Cursor Composer 2.5深度实测:成本仅Opus十分之一,值得用吗
Cursor团队近日发布了Composer 2.5编程模型,号称性能接近Opus 4.7,但成本仅为其十分之一。这款模型在Artificial Analysis的AI编程智能体排名中位列第三,仅次于Opus 4.7和GPT 5.5。Artificial Analysis是一家独立的AI模型评测机构,专注于对大语言模型的性能、速度和成本进行标准化对比,其AI编程智能体排名综合考量了模型在代码生成、调试、重构等多个编程子任务上的表现,是业界公认的权威参考之一。该排名之所以被业界广泛认可,在于其评测方法论的科学性——与简单的代码补全准确率不同,排名模拟了真实开发者的工作流程:模型需要理解需求描述、规划实现路径、编写代码、运行测试并根据反馈迭代修复,这种端到端的评测方式更接近AI编程工具的实际使用场景,因此其排名结果对开发者的工具选型具有很高的参考价值。文中提到的Opus 4.7是Anthropic旗下Claude系列的旗舰编程模型,而GPT 5.5则是OpenAI最新一代的大语言模型,两者均代表了当前AI编程能力的天花板。它真的能媲美这些顶级模型吗?本文通过多个实际场景的深度测试,为你揭晓答案。
Composer 2.5的核心优势:每次任务仅需7美分
Composer 2.5最令人瞩目的特点是其惊人的性价比。标准版每次任务平均仅需7美分,快速模式下也只需44美分。相比之下,Opus模型每次任务需要4到5美元,GPT 5.5的相关版本价格同样高昂——两者之间的价格差距可达数十倍。
从API定价来看,标准版Composer 2.5每百万输入Token仅需50美分,每百万输出Token为2.5美元;快速版本稍贵(输入3美元/百万Token,输出15美元/百万Token),但速度更快且同样智能。这里需要解释一下Token的概念:Token是大语言模型处理文本的基本单位,大致相当于一个英文单词的四分之三或一个中文汉字。API定价通常按百万Token计费,分为输入Token(用户发送给模型的提示内容)和输出Token(模型生成的回复内容)两部分,输出Token通常更贵,因为生成过程消耗更多算力。以标准版50美分/百万输入Token的定价来算,处理一本10万字的中文技术文档仅需几美分,这在当前市场上属于极具竞争力的价格区间。
理解Token定价对开发者至关重要,因为它直接决定了项目的AI成本预算。在实际编程场景中,一次典型的代码生成任务可能涉及数千到数万Token的输入(包括系统提示、项目上下文和用户指令)和数百到数千Token的输出。以Composer 2.5标准版的定价计算,一个中等复杂度的编程任务(约5000输入Token + 2000输出Token)成本不到1美分,这使得开发者可以毫无顾忌地进行多轮迭代和实验。
更值得关注的是,在Cursor Pro订阅(每月20美元)中,用户能获得极其充裕的使用额度——测试者在录制完整个评测视频后,额度仅消耗了1%,这与使用Claude时"一次对话就耗尽额度"的体验形成了鲜明对比。
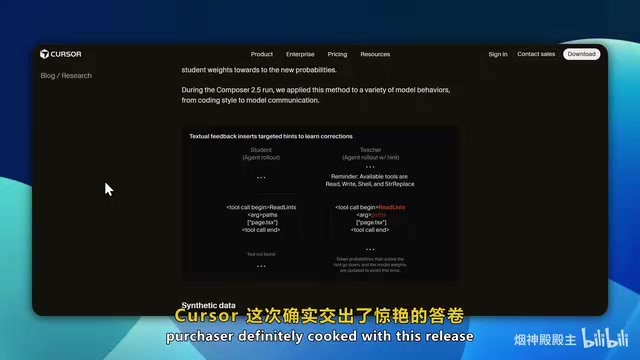
基准测试表现:多维度碾压上一代Composer 2
Composer 2.5在多个权威基准测试中表现亮眼,包括Terminal Bench 2.0、SWE-Bench、多元测试以及Cursor Bench,部分指标甚至超越了Opus和GPT 5.5,性能全面碾压上一代Composer 2。
其中,SWE-Bench是由普林斯顿大学研究团队创建的软件工程基准测试集,包含从真实GitHub仓库中提取的数千个Issue和对应的Pull Request,用于评估AI模型解决实际软件工程问题的能力。Terminal Bench则侧重于评估模型在终端环境中执行复杂多步骤任务的能力,包括文件操作、环境配置和系统调试等。这些基准测试与传统的代码补全评测不同,它们更接近真实开发场景,要求模型具备理解项目上下文、定位问题根因并生成完整修复方案的综合能力。
在综合AI基准测试排行榜上,该模型目前排名第八。从各维度来看,它在代码编写、调试以及逻辑推理能力上表现极为出色。不过在创造力维度上略显不足——这也预示了后续实测中在前端设计审美方面的短板。
说个细节,Composer 2.5基于与Composer 2相同的开源底座Kimi K2.5构建,但Cursor团队对其进行了深度训练优化,尤其解决了许多自主探索以及MCP(Model Context Protocol)的稳定性问题——这是旧版Composer用户长期诟病的痛点。
Kimi K2.5是由月之暗面(Moonshot AI)开源的大语言模型底座,具备强大的长上下文处理能力和代码理解能力。Cursor团队选择在开源底座上进行深度微调(fine-tuning),而非从零训练,这种策略大幅降低了研发成本,同时能针对编程场景进行专项优化。这一策略体现了当前AI应用层的一个重要范式:基础模型提供通用能力,应用团队通过领域特化的后训练来解锁垂直场景的最佳表现。这种分工模式类似于芯片行业的Fabless模式——设计公司专注于芯片设计,制造环节交给代工厂。在AI编程领域,这意味着Cursor无需投入数亿美元进行预训练,而是将有限资源用于收集高质量的编程偏好数据、设计奖励模型和优化智能体工作流。
而MCP(模型上下文协议)是Anthropic于2024年底推出的开放标准,旨在为AI模型提供与外部工具、数据源和开发环境交互的统一接口。在编程场景中,MCP的稳定性直接决定了AI智能体能否可靠地读取项目文件、执行终端命令和调用第三方API,此前Composer 2在这方面的不稳定表现曾严重影响用户体验,而2.5版本对此进行了重点修复。
实战测试一:macOS界面克隆
第一个测试是让模型克隆macOS界面并制作网页版系统。Composer 2.5的整体表现不错,出色地还原了几乎所有macOS功能——用户甚至能打开各种应用和文件夹,包括照片应用、备忘录、音乐软件和设置,它还额外生成了一款小游戏和终端、计算器等工具。
不过也存在明显不足:顶部状态栏无法使用,Safari浏览器界面做得一般。测试者给出了7分的评价,认为"在网页开发方面它还无法完全媲美Opus"。
实战测试二:产品落地页生成
在英伟达RTX 5090落地页的生成测试中,三款模型的差距更加直观。Composer 2.5确实能快速完成工作,生成了包含多个组件、不同动效和排版样式的基础落地页,还按要求加入了音效。
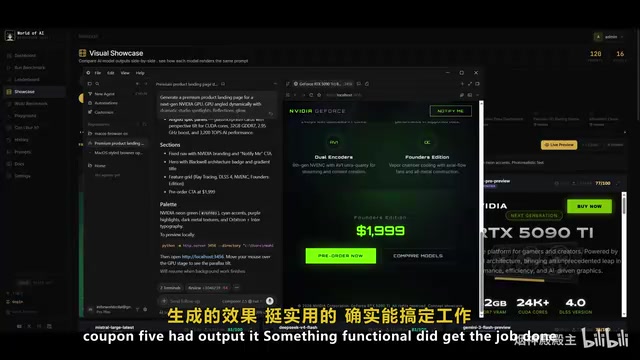
然而,将其与GPT 4.5和Opus 3.7的生成结果对比后,差距一目了然。GPT 4.5生成的英伟达显卡页面"动态效果以及整个落地页的各处细节都非常出色";Opus 3.7的效果更是"绝对惊艳",几乎所有组件完整生成且完全符合需求。Composer 2.5虽然速度更快,但在视觉质量上确实无法达到那两个模型的水平,尤其是在前端设计审美方面。
实战测试三:3D场景生成与速度优势
在3D场景生成测试中,Composer 2.5的速度优势得到了充分展现。测试者要求生成"一个精致且互动的等角透视3D温馨小屋",模型仅用约两秒钟推理思考,随后在大约10秒内就完成了整个等轴3D房间的生成——包括书架、墙上装饰画等多种物件。
这里涉及的等角透视(Isometric Projection)是一种不存在透视缩放的三维投影方式,三个坐标轴之间的夹角均为120度,常见于策略游戏和建筑可视化中。AI模型生成此类3D场景代码时,通常需要输出基于CSS 3D变换或Three.js等图形库的完整代码,难度在于模型需要在脑中维护一个三维空间模型,将家具、装饰品等物件合理地放置在正确的坐标位置,同时处理遮挡关系和阴影投射。这种空间推理能力是衡量AI编程模型综合智力的一个重要维度,因为它要求模型同时具备几何直觉和精确的数值计算能力。
在Figma文件生成测试中,模型创建了包含桥梁、城市天际线、行驶车辆、自由女神像甚至昼夜交替效果的纽约城市场景,质量"多少有点接近了Sonnet甚至Opus在某些情况下的生成水平"。而在F1赛车飘移模拟测试中,它完美呈现了环境场景,自动生成了镜头视角和各种运行逻辑。
不过,与Opus在Three.js中的输出质量对比后,两款模型之间"确实有明显的跃升"。Three.js是目前最流行的JavaScript 3D图形库,基于WebGL技术在浏览器中渲染复杂的三维场景,广泛应用于数据可视化、游戏开发和交互式网页设计。Opus在Three.js场景生成中展现出的精细度和视觉表现力,仍然是Composer 2.5目前难以企及的高度。
Composer 2.5的已知短板与使用建议
尽管表现惊艳,Composer 2.5仍存在一些值得注意的问题:
- 前端设计审美不足:在网页开发和设计质量上落后于Opus,创意表现力有限
- 执行稳定性偶有波动:有时收到指令后任务无法成功执行
- 解题思路单一:容易盲目认定一种解法,不提供利弊权衡分析
对此,测试者给出了实用建议:如果对设计质量有较高要求,可以通过提供更详细的提示词指令、输入具体的审美风格、明确开发规范和细节来弥补模型在设计方面的不足,这样依然能达到接近Opus的高水准。这种通过精细化提示词工程(Prompt Engineering)来弥补模型短板的策略,在实际开发中非常实用——本质上是将人类的设计判断力与模型的代码执行力相结合,各取所长。
总结:速度与智能的高性价比之选
Composer 2.5是一款在性价比维度上实现了突破的AI编程模型。它虽未完全达到Opus的水平,但在版本迭代、调试质量以及智能体工作流方面几乎可以与Opus不相上下。对于追求快速迭代、成本敏感的开发者而言,它无疑是当前最值得尝试的AI编程工具之一。
Cursor团队通过这次发布证明了一个重要趋势:顶级AI编程能力正在快速民主化,开发者不再需要为每次任务支付数美元的高昂成本,就能获得接近最强模型的编程体验。这一趋势的背后是开源模型生态的成熟——当高质量的开源底座(如Kimi K2.5)可以被自由获取和微调时,创业团队得以将资源集中在场景优化和用户体验上,而非基础模型的训练上,从而以远低于头部实验室的成本交付具有竞争力的产品。
AI编程能力的民主化正在重塑软件开发行业的格局。当高质量AI编程辅助的获取门槛从每月数百美元降至20美元时,独立开发者和小型创业团队获得了与大公司工程团队接近的生产力工具。这不仅加速了软件产品的交付周期,也降低了技术创业的资金门槛。但这同时也意味着竞争加剧——当工具不再是瓶颈时,产品创意、用户洞察和执行速度将成为更关键的差异化因素。
相关推荐
Hermes Desktop正式发布:永久免费的自进化AI智能体桌面版
Hermes Desktop正式发布,支持Windows、macOS和Linux全平台。这款基于MIT开源协议的AI Agent具备持久记忆、自主进化、技能管理和多平台集成能力,完全免费使用,是目前最值得关注的开源AI智能体桌面应用。

小米MIMO与华为盘古AI战略对比:Agent时代的安卓与iOS之争
小米发布开源终端AI编程助手MIMO Code,华为余承东宣布盘古大模型迈入Agent聚能体时代。深入对比两大科技巨头的AI战略路线:小米走开源生态的安卓路线,华为走垂直整合的iOS路线,解析Agent落地的关键差异。

Google WebMCP是什么?AI Agent直接调用网页功能的新标准详解
深入解析Google WebMCP(Web Model Context Protocol)的工作原理、技术实现与应用场景。了解WebMCP如何让AI Agent直接调用网页工具,告别脆弱的DOM解析和屏幕抓取方式。