Cursor+Claude Code双终端Skill体系搭建实战指南
解决Cursor与Claude Code双终端Skill冲突的三层目录架构方案
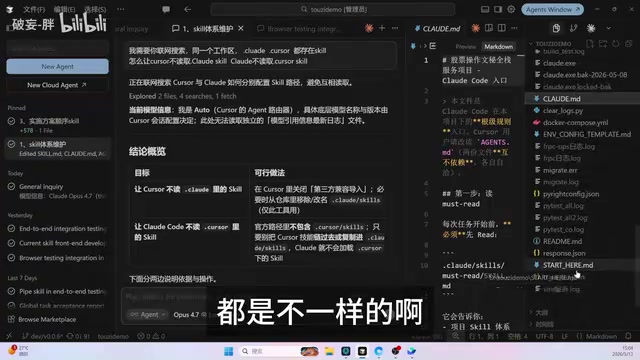
当开发者同时使用Cursor(Claude Opus)和Claude Code(DeepSeek v4)进行并行开发时,两套工具的Skill/Rules体系互不兼容,维护成本翻倍。文章提出三层Skill目录架构方案:Cursor专用目录(简洁目标导向指令)、Claude Code专用目录(详细步骤指令)、公共信息目录(共享事实性知识),通过物理隔离和MasterRule入口文件解决冲突。
双终端并行开发的Skill冲突问题
随着DeepSeek v4上线,不少开发者开始在Cursor中同时使用两套AI能力:Cursor内置的Claude Opus负责高阶推理,Claude Code插件接入DeepSeek v4负责执行落地。这种组合看上去很理想,但实际用起来很快就会碰到一个麻烦——两套工具的Skill体系互不兼容。
具体来说,Cursor读取自己目录下的Skill文件和.cursorrules(或Agent.md),Claude Code则读取CLAUDE.md。两者是完全独立的体系,各自有各自的规则文件和技能加载逻辑。
Skill/Rules文件的技术本质:在AI辅助编程工具中,"Skill"或"Rules"文件是一种系统级提示词注入机制。当开发者打开项目时,工具会自动将这些文件内容注入到每次对话的系统提示词(System Prompt)中,让模型在整个会话周期内持续遵循特定的行为规范和领域知识。Cursor与Claude Code在文件扫描逻辑和上下文窗口管理策略上存在底层差异——Cursor会递归扫描项目目录中的特定文件名,而Claude Code有自己独立的文件发现协议。这种底层差异导致即便内容相同,两套工具对同一份文件的解析和优先级处理也会产生分歧。
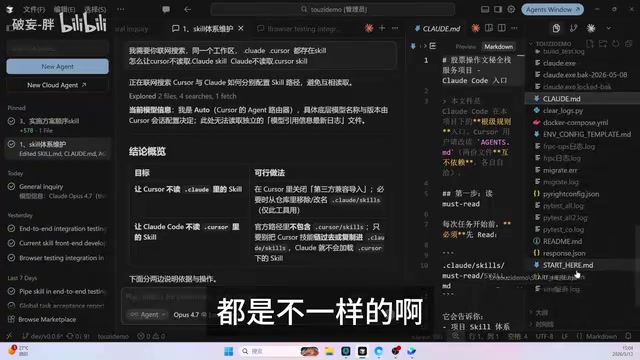
虽然Cursor官方宣称兼容Claude的Skill,但实际体验下来兼容性并不好。当Cursor存在自己的Skill时,会优先使用自有体系而非Claude的。这意味着如果你想把两套都用好,就必须同时维护两份Skill配置,维护成本直接翻倍。
工具能力与模型特性的核心差异
这个问题的本质不只是文件路径不同。更深层的原因在于,两套工具背后的模型能力和使用场景存在根本差异。
模型能力差异决定指令风格
Claude Opus(Anthropic出品)是目前公认的顶级推理模型之一,采用"宪法AI"(Constitutional AI)训练方法,在复杂指令跟随、多步骤逻辑推理和工具调用的自主决策上表现突出。面对模糊指令时,Opus能够自主补全意图、灵活选择执行路径,因此对Skill指令的颗粒度要求较低——你只需给出目标,它就能灵活选择执行路径,不用写太详细的步骤说明。
DeepSeek v4(深度求索出品)在代码生成和执行类任务上有很强的性价比优势,但在工具调用的自主推理链路上相对保守,更依赖明确的步骤拆解和约束条件。这并非缺陷,而是不同的设计取舍——更确定性的执行行为在自动化流水线中反而能减少"幻觉式自主发挥"带来的意外副作用。但这也意味着,需要给出更详细、更具体的指令内容,才能保证执行准确。
这种差异直接决定了为什么两套Skill必须采用不同的指令风格:给Opus写过于详细的步骤反而会限制其推理空间,而给DeepSeek写过于抽象的目标则会导致执行偏差。
职责分工的天然区隔
在实际工作流中,两者承担的角色也不同:
- Opus(Cursor):负责方案制定、方案审核、复杂Debug等需要高阶推理的任务
- DeepSeek(Claude Code):负责方案执行、自动化测试、运维收尾、简单Debug等执行类任务
这种天然的分工实际上形成了一个异构多智能体协作系统:Cursor/Opus扮演Orchestrator(调度者)角色,负责理解高层需求、制定执行计划;Claude Code/DeepSeek扮演Executor(执行者)角色,负责接收明确指令并落地执行。这种职责区隔意味着,对应的Skill也必须针对不同场景做差异化设计。
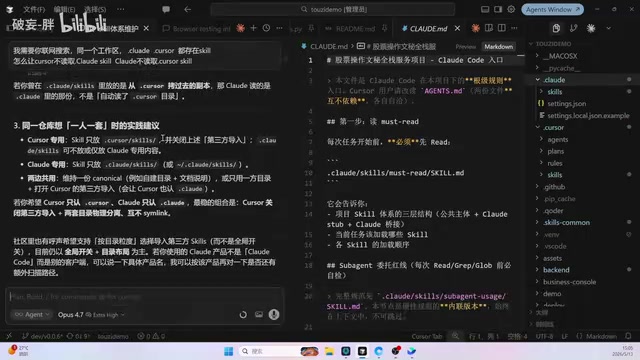
三层Skill目录架构方案详解
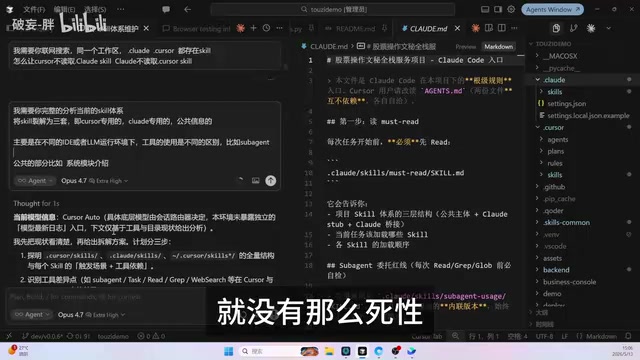
经过反复调研和实践,最终采用的方案是将Skill体系拆解为三套独立目录,各司其职。这套架构借鉴了软件工程中经典的关注点分离(Separation of Concerns)原则,并结合了DRY原则(Don't Repeat Yourself)的实践智慧——将变化频率不同的内容分层管理,工具专用的指令风格单独维护,稳定的业务知识集中共享。
第一层:Cursor专用目录
存放Cursor/Opus专属的Skill文件,包含一个MasterRule主入口文件。这个文件介绍当前技能体系的整体架构,告诉模型应该如何加载和使用各项技能。由于Opus能力强,指令可以写得相对简洁,侧重目标导向。
第二层:Claude Code专用目录
存放Claude Code/DeepSeek专属的Skill文件,同样有自己的MasterRule。但因为背后是DeepSeek,指令需要写得更加详细具体,包含更多的步骤说明和约束条件。
第三层:公共信息目录
这是两套工具共享的知识库,存放与模型无关的事实性信息:
- 系统模块介绍
- 运营知识文档
- 工具创建说明
- 各类规范(品位/Conventions)
- 经验案例库
这些内容都是客观事实的记录,不涉及模型特定的指令风格,因此可以被两套工具共同引用,避免重复维护。公共目录在多智能体架构中充当了共享知识图谱的角色,确保不同Agent在处理同一业务领域时引用一致的事实基础,避免因信息不对称导致的执行冲突。
可扩展性优势:这种分层设计与现代软件架构中的配置中心概念高度相似。随着AI工具链进一步复杂化(未来可能同时接入三个甚至更多模型),新增工具只需添加一个专用目录,公共知识层无需改动,扩展成本极低。
实施要点与最佳实践
MasterRule是整个体系的关键入口
无论是Cursor还是Claude Code目录,MasterRule文件都是必读的入口。它相当于告诉Orchestrator"你有哪些工具可以调用",同时定义了"每个工具的调用规范",承担三个核心职责:
- 介绍当前Skill体系的整体结构
- 说明各个Skill文件的用途和加载优先级
- 指导模型根据任务类型选择合适的Skill
物理隔离优于逻辑混用
核心原则是让Cursor不去读取Claude Code的Skill,反之亦然。虽然目前没有完美的全局开关来实现按目录粒度的选择性导入,但通过物理隔离目录结构,配合各自的MasterRule引导,可以有效避免冲突。
SubAgent的差异化配置
在使用SubAgent(子代理)模式时,不同工具对SubAgent的调度方式也不同。Cursor可以利用其领域专业
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。