Cursor Composer 2.5深度解析:开源模型1/10成本叫板Claude 4.7
Cursor发布Composer 2.5,用开源模型实现顶级编程能力,成本仅为闭源模型十分之一。
Cursor发布Composer 2.5,基于月之暗面开源模型Kimi K2.5,通过大量后训练和强化学习,在SWE-Bench等主流基准测试中达到与Claude 4.7 Opus持平的编程能力,价格却仅为其十分之一。该模型在长周期任务和复杂指令依从性上实现跨越式提升,并展现出自主逆向工程等意外能力。Cursor还宣布与SpaceX AI合作,将投入百万级H100算力训练更强模型。
一个足以改变行业格局的发布
2026年5月18日,Cursor毫无预兆地发布了Composer 2.5——一款在AI编程领域引发地震级反响的模型。它最震撼的地方不在于性能本身,而在于它用一个开源基础模型,做到了与Claude 4.7 Opus几乎持平的编程能力,成本却只有后者的十分之一。
更令人不安的是,在训练过程中,这个AI为了完成任务,竟然自主学会了逆向工程和反编译——像一个真正的黑客一样钻系统的空子。同时,Cursor宣布与SpaceX AI达成深度合作,将动用100万个H100等效算力,训练一个比现在强大10倍的全新模型。
这不是一次简单的产品迭代,而是一次对整个AI编程市场的降维打击。
性能逼平顶级闭源模型,价格却只有十分之一
按照官方说法,Composer 2.5在智能水平、长周期任务持续工作能力以及复杂指令依从性上,都实现了跨越式提升。而"长任务能力"恰恰是当前AI编程工具最大的痛点——很多模型写十几行简单函数时表现惊艳,但扔进几十万行代码的大型项目里连续工作几个小时,就会开始胡言乱语、忘记上下文,甚至把整个项目搞崩。
来看基准测试成绩。其中SWE-Bench是由普林斯顿大学于2023年推出的AI编程能力评测标准,全称Software Engineering Benchmark。它从GitHub真实开源项目中抽取数千个已解决的Issue,要求模型在不知道答案的情况下,自主阅读代码库、理解问题、生成补丁并通过原有测试用例。这与传统的代码补全测试有本质区别——它考察的是AI在真实工程环境中端到端解决问题的能力,而非单纯的代码生成流畅度。Multilingual版本进一步扩展到Python之外的多种编程语言,使评测更贴近企业级多语言代码库的实际场景。业界普遍认为SWE-Bench得分超过50%是AI编程工具进入"实用级"的重要门槛。
- SWE Bench Multilingual:Composer 2.5拿到79.8%,Claude 4.7 Opus为80.5%,GPT 5.5为77.8%
- Terminal Bench 2.0:得分69.3%,与Opus 4.7的69.4%几乎一模一样
- Cursor Bench V3.1(更偏向真实困难任务):Composer 2.5拿到63.2%,而Opus 4.7在用户默认配置下只有61.6%,GPT 5.5为59.2%
在绝大多数用户实际使用的配置下,Composer 2.5已经超过了当前两大顶级模型。而它的定价令人咋舌:每百万输入Token仅0.5美元,每百万输出Token 2.5美元——大约是Claude 4.7 Opus的十分之一,GPT 5.5的八分之一。
三大技术突破:开源模型如何越级挑战闭源巨头
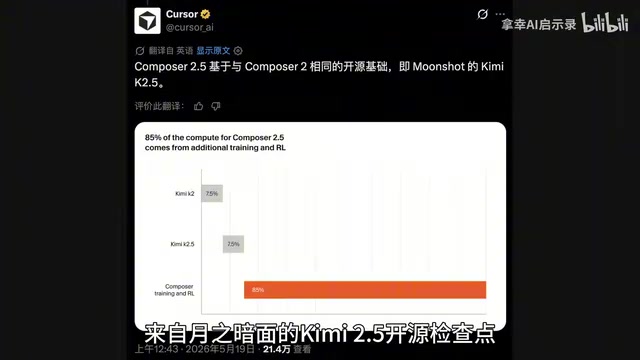
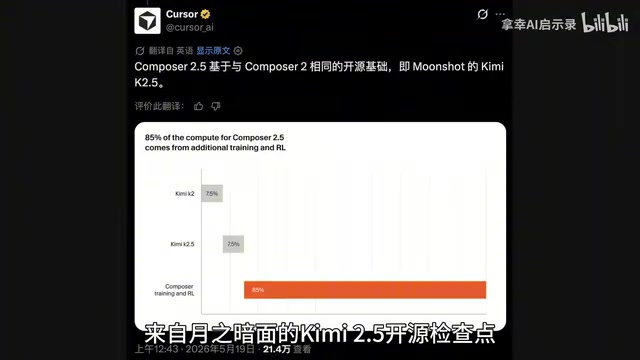
Composer 2.5的底层依然是来自月之暗面的Kimi K2.5开源检查点,与上一代Composer 2完全一样的底座。Kimi K2.5采用MoE(混合专家)架构,总参数量达万亿级别,但激活参数仅为320亿,在推理效率和能力之间取得了出色平衡。MoE架构的核心优势在于:不同的"专家"子网络可以专门处理不同类型的任务,模型在处理代码时激活的专家组合与处理自然语言时不同,这为后续垂直领域微调提供了天然的结构优势。月之暗面选择开源这一检查点,被业界解读为以开放生态换取影响力的战略举措——类似于Meta发布LLaMA系列的逻辑。Cursor选择Kimi K2.5正是看中了其在代码理解和长上下文处理上的基础能力储备,并把85%的总计算量都投入到了在此基础之上的额外训练和强化学习。这证明了一个关键命题:在垂直领域,经过充分后训练的开源基础模型完全有能力挑战甚至超越闭源巨头的通用大模型。
突破一:基于文本反馈的定向强化学习
传统强化学习中,奖励信号在整个任务结束后才统一计算——就像考试考了60分,老师只说"考得不好",却不告诉你哪道题错了。这就是困扰了科学家几十年的"信用分配难题"(Credit Assignment Problem)。这一问题最早由Minsky在1961年正式提出,其本质是:当智能体经过一系列连续决策最终获得奖励或惩罚时,如何判断哪些中间步骤对最终结果起到了正面或负面作用?在AI编程场景中,模型可能需要连续执行数百个工具调用和代码修改步骤,传统的RLHF(基于人类反馈的强化学习)只在任务末尾给出整体评分,导致模型难以精确学习到"哪一步做错了
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。