAG),每个节点是一个容器化的处理步骤。Pipeline编排的核心价值在于实现实验的可复现性——每次运行的参数、数据、代码版本都被完整记录,便于回溯和对比。Cube Studio在此基础上的本土化优化,主要体现在更友好的中文界面、更低的使用门槛以及对国内常用框架和工具链的深度集成。
分布式训练能力详解
在分布式训练方面,Cube Studio展现了极强的兼容性和灵活性:
- 深度学习框架支持:兼容PyTorch、TensorFlow、MXNet、PaddlePaddle等主流框架
- 分布式训练方案:支持DeepSpeed、ColossalAI、Horovod、Ray、Volcano等多种方案
- 硬件适配能力:支持多机多卡训练,兼容RDMA高速网络
- 超参数搜索:内置自动化超参搜索功能,提升模型调优效率
要理解这些分布式训练方案的差异和价值,有必要了解它们各自的技术特点。DeepSpeed是微软开源的深度学习优化库,其核心创新ZeRO(Zero Redundancy Optimizer)技术通过将模型状态(参数、梯度、优化器状态)分片到多个GPU上,突破了单卡显存限制,使得千亿参数模型的训练成为可能。ColossalAI是由新加坡国立大学HPC-AI Lab开源的大模型训练系统,提供多维并行(数据并行、张量并行、流水线并行、序列并行)的统一抽象。Horovod由Uber开源,基于Ring-AllReduce算法实现高效的数据并行训练。Ray是UC Berkeley开源的分布式计算框架,其Ray Train模块支持弹性分布式训练。Volcano则是CNCF项目,专注于Kubernetes上的批处理和高性能计算任务调度。
值得特别说明的是**RDMA(Remote Direct Memory Access)**技术——它允许网络中的计算机直接访问远程内存,绕过操作系统内核,将网络延迟降低到微秒级别,是大规模分布式训练中GPU间高速通信的关键基础设施。在千卡级别的训练集群中,网络通信效率往往是决定整体训练速度的瓶颈,RDMA的支持对于大模型训练场景至关重要。
这种广泛的生态兼容性意味着团队可以根据实际场景灵活选择最优训练方案,无需担心平台层面的限制。
大模型训练与推理部署
紧跟大模型浪潮,Cube Studio对大模型场景提供了全面支持:
训练侧能力
支持DeepSeek等大模型的SFT微调、奖励模型训练和强化学习(RLHF)训练,覆盖大模型对齐的完整流程。
这里涉及的大模型对齐训练是当前AI领域最核心的技术流程之一。**SFT(Supervised Fine-Tuning,监督微调)**是大模型对齐的第一步,通过高质量的指令-回答数据对预训练模型进行微调,使其学会遵循人类指令。**RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是OpenAI在ChatGPT中采用的核心技术,其流程包括三个阶段:首先进行SFT微调,然后训练奖励模型(Reward Model)**学习人类偏好排序,最后使用PPO(Proximal Policy Optimization)等强化学习算法,以奖励模型的评分为信号优化语言模型的输出。DeepSeek在此基础上还引入了GRPO(Group Relative Policy Optimization)等创新算法,进一步提升了对齐效果。这一完整流程的工程化实现需要大量的算力调度和数据管理能力,正是Cube Studio这类平台的核心价值所在。
推理侧能力
集成vLLM、Ollama、MindIE等主流大模型推理引擎,支持多机推理部署,并提供VGPU虚拟化能力,实现GPU资源的精细化管理和高效利用。
这些推理引擎各有侧重和技术创新。vLLM是UC Berkeley开源的高性能大模型推理引擎,其核心创新PagedAttention技术借鉴了操作系统虚拟内存的分页管理思想,将KV Cache(键值缓存)按页管理,解决了传统推理中显存碎片化导致的浪费问题,吞吐量相比HuggingFace Transformers提升数倍至数十倍。Ollama是面向本地部署的轻量级大模型运行框架,以极简的命令行体验著称,支持GGUF等量化格式,降低了大模型本地运行的门槛。**MindIE(Mind Inference Engine)**是华为昇腾生态的推理引擎,针对昇腾NPU进行了深度优化。
VGPU虚拟化技术允许将一块物理GPU切分为多个虚拟GPU实例,每个实例拥有独立的显存和算力配额,实现GPU资源在多个任务或用户间的精细化共享。在实际生产环境中,GPU平均利用率往往不足30%,VGPU技术可将这一数字大幅提升,显著降低算力成本。
应用侧能力
内置私有知识库功能,支持RAG(检索增强生成)等企业级大模型应用场景,帮助企业快速落地AI应用。
**RAG(Retrieval-Augmented Generation,检索增强生成)**是解决大模型"幻觉"问题和知识时效性问题的主流技术方案。其工作原理是:当用户提出问题时,系统首先从企业私有知识库中检索相关文档片段,然后将检索结果作为上下文与用户问题一起输入大模型,使模型基于真实数据生成回答。这一过程涉及文档解析、文本分块(Chunking)、向量化嵌入(Embedding)、向量数据库存储与检索、提示词工程等多个环节。相比直接微调模型,RAG的优势在于无需重新训练即可更新知识,且回答可追溯到具体数据源,更适合企业级场景中对准确性和可解释性的要求。
国产化生态与昇腾适配
Cube Studio明确支持国产CPU/GPU/NPU,特别是华为昇腾生态。在国产化替代的大背景下,这一特性使其成为国内企业构建自主可控AI基础设施的重要选择。对于政企客户和有信创需求的组织,Cube Studio提供了经过验证的国产硬件适配方案。
华为**昇腾(Ascend)**是华为推出的AI计算架构,包括昇腾处理器(NPU)、CANN(Compute Architecture for Neural Networks)异构计算架构、MindSpore深度学习框架等完整技术栈。昇腾910B/910C等高端AI处理器定位对标NVIDIA A100/H100,在国产化替代场景中扮演核心角色。**信创(信息技术应用创新)**是中国推动关键领域IT基础设施自主可控的国家战略,涵盖芯片、操作系统、数据库、中间件、应用软件等全栈。在中美科技竞争背景下,NVIDIA高端GPU对华出口受限,国产AI芯片的适配能力成为AI平台的关键竞争力。Cube Studio对昇腾生态的支持意味着它已经完成了从底层算子到上层框架的全链路适配验证,这对于有合规要求的政企客户而言具有重要的战略意义。
算力管理与边缘计算
Cube Studio提供算力租赁平台能力,支持算力资源的统一管理和调度。同时覆盖边缘计算场景,使模型能够部署到边缘设备上,满足低延迟、离线推理等特殊业务需求。
数据标注与自动化能力
平台内置自动化标注功能,结合AI辅助标注能力,显著提升数据标注效率并降低人工成本。从数据准备到模型上线的完整链路都可以在同一平台内完成,避免了多工具切换带来的效率损耗。
云原生技术架构
Cube Studio基于云原生架构设计,充分利用Kubernetes的容器编排能力:
- 弹性伸缩:基于K8s资源调度,实现训练和推理资源的动态分配
- 多租户隔离:通过容器化实现资源隔离和安全保障
- 模块化扩展:支持按需扩展功能组件,灵活适配不同规模
- 模型市场:内置AI模型市场,促进模型资产的复用和共享
**云原生(Cloud Native)**是一种构建和运行应用程序的方法论,核心技术包括容器化、微服务架构、声明式API和不可变基础设施。**Kubernetes(K8s)**作为容器编排的事实标准,为AI平台提供了资源调度、服务发现、自动扩缩容、故障自愈等关键能力。在AI场景中,K8s的价值尤为突出:通过Device Plugin机制管理GPU/NPU等异构硬件资源,通过Operator模式管理分布式训练任务的生命周期,通过Namespace和ResourceQuota实现多租户资源隔离。Cube Studio基于K8s构建意味着它天然具备跨云部署能力——无论是公有云、私有云还是混合云环境,都可以通过标准化的K8s接口进行部署和管理,避免了厂商锁定的风险。
适用场景
Cube Studio特别适合以下场景:
- 中大型企业构建统一的AI研发平台
- 有国产化替代需求的政企客户
- 希望快速搭建大模型训练和推理基础设施的团队
- 需要算力资源统一管理和调度的组织
- 从零开始构建MLOps体系的创业公司
总结
作为一个近5000 Star的开源项目,Cube Studio代表了国内AI平台工程化的较高水平。它不仅覆盖传统MLOps全流程,还紧跟大模型时代需求,提供从微调训练到推理部署的完整能力。加上对国产化硬件的良好支持,Cube Studio对于正在寻找开源AI平台方案的团队来说,是一个值得深入评估和试用的选项。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。