Cursor Composer 2.5:开源模型强化训练登顶编程榜前三的秘密
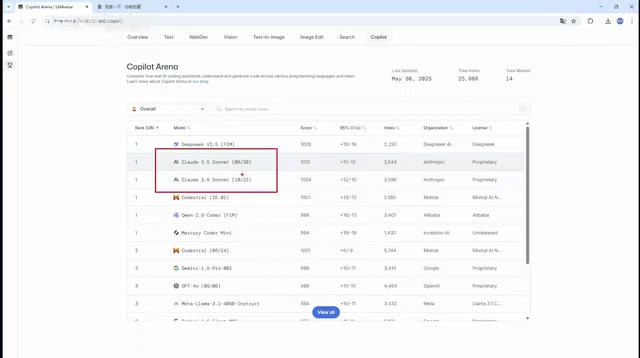
核心事件:Composer 2.5跑分跻身编程榜前三
Cursor 近日正式推出了自研模型 Composer 2.5,这是基于月之暗面(Moonshot AI)开源模型 Kimi K2 进行强化训练后的产物。月之暗面是由清华大学校友杨植麟于2023年创立的大模型公司,以长上下文窗口技术闻名。Kimi K2 采用 MoE(Mixture of Experts,混合专家)架构,总参数量达万亿级别但激活参数仅为其中一部分,这使得模型在保持强大能力的同时有效控制了推理成本。MoE 是近年来大模型领域最重要的架构创新之一——传统的 Dense Transformer 模型在推理时会激活所有参数,而 MoE 模型通过门控网络(Gating Network)动态选择少量专家子网络参与计算。例如 Kimi K2 总参数量达万亿级别,但每次推理可能只激活其中约 10%-20% 的参数,这意味着它能以远低于同等参数 Dense 模型的计算成本运行,同时保持甚至超越其性能。Google 的 Switch Transformer、Mixtral 8x7B 以及 DeepSeek-V3 都采用了类似架构。MoE 的核心挑战在于专家负载均衡和路由策略优化——如果某些专家被过度调用而其他专家闲置,就会造成计算资源浪费和模型能力退化。开源意味着任何组织都可以在其基础上进行二次训练和商业部署,这正是 Cursor 能够基于 K2 构建 Composer 2.5 的前提。
在编程领域基准测试中,Composer 2.5 拿下 63.2 分,仅次于 Opus 4(64.8分)和 GPT 5.5,排名第三。这里的编程基准测试主要指 SWE-bench(Software Engineering Benchmark)系列评测,由普林斯顿大学 Carlos E. Jimenez 等人于2023年推出,从 Django、scikit-learn、sympy 等12个知名 Python 开源项目中收集了2294个真实的 GitHub issue 及其对应的 Pull Request 修复。评测要求 AI 模型在给定 issue 描述的情况下,自主浏览代码库、定位相关文件、理解代码逻辑并生成正确的补丁。后续推出的 SWE-bench Verified 是经过人工验证的子集(500题),排除了描述模糊或测试不充分的样例,被认为更能准确反映模型的真实编程能力。与传统的代码生成评测(如 HumanEval 仅测试函数级代码补全)不同,SWE-bench 要求模型具备代码理解、跨文件推理、测试驱动开发等综合软件工程能力,因此被业界视为衡量 AI 编程能力的黄金标准。63.2 分意味着模型能够正确解决约 63.2% 的真实软件工程问题,这一水平已经非常接近当前最强的闭源模型。
这一成绩引发了广泛关注——连马斯克都转发了相关数据。更耐人寻味的是,Kimi 官方自己的 K2.6 版本在同一榜单上仅排第13名,而基于其开源版本训练的 Composer 2.5 却冲到了第三名,这一反差值得深思。
数据飞轮:Cursor凭什么把开源模型训练得比原厂还强
高质量场景数据是关键
答案在于数据质量。Cursor 作为最早一批 AI 编程工具,积累了海量用户在实际编程场景中调用各家模型的对话数据。这些数据经过沉淀,被用于对 Kimi K2 开源模型进行 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)强化训练,最终产出了 Composer 2.5。
RLHF 是当前大模型对齐和能力提升的核心技术之一。其完整流程分为三个阶段:第一阶段是监督微调(SFT),用高质量的示范数据对预训练模型进行初步对齐;第二阶段是奖励模型训练,收集人类对同一提示下多个模型输出的排序偏好,训练一个能预测人类偏好分数的奖励模型;第三阶段是强化学习优化,使用 PPO(Proximal Policy Optimization)或更新的 DPO(Direct Preference Optimization)算法,以奖励模型的评分为信号优化语言模型的策略。DPO 相比 PPO 省去了显式训练奖励模型的步骤,直接从偏好数据中学习,训练更稳定且计算成本更低。在 Cursor 的场景中,用户每天在 IDE 中接受或拒绝代码建议、修改 AI 生成的代码片段、对生成结果点赞或重新生成,这些隐式反馈天然构成了极高质量的 RLHF 训练信号——它们来自真实的开发者在真实的项目中做出的真实判断,本质上就是一种隐式的偏好排序,这种信号的密度和真实性远超传统的人工标注。
这揭示了一个重要规律:在垂直领域,高质量的场景数据比基座模型本身更重要。 Cursor 拥有真实的编程交互数据,这是任何通用大模型公司都难以比拟的优势。通用大模型公司虽然拥有更大的预训练数据集和更强的算力,但它们缺乏这种来自真实编程工作流的细粒度反馈数据。
对国内大模型公司的启示
这个案例给国内大模型公司指明了一条清晰的路径:
- 先免费获客,积累数据 —— 只有用户愿意用,才有数据沉淀。这也解释了为什么国内外 AI 编程工具普遍采用免费增值(Freemium)模式,免费层的核心目的不是慈善,而是数据采集。
- 用真实场景数据做强化训练 —— 这比单纯扩大预训练规模更高效。业界已经逐渐形成共识:预训练决定模型的能力上限,但后训练(Post-training,包括 SFT 监督微调和 RLHF)决定模型在特定任务上的实际表现。
- 构建垂直领域的数据飞轮 —— 用户越多→数据越好→模型越强→用户越多。这种正反馈循环一旦建立,后来者将极难追赶,因为数据壁垒是所有壁垒中最难被资本和算力突破的。
Cursor产品全景:从编程IDE到全栈AI开发平台
产品能力已远超代码编辑器
很多用户可能没注意到 Cursor 的产品演进速度。如今它已经不只是一个代码编辑器,而是一个完整的 AI 开发平台:
- Agent 智能体:类似 Claude Code、Devin 的自主编程能力,可以自主规划任务、搜索代码库、编写和执行代码、运行测试并根据结果迭代修复,整个过程无需人工逐步指导
- 代码审查(Code Review):自动化代码质量检查,可以在 Pull Request 阶段自动分析代码变更,识别潜在的 bug、性能问题和不符合团队规范的写法
- 云端执行:类似 Codex 和 Claude Code 的云端开发环境,将代码编译、运行和测试放在云端沙箱中执行,避免对本地环境的依赖和污染
- CLI 命令行工具:可集成到企业 CI/CD 流水线,在无图形界面的服务器环境中自动执行 AI 辅助的代码分析和生成任务
CLI工具的战略意义
Cursor 推出 CLI 并非简单地与 Claude Code 竞争。CLI 的核心价值在于企业级流水线集成。CI/CD(Continuous Integration/Continuous Deployment,持续集成/持续部署)是现代软件工程的核心实践,指代码从提交到上线的自动化流程。现代 CI/CD 流水线通常由 Jenkins、GitHub Actions、GitLab CI 等工具编排,整个流程以 YAML 配置文件定义,在无图形界面的容器或虚拟机中执行。典型的企业级流水线包含数十个步骤:代码静态分析(如 SonarQube)、依赖安全扫描(如 Snyk)、单元测试、集成测试、性能回归测试、合规审计等。AI CLI 工具嵌入这条流水线后,可以在代码提交阶段自动进行智能代码审查、在测试失败时自动分析根因并建议修复方案、在部署前自动检测潜在的安全漏洞。这种集成方式将 AI 从开发者的个人助手升级为团队级的自动化基础设施,其影响范围和商业价值远大于 IDE 插件。在这条流水线中,代码上线时的安全扫描、合规检查、格式校验等环节,都需要在无人值守的服务器环境下自动执行,这时图形化的 IDE 工具就完全不适用了,只有 CLI 工具才能被脚本调用并嵌入自动化流程。
这也是行业趋势:Claude Code 等 CLI 产品在向桌面端扩展(如推出 VS Code 插件),而 Cursor 这类桌面产品在向 CLI 回归,两者最终会在中间相遇,形成「IDE + CLI + 云端」三位一体的完整开发体验。
Cursor定价与使用建议
价格体系一览
Cursor 目前的定价方案:
- 基础版:$20/月(按量计费,有次数限制)
- Auto 版:$200/月(更高额度)
实际体验中,$20/月的基础版大约一周就会触及限流。不过 Cursor 的充值方式相对灵活,支持按量付费。
性价比分析
对于需要使用 GPT 5.5、Claude Opus 4 等顶级模型的开发者来说,通过 Cursor 这类 AI 编程工具调用这些模型,比自己购买 API Key 或找中转站要靠谱得多。原因很简单:这些产品需要维护自己的市场口碑,不会轻易降低模型质量。此外,Cursor 作为大客户与模型提供商之间有批量采购协议,其获取的 API 价格远低于个人开发者直接调用的价格,这部分成本优势会通过订阅制传递给用户。更重要的是,Cursor 在模型调用层做了大量工程优化——包括智能上下文裁剪、缓存复用、请求合并等——使得同样的 token 预算能产生更好的编程辅助效果。
生态与扩展能力
Cursor 官方市场中有大量与研发相关的插件和工具,包括 Figma、Snack 等第三方集成。即使你不使用 Cursor,也可以参考其生态中的工具,通过 MCP 协议将它们集成到 Claude Code 或其他开发环境中。
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 于2024年底推出的开放协议标准,旨在为 AI 模型与外部工具、数据源之间建立统一的通信接口。MCP 采用客户端-服务器架构,定义了三种核心原语:Resources(资源,如文件、数据库记录)、Tools(工具,如 API 调用、代码执行)和 Prompts(提示模板)。AI 应用作为 MCP 客户端发起请求,MCP 服务器负责连接具体的外部系统并返回结果。协议基于 JSON-RPC 2.0 通信,支持本地进程间通信(stdio)和远程 HTTP/SSE 两种传输方式。类似于 USB-C 统一了物理接口,MCP 统一了 AI 应用调用外部能力的方式——无论是读取数据库、调用 API、操作文件系统还是与第三方服务交互,都通过同一套协议完成。MCP 的出现解决了此前 AI 工具生态中的「N×M 集成问题」——N 个 AI 应用要对接 M 个外部工具,原本需要 N×M 个定制集成,而通过 MCP 只需 N+M 个标准化适配器。目前已有数千个 MCP 服务器被社区开发,覆盖 GitHub、Slack、PostgreSQL、Notion 等主流开发和协作工具。通过 MCP,一个为 Cursor 开发的插件理论上也可以被 Claude Code、Windsurf 等其他 AI 开发工具调用,大大降低了生态碎片化的问题,也为开发者提供了更大的工具选择自由度。
总结:数据飞轮才是AI编程的终极护城河
Composer 2.5 的成功证明了两件事:
- 中国开源模型的基座能力已经足够强,经过垂直领域的强化训练可以达到世界顶级水平。这也印证了开源生态的核心价值——基座模型的开源不是终点,而是起点。当一个足够强的基座模型被开源后,全球开发者和企业都可以基于它构建垂直应用,而这些应用产生的数据和经验又会反哺整个生态,形成比闭源模型更强大的创新网络。
- 数据飞轮是AI产品的终极护城河,谁拥有高质量的场景数据,谁就能训练出更好的模型。这一逻辑在互联网时代已被反复验证(如Google搜索、字节推荐算法),在AI时代同样适用,只是数据的形态从点击行为变成了人机交互反馈。
对于国内的大模型公司和 AI 编程工具而言,这是一个明确的信号:基于真实用户数据的强化训练,是提升模型能力最有效的路径之一。与其在预训练阶段拼算力,不如在应用层积累数据,用数据驱动模型迭代。当前的竞争格局正在从「谁的模型参数多」转向「谁的数据飞轮转得快」,而这恰恰是拥有庞大用户基数的中国市场最有可能建立优势的方向。
核心要点
相关推荐
OpenAI o3助力波士顿儿童医院攻克罕见遗传病诊断难题
OpenAI o3助力波士顿儿童医院攻克罕见遗传病诊断难题
OpenAI o3 Deep Research模型与波士顿儿童医院合作,通过AI深度推理辅助罕见遗传病诊断,研究成果发表于NEJM AI。了解这项人机协作如何缩短诊断周期、推动精准医学发展。
Cursor是什么?AI原生编程IDE核心特性与使用场景全解析
深度解析Cursor这款AI原生编程IDE,涵盖智能代码生成、多模型支持、上下文感知等核心特性,对比传统IDE的六大优势,帮助开发者了解谁适合使用Cursor以及如何提升编程效率。

别再手写Prompt了:让AI代理自己提示自己
深度解析AI编程范式转变:从手动编写Prompt到构建代理自提示循环系统。了解如何通过代理自审代码、主动获取上下文等方法,实现规模化高质量AI编程,从Prompt工程师进阶为代理系统设计师。