Cursor 3.3上下文用量分析功能详解与优化指南
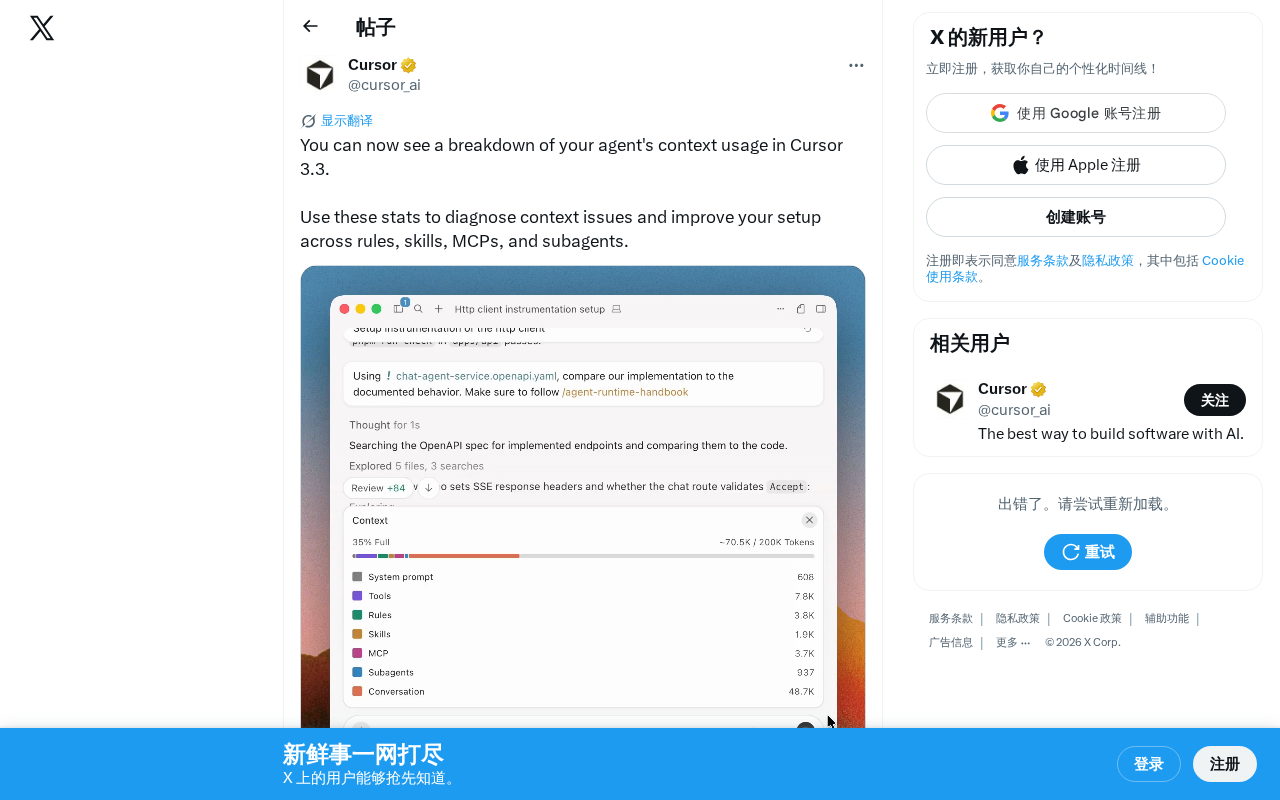
Cursor 3.3新增上下文用量分析功能,助力开发者优化AI Agent效率
Cursor 3.3版本新增Agent上下文用量分析功能,可视化展示Rules、Skills、MCP、Subagents等模块的上下文消耗明细。开发者可据此诊断Agent表现不佳的根因(如规则文件过大、MCP连接开销过高等),并通过精简规则、按需配置技能和MCP服务等方式优化上下文利用率,提升AI编程体验。
概述
Cursor 3.3 版本新增了一项实用功能——Agent 上下文用量分析(Context Usage Breakdown)。开发者可以直观查看 AI Agent 执行任务时的上下文消耗明细,精准定位上下文相关问题,并据此优化开发配置,提升 AI 编程效率。
什么是Cursor上下文用量分析
使用 Cursor Agent 模式时,上下文窗口(Context Window)是最核心的有限资源。上下文窗口是大语言模型(LLM)在单次推理过程中能够处理的最大 token 数量——token 是模型处理文本的基本单位,一个英文单词通常对应 1-2 个 token,中文字符通常对应 1-2 个 token。以当前主流模型为例,Claude 3.5 Sonnet 的上下文窗口为 200K tokens,GPT-4o 为 128K tokens。虽然这些数字看起来很大,但在实际的 Agent 编程场景中,系统提示词、项目规则、代码文件内容、工具描述、对话历史等信息会迅速填满窗口。
Agent 处理任务需要加载多种信息:项目规则(Rules)、技能配置(Skills)、MCP 服务器连接以及子代理(Subagents)的调用数据,这些都会占用上下文空间。当上下文接近上限时,模型可能会丢失早期对话中的关键信息,表现为"遗忘"或"跑偏"现象——这在学术上被称为"lost in the middle"问题,即模型对上下文中间位置的信息关注度显著低于首尾位置。
在 Cursor 3.3 之前,开发者很难掌握上下文资源的具体分配情况。当 Agent 表现不佳或出现"遗忘"现象时,只能凭经验猜测是哪个环节消耗了过多上下文。上下文用量分析功能正是为解决这一痛点而设计的——它将上下文消耗数据可视化,让每一项资源占用都清晰可见。
上下文用量分析的核心功能
快速诊断上下文瓶颈
通过查看详细的上下文用量统计,开发者可以迅速定位问题根源:
- Rules 文件过大:自定义的
.cursorrules文件如果占用了大量上下文空间,说明需要精简规则描述,或将其拆分为更有针对性的规则集。 - MCP 连接开销过高:MCP(Model Context Protocol)是 Anthropic 于 2024 年底推出的开放协议,旨在标准化 AI 模型与外部工具、数据源之间的连接方式。它类似于 AI 领域的 USB-C 接口——提供一个统一的标准,让不同的工具和服务能够以一致的方式接入 AI 系统。每个 MCP 服务器在连接时需要向模型描述自己提供的工具列表和使用方法,这些描述信息本身就会占用上下文空间。如果开发者同时连接了多个 MCP 服务器,仅工具描述就可能消耗数千甚至上万 tokens,严重挤占本应用于代码理解的上下文空间。
- 子代理调用链路过长:子代理(Subagents)是 Cursor Agent 模式中的一种任务分解机制。当主 Agent 遇到复杂任务时,它可以将任务拆分并委派给专门的子代理处理,类似于软件工程中的微服务模式。每个子代理拥有独立的执行上下文,完成任务后将结果返回给主 Agent。然而,子代理的调用指令、执行过程摘要和返回结果都需要在主 Agent 的上下文中保留,形成调用链路。当任务层级较深或子代理返回信息过于详细时,这些数据会显著挤占主 Agent 用于理解当前任务的上下文空间。了解其占比有助于优化任务拆分策略。
量化各模块的上下文占比
该功能将 Rules、Skills、MCP、Subagents 等模块的上下文消耗分别展示,开发者可以一目了然地看到哪个模块是"上下文大户",从而做出有据可依的优化决策。
如何利用用量数据优化开发配置
有了量化数据支撑,开发者可以有针对性地调整 Cursor 配置,让 Agent 的表现更加稳定高效:
- 精简 Rules 文件:移除冗余的规则描述,只保留最关键的指令。让 Agent 将更多上下文空间用于理解代码和执行任务,而不是加载大段规则文本。实践中,一个精心编写的 500 token 规则文件往往比 3000 token 的冗长规则更有效,因为它减少了模型需要处理的噪声信息。
- 合理配置 Skills:调整技能的触发条件,避免不必要的技能被自动加载,减少无效的上下文占用。Skills 本质上是预定义的能力模块,每个被激活的技能都会将其描述和使用说明注入上下文,因此按需激活而非全量加载是最佳实践。
- 按需管理 MCP 服务:根据当前项目的实际需求启用或禁用 MCP 服务器。不常用的工具可以暂时关闭,为核心功能腾出上下文空间。例如,在进行纯前端开发时,可以暂时关闭数据库相关的 MCP 服务器,节省其工具描述占用的上下文。
- 优化 Subagent 使用策略:只在确实需要时才启用子代理,避免上下文被过度分散到多个代理之间。对于简单任务,直接由主 Agent 处理通常比委派子代理更高效,因为省去了任务描述和结果汇总的上下文开销。
通过以上优化,开发者通常能显著改善 Agent 在长对话中的表现,减少"遗忘"和"跑偏"的情况。
上下文管理为何成为AI编程的关键
随着 AI 编程助手的能力持续增强,开发者对 Agent 模式的依赖也在加深。但大语言模型的上下文窗口始终是有限资源,如何高效利用这一资源,直接决定了 Agent 的输出质量。
这一功能体现了 Cursor 团队在"可观测性"(Observability)方面的深入思考——不仅要让 AI 能力更强,还要让开发者能够理解和掌控 AI 的行为。可观测性概念源自分布式系统领域,最初由 Datadog、New Relic 等监控平台推广,核心理念是通过日志、指标和追踪三大支柱来理解系统内部状态。随着 AI Agent 系统日趋复杂,LangSmith、Langfuse、Helicone 等平台已经在为 LLM 应用提供调用追踪和成本分析。Cursor 将可观测性直接内置到 IDE 中,让开发者无需借助外部工具即可理解 Agent 的资源消耗模式,代表了 AI 开发工具从"黑盒使用"向"白盒理解"演进的重要趋势。这种透明度对于建立开发者对 AI 工具的信任至关重要。
从行业趋势来看,上下文管理正在成为 AI 辅助开发的核心议题。当前 AI IDE 市场正处于快速演化期:Cursor 基于 VS Code 分支构建,以深度集成的 AI Agent 模式著称;Windsurf(原 Codeium)同样提供 Agent 编程能力,强调多文件编辑的流畅体验;GitHub Copilot 依托庞大的用户基础持续迭代其 Agent 功能;JetBrains 的 Junie、Amazon 的 Q Developer 等也在积极布局。各家产品在模型能力趋于同质化的背景下,差异化竞争正在转向上下文管理策略、工具生态整合和开发者体验优化等维度。谁能更高效地利用有限的上下文窗口,谁就能提供更优质的 AI 编程体验。Cursor 3.3 的上下文用量分析为开发者提供了数据驱动的优化路径,让调优过程从盲目试错变为精准调整。
总结
Cursor 3.3 的上下文用量分析功能看似是一个小更新,实际上为开发者打开了一扇理解 AI Agent 内部运作的窗口。对于重度使用 Cursor Agent 模式的开发者来说,这个功能能帮助你更科学地配置开发环境,获得更稳定、更高质量的 AI 辅助编程体验。
建议尽快升级到 Cursor 3.3,花些时间分析自己的上下文用量分布,找到可优化的空间。合理的上下文管理,是释放 AI 编程助手全部潜力的关键一步。
核心要点
- Cursor 3.3 新增 Agent 上下文用量分析功能,可查看 Rules、Skills、MCP、Subagents 等各模块的上下文消耗情况
- 开发者可利用该功能诊断 Agent 表现不佳的根因,如规则文件过大或 MCP 工具描述冗长等问题
- 基于量化数据,开发者可以有针对性地精简规则、优化技能配置、管理 MCP 服务,提升 Agent 整体表现
- 上下文管理正成为 AI 辅助开发的核心议题,该功能体现了 Cursor 在 AI 可观测性方面的重要探索
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。